
📌簡介
此篇為一份調查論文,此篇調查主要是在針對Diffusion模型利用於生成影片的任務。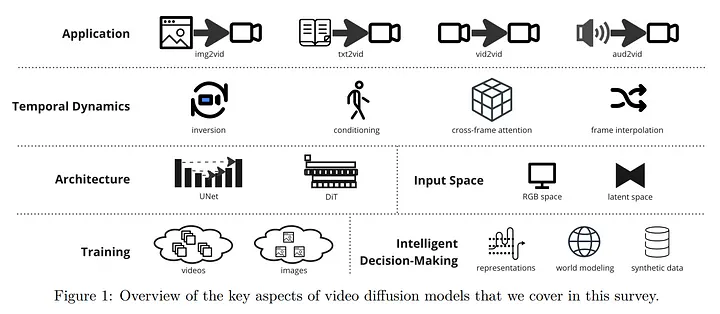
這邊作者將調查到的資訊分類出來大概有幾大類。接下來我們會跟著論文的腳步向下介紹。
📌Diffusion模型應用類型
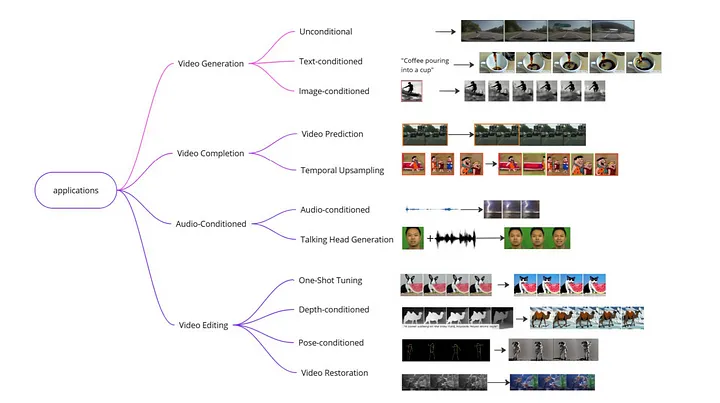
🐌文字to影片
這類型的模型大概有兩種,第一種是能產生簡單的運動(相機平移or頭髮飄動)。另一種是可以產生複雜的動作變化(ex)。
🐌圖片to影片
參考圖像進行動畫處理,有時會提供文本提示或其他引導信息。由於對生成的視頻內容具有高度可控性,這一領域最近被廣泛研究。
🐌聲音to影片
接受聲音剪輯作為輸入,有時與文本或圖像等其他模態結合。它們可以合成與聲源一致的視頻。典型應用包括生成說話的面孔、音樂視頻以及更一般的場景。
🐛影片衍生
模型將現有影片在時間域上延伸,研究團隊將其視為一個獨立的組別。
🐛影片編輯
使用現有影片作為基準,從中生成新影片。典型任務包括風格編輯、物體/背景替換、深度偽造和舊影片修復。
🐛智能決策
影像diffusion模型可以去做為真實世界的模擬器。根據代理當前狀態或任務的高層文本描述進行條件設置。這可以實現在模擬世界中進行規劃,以及在生成式世界模型中完全訓練強化學習策略。
📌Diffusion模型生成圖像架構
常見的Diffusion模型架構皆為使用像是U-Net或是Transformers,如果想要了解U-Net也可以參考我這篇筆記XD(趁機推廣🤣
🐌U-Net
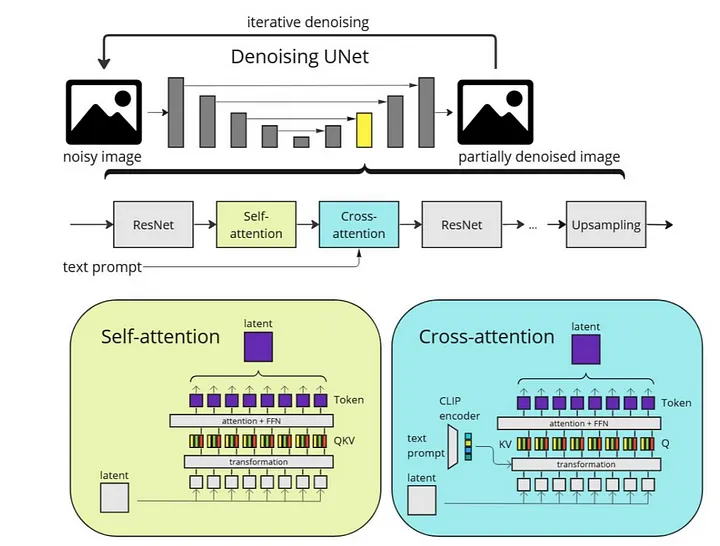
U-Net是目前再diffusion模型中一個很熱門的架構,像是之前整理過的DDPMs就是使用U-Net作為diffusion模型的解碼器,而U-Net在生成中通常為以下步驟:
(1)將輸入編碼成空間分辨率越來越低的潛在表示(2)通過固定數量的編碼層增加特徵通道數。(3)將得到的「中間」潛在表示通過相同數量的解碼層上採樣回原始大小。
在原始的UNet中只使用ResNet塊,但大多數diffusion模型在每一層中都將它們與Vision Transformer區塊交錯使用,像是上方的架構圖,ResNet區塊主要使用2D捲積,而中間可以透過Vision Transformer的自注意力機制以及交叉注意力機制,這樣的作法可以在生成的過程中根據額外信息(如文本提示和當前time steps)進行條件設置。
🐌Vision Transformer

