前言
讀了許多理論,是時候實際動手做做看了,以下是我的模型訓練初體驗,有點糟就是了XD。
正文
def conv(filters, kernel_size, strides=1):
return Conv2D(filters,
kernel_size,
strides=strides,
padding='same',
use_bias=True,
kernel_initializer='he_normal',
kernel_regularizer=l2(0.0001))
def residual_unit(filters):
def f(x):
x_b = x
# x = BatchNormalization()(x) 2.加了似乎會過擬合
# x = Activation('relu')(x) 2.加了似乎會過擬合
x = conv(filters, 1)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = conv(filters, 3)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = conv(filters, 3)(x)
# x = BatchNormalization()(x) 2.加了似乎會過擬合
# x = Activation('relu')(x) 2.加了似乎會過擬合
x = conv(64, 1)(x)
return Add()([x, x_b])
return f
input = Input(shape=(32, 32, 3))以上是我的模型,架構參考《強化式學習:打造最強 AlphaZero 通用演算法》書中的範例,以及前面兩篇論文。
x = conv(64, 1)(input)
for i in range(3):
x = residual_unit(64)(x)
for i in range(4):
x = residual_unit(128)(x)
for i in range(6):
x = residual_unit(256)(x)
for i in range(3):
x = residual_unit(512)(x)
x = BatchNormalization()(x) # 1.沒加會訓練不起來
x = Activation('relu')(x) # 1.沒加會訓練不起來
x = GlobalAveragePooling2D()(x)
output = Dense(10, activation='softmax', kernel_regularizer=l2(0.0001))(x)
model = Model(inputs=input, outputs=output)
邊訓練會邊遇到問題而邊調整,還滿有趣的,只是要有耐心XD。上面的程式碼中標記"1."的地方,是一開始沒有加的程式行,沒加的話發現每回合的準確率(acc)都只有0.1,訓練不起來;"1."的地方加了之後有進展,也想說標記"2."的地方應該也要加,加了後觀察到驗證的acc落差的比訓練的acc有點多,應該是發生了過擬合,所以把"2."的地方又拿掉了。途中有遇到acc在回合間來回,調過learning rate後就好了。
以下是我的模型的訓練間紀錄和訓練後結果,因為那時候還沒買Colab Pro(Colab的付費方案),為了趕在時間內跑完,訓練回合只設定了20(書是設定120),而且也沒做正規化,所以跑出來的結果還滿差的,預測10個資料10個都錯XD。

前12個epoch的訓練紀錄
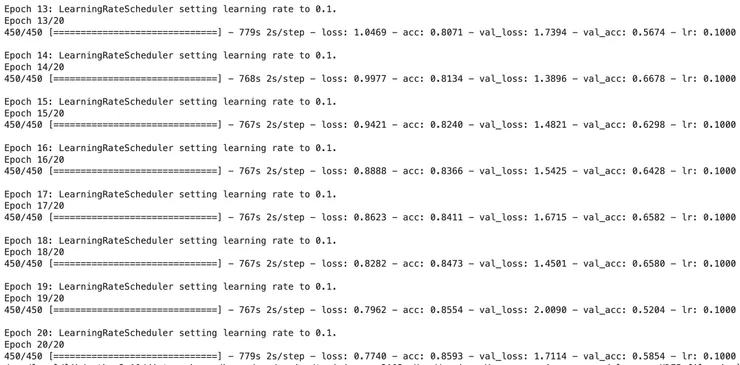
後8個epoch的訓練紀錄
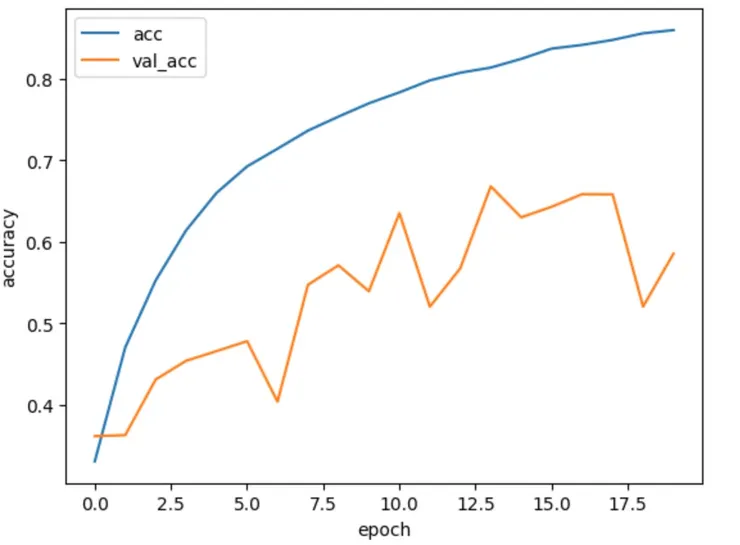
訓練準確率和驗證準確率每回合的比較圖

用測試資料測試結果模型的損失和準確

用前10筆測試資料測試結果模型,沒有一個是對的XD
第一次花四、五個小時訓練模型,雖然結果不甚滿意,但在過程中有學到東西,也算是有所收獲啦XD!
參考
- 《強化式學習:打造最強 AlphaZero 通用演算法》
小結
上一篇文章暫時被我隱藏起來了,因為發現有點問題,等確認後再發佈,跟各位說聲不好意思!繼續趕路,繼續留腳印(XD),明天台中沒放颱風假QQXD~























