
Google於2025年3 月12日推出改變高效AI門檻的開源模型 Gemma 3不到一個禮拜,Mistral AI 立刻於3月18日推出開源模型 Mistral Small 3.1 ,以其 240億(24B)參數的輕量化設計再度震撼大家。這款開源模型不僅在性能上超越了 Google的 Gemma 3(27 B)、OpenAI 的 GPT-4o Mini 和 Anthropic 的 Claude 3.5 Haiku 等更大規模的競爭對手,還能在消費級硬體上高效運行,例如單張 Nvidia RTX 4090 GPU 或配備 32 GB RAM 的 Mac!
Mistral Small 3.1 的核心亮點
Mistral Small 3.1擁有 128,000個 Token的上下文窗口,遠超同級模型常見的 8,000-32,000 Token限制。這使其在處理長篇文本、複雜文檔分析或延長對話時表現出色。其次,該模型同樣支援多模態功能,能同時處理文字與圖像,適用於圖表解讀、文檔理解等場景。此外,其推理速度高達每秒 150個Token,非常適合低延遲應用,如聊天機器人或即時問題解答。
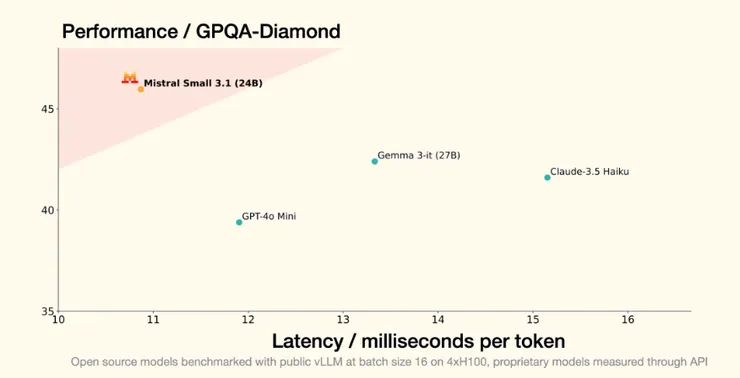
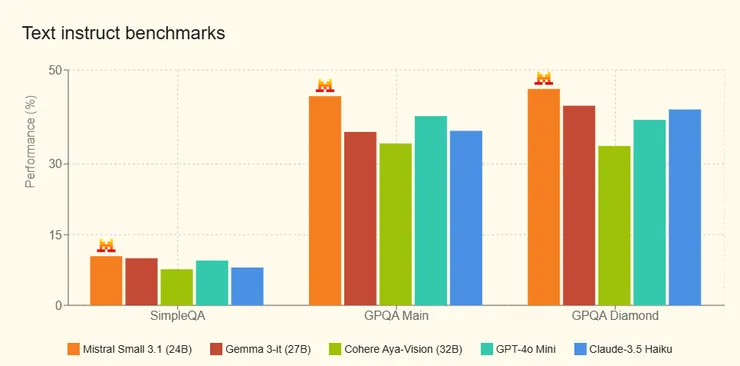
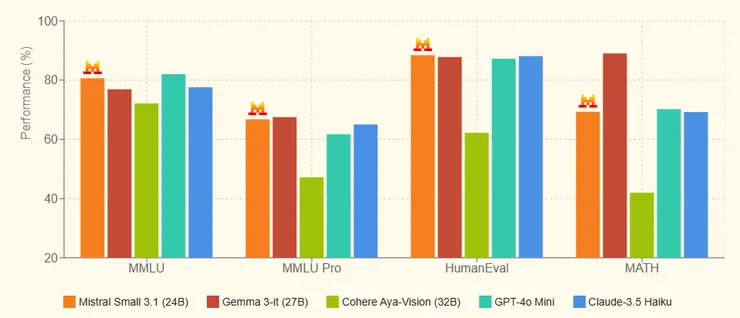
在基準測試中,Mistral Small 3.1 的表現令人驚艷。它在 GPQA Diamond(研究生級科學推理測試)中得分 45.96%,超越 Gemma 3的 42.40%;在 HumanEval 程式碼生成測試中得分 88.41%,略勝 Gemma 3的 87.80%;而在視覺任務如 ChartQA(圖表問答)和 DocVQA(文檔問答)中分別達到 86.24% 和 94.08%,大幅領先 Gemma 3 的 78.00% 和 86.60%。可見Mistral Small 3.1 在多個領域都能與更大模型抗衡,甚至更勝一籌。
開源生態與應用前景
Mistral Small 3.1 在 Apache 2.0 許可證下發佈,為開發者提供了廣闊的客製化空間。無論是透過 Hugging Face 下載原始模型,還是等待即將推出的社區量化版本(如 GGUF 或 MLX 量化格式),這款模型的開放性使其能快速適應特定領域需求,例如醫療、教育或金融分析。此外,Mistral 的 La Plateforme API 進一步降低了使用門檻,讓企業與個人能輕鬆整合這款高效 AI。
Mistral Small 3.1 的輕量化設計,結合多模態能力、超大上下文窗口與高效推理速度,僅僅在Google推出Gemma 3的一周內,又為開源AI模型定義了更高的標準。隨著後續開源社區支持的增強與應用場景的拓展,Mistral Small 3.1 絕對有機會成為 2025 年開源AI模型關鍵參與者之一。
我是TN科技筆記,如果喜歡這篇文章,歡迎留言、點選愛心、轉發給我支持鼓勵~
也歡迎每個月請我喝杯咖啡,鼓勵我撰寫更多科技文章,一起跟著科技浪潮前進!!
>>>請我喝一杯咖啡



