Vision Transformer是一種基於為自然語言處理開發的變換器架構的Generate diffusion模型的重要架構。因此,它同樣結合了多頭注意力層、規範化層、殘差連接以及線性投影層,將輸入標記向量轉換為輸出標記向量。若是生成圖像Vision Transformer在生成中通常為以下步驟:
(1)圖像分割: 將輸入圖像分割成多個小塊(補丁),並為每個補丁創建嵌入表示。(2)注意力機制: 計算這些補丁之間的關係,確定哪些部分更重要(3)信息整合: 根據計算出的重要性,將各個補丁的信息組合起來。(4)輸出生成: 基於整合的信息,生成最終的輸出圖像。
純粹基於視覺變換器的擴散模型被提出作為標準UNet的替代方案。整個模型僅由一系列變換器塊組成,而不使用卷積。這種方法有明顯的優勢,如在生成視頻長度方面的靈活性。雖然基於UNet的模型通常生成固定長度的輸出序列,但變換器模型可以自回歸地預測相對任意長度序列中的標記。
🐌Cascaded Diffusion Models
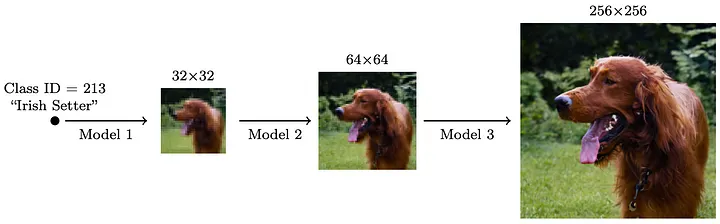
由多個在不斷增加的圖像分辨率下運作的UNet模型組成。
工作原理:(1)將一個模型的低分辨率輸出圖像進行上採樣。(2)將上採樣後的圖像作為輸入傳遞給下一個模型。(3)通過這種方式生成高保真度的圖像版本。
❗自從採用潛在擴散模型(Latent Diffusion Models)後,CDM的使用已大大減少,因為LDM允許以較少的資源原生生成高保真度圖像。
🐌Latent Diffusion Models
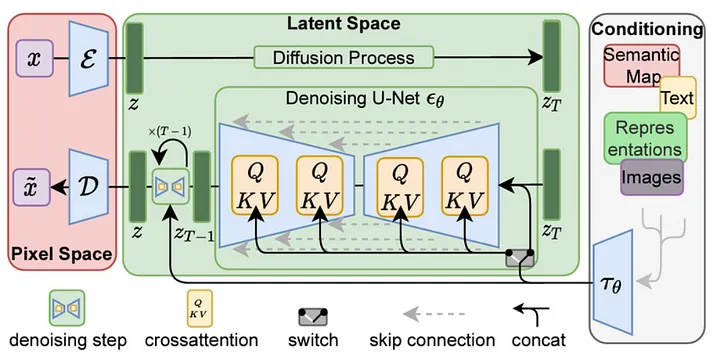
潛在擴散模型(Latent Diffusion Models)是UNet基本架構的重要發展,現已成為圖像和視頻生成任務的事實標準。若是生成圖像Vision Transformer在生成中通常為以下步驟:
(1)不在RGB空間操作,使用預訓練的向量量化變分自編碼器(VQVAE)將輸入圖像編碼為具有較低空間分辨率和更多特徵通道的潛在表示。(2)將這個低分辨率表示傳遞給UNet,整個擴散和降噪過程在VQ-VAE編碼器的潛在空間中進行。(3)然後使用VQ-VAE的解碼器部分將降噪後的潛在表示解碼回原始像素空間。
為什麼要在低維度空間中操作?主要是因為可以節省大量計算資源,另外此模型也允許生成比之前的擴散模型更高分辨率的圖像。向是我們常聽到的Stable Diffusion 1就是經典的LDM模型。
📌如何讓影片動的合理?時間動態
前面我們講解了目前生成圖像的方法,但有個挑戰就是若是單純地為每一幀生成圖像會導致缺乏空間和時間連貫性接下來我們會下去講解目前的解決方案。
🐌空間-時間注意力機制
大多數的影片Diffusion模型通常是修改了UNet 模型中的自注意層,這些層包括一個視覺變換器,用於計算圖像中某個查詢區塊與同一圖像中所有其他區塊之間的相似性。這一基本機制可以通過多種方式擴展。
- 時間注意力:關注影像中其他畫面上同一位置的區域。
- 完全時空注意力:關注所有畫面上的所有區域。
- 因果注意力:只會關注之前畫面上的區域,若為稀疏因果注意力,則只關注少數幾個之前的畫面,比如最初的和直接前一個畫面。
🐌時間上採樣
通常在單批次處理長影片往往超出當前硬件的容量。儘管已經探索了多種技術來減少計算負擔(例如稀疏因果注意力),大多數模型仍然只能在高端GPU上生成幾秒鐘長度的影片。
為了克服這一限制,許多研究採用了分層上採樣技術,這意味著我們不是一下子生成每一幀,而是先生成一些間隔比較大的主要幀,這些幀稱為“關鍵幀”。然後,我們用兩種方法來生成這些關鍵幀之間缺失的幀,也就是“中間幀”:
- 插值鄰近的關鍵幀:利用已經生成的兩個相鄰的關鍵幀,接著預測和填充它們之間的幀。
- 使用Diffusion模型進行額外的過程(基於兩個關鍵幀):根據已有的兩個關鍵幀來生成這兩幀之間的所有中間幀。可以更真實地再現中間的動作。
🐌結構保留
面對兩個相對立的目標:一方面要保持原始視頻的基本結構不變,另一方面又希望加入一些新的變化。如果過分堅持原視頻的結構,可能會限制模型進行編輯的能力;但如果改變太大,則可能損害視頻的空間和時間連貫性,導致生成的結果在空間和時間上看起來不自然。
為了保持輸入視頻的大致結構,一個常見的方法是通過調整每個輸入幀添加的噪聲量,使用者可以控制輸出視頻應該有多接近原始視頻,或者在編輯時應該有多大的自由度。
不過實際上,這種方法本身不足以保持輸入視頻的更細微的結構,因此通常會與其他技術結合使用。

而這些缺點可以通過在去噪過程中增加對原始影片中提取的空間線索的條件限制來一定程度上緩解。像是上方的例子。這類型的工具有像是ControlNet
那什麼是ControlNet呢?接下來我們來詳細講講。
ControlNet

ControlNet 是一種擴展工具,用於提高穩定擴散模型的功能。它允許模型在處理圖像時考慮更多的資料,像是深度圖(可以測量物體距離的圖像)、OpenPose骨架(人體動作的骨架圖)、或線稿(基本的輪廓繪圖)。
ControlNet 模型本質上是對StableDiffusion模型中去噪UNet的編碼器進行了特殊調整。這意味著它可以和原來的穩定擴散模型配合使用,增強其性能。
具體怎麼運作的呢?
(1)圖像特徵首先被一個預處理器提取出來(2)通過一個專門設計的編碼器進行編碼(2)編碼透過ControlNet進一步處理,最終和圖像的潛在特徵(這些特徵代表了圖像的基本資訊和細節)結合。
這個結合的過程有助於在去噪過程中更好地控制圖像的品和細節。
📌模型該如何訓練呢?
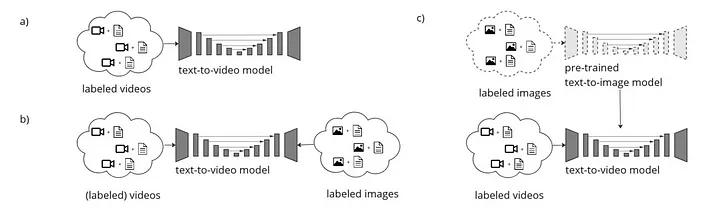
🐌從頭開始訓練
模型從零開始訓練,不依賴任何預訓練的模型。這種方法可以讓模型完全適應特定的影片數據集特點,但訓練過程可能需要較長時間和更大的數據量。
🐌基於預訓練圖像模型的訓練
這種策略利用已經訓練好的圖像生成模型作為基礎,然後在此基礎上進行微調以適應影片數據。這可以加快訓練速度並提高模型的穩定性,因為模型不需要從零開始學習所有特徵。
🐌結合影片和圖像數據的訓練
在這種方法中,模型同時使用影片和圖像數據進行訓練。這允許模型學習更多的視覺概念和文本關聯,並改善對視頻內容的理解和生成。
🐌時間上的條件約束
重點在於讓模型學習如何處理和生成在時間上連貫的影片。在實際操作中,這意味著在訓練模型時,會給模型展示一系列連續的影片幀(就像一連串的照片一樣)。模型通過這些連續幀學習視頻中物體或場景如何隨時間變化,比如一個人如何從走路過渡到跑步,或者一朵雲如何在風中逐漸變形。
這樣做的好處是,當模型生成新的影片時,它能夠創造出在時間上更加自然和流暢的畫面。這就像是讓模型不僅知道每一幀應該顯示什麼,還要知道這些幀是如何連接起來的。
🐌標籤和文本提示的使用
通過明確的說明來增強模型對影片內容理解的方法。這種訓練方法使模型能夠學習特定的文本提示與視頻內容之間的關聯。當模型在未來生成影片時,它可以更準確地根據用戶的文本指令創造相應的內容。
📌影像資料集來源
🐌影片資料集
WebVid-10M (2021)
這是一個大型數據集,包括從網絡收集的1070萬個影片剪輯,總時長約為52,000小時。這些視頻都配有HTML Alt-text,以方便視障用戶使用。這個數據集因其內容的多樣性和視頻的高解析度而特別有用。
HD-Villa-100M (2022)
包含從YouTube提取的超過1億個短影音剪輯,總時長約為371,000小時。每個剪輯都是高清的(1280×720像素)並配有自動文本轉錄,使這個數據集非常適合訓練生成式視頻模型
Kinetics-600 (2018)
包含YouTube上的500,000個短影音剪輯,展示600種不同的人類動作。每個影片大約10秒鐘,為專注於人類活動的模型提供了豐富的動作特定內容。
UCF101 (2012)
包含來自YouTube的超過13,000個影像剪輯,總時長為27小時,每個剪輯持續約7秒。此數據集將影像分類為101種動作類別,如運動和演奏樂器,是動作識別訓練的主要數據集。
MSR-VTT (2016)
包括總時長為41小時的10,000個影像剪輯,這些影像來自於超過7,000個不同的視頻。這些剪輯由人工用短文本描述標註,使得該數據集對於文本到影像的應用非常有價值。
Sky Time-lapse (2018)
包含在各種條件下拍攝的天空的時間推移剪輯,適用於研究如雲層運動等複雜運動模式的再現。
Tai-Chi-HD (2019)
包含來自280個太極YouTube視頻的超過3,000個影片,適用於研究運動和預測武術及類似活動中的動作。
TikTok Dataset (2022)
專注於舞蹈,包含約350個TikTok舞蹈挑戰影片,每個影片持續10到15秒。該數據集中的影片捕捉了個體表演的舞蹈動作,展示了適度的運動而無明顯的運動模糊。
🐌圖片資料集
ImageNet (2015)
ImageNet是為ImageNet大規模視覺識別挑戰而開發的數據集,該挑戰於2010年至2017年間每年舉行。自2012年起,此數據集被用於主要的圖像分類任務。ImageNet-21k包含超過1400萬張圖片,這些圖片由人工標記了一個物體類別標籤,總共有20,000個不同的物體類別,這些類別按照WordNet的結構進行層次性組織。ImageNet-1k是這個數據集的一個子集,用於ImageNet競賽本身,包含超過100萬張圖片,每張圖片都有一個物體類別標籤和相應的邊界框。
MS-COCO (2014)
最初開發為物體定位模型的基準數據集。它包含超過300,000張圖片,這些圖片包含91個不同類別的日常物體。每個物體實例都被標記了一個分割掩模和相應的類別標籤。總共大約有250萬個物體實例。
LAION-5B (2022)
一個非常大的公共收藏,包含5.58億個在網上找到的文本-圖像對。這些對通過預訓練的CLIP模型進行編碼,並篩選出餘弦相似度低的對。用於訓練圖像或視頻模型的通常是包含英文標題的LAION-5B的子集,稱為LAION-2B,包含2.32億個文本-圖像對。此外,基於自動分類提供了不適合工作場所(NSFW)、有水印或有毒內容的標籤。LAION-5B數據集的策劃水平相對較低,但其龐大的規模對於訓練大型圖像和視頻模型非常有價值。
📌參考資料
https://arxiv.org/abs/2405.03150






















