大家都知道,訓練一個完整的模型需要上萬筆資料,而資料的取得往往是最令人頭痛的地方
在知道如何下載前,先來談談「資料集 (Dataset)」這個東西
資料集
顧名思義,資料集就是指資料的集合,而且最重要的是要能在電腦中處理資料集中的值可以是數字,例如實數或整數,例如身高、血壓...,也可以是標稱資料(即並非數值的數據),例如種族、血型...
而不管是自然語言處理,甚至是深度學習,在訓練和測試都需要用到大量的資料,而這些資料要從哪來呢?別擔心,貼心的 Hugging Face 已經準備好破萬個資料集了

Datasets
是 Hugging Face 提供的高效資料處理套件,專為機器學習與自然語言處理 (NLP) 設計,支援快速下載、處理、過濾、轉換、分批與共享資料集
決定下載之前,你可以先在 Hugging Face 網站上物色符合需求的資料集
https://huggingface.co/datasets
(眼花撩亂不知道要選什麼的話,可以請 GPT 列出幾個)
先用一個比較小的資料集 poem_sentiment 實做看看吧!
下載 Datasets
首先要去終端機下載 datasets
pip install datasets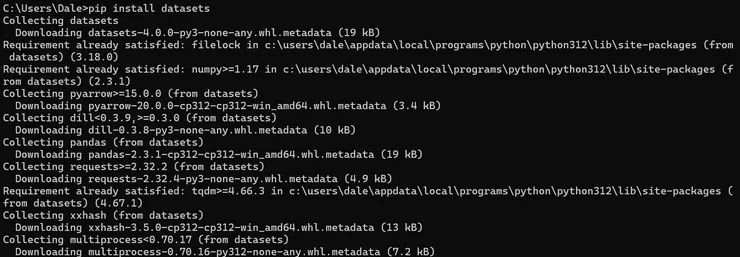
檢查資料集內容
from datasets import load_dataset_builder
builder = load_dataset_builder("poem_sentiment")
print(builder.info.dataset_size) # 60197
print(builder.info.dataset_name) # poem_sentiment
print(builder.info.features) # {'id': Value('int32'), 'verse_text': Value('string'), 'label': ClassLabel(names=['negative', 'positive', 'no_impact', 'mixed'])}
load_dataset_builder 只是看一下資料集的資訊,並不會把它下載下來
直接下載 Hugging Face 資料集
from datasets import load_dataset
dataset = load_dataset("poem_sentiment")
print(dataset)
# DatasetDict({
# train: Dataset({
# features: ['id', 'verse_text', 'label'],
# num_rows: 892
# })
# validation: Dataset({
# features: ['id', 'verse_text', 'label'],
# num_rows: 105
# })
# test: Dataset({
# features: ['id', 'verse_text', 'label'],
# num_rows: 104
# })
# })
下載遠端資料
from datasets import load_dataset
url = "https://raw.githubusercontent.com/Dale-0615/i_have_no_idea/main/example.txt"
dataset = load_dataset('text', data_files=url)
print(dataset['train'][0])
# {'text': 'It is just an example.'}
順帶一提,如果是 JSON、CSV、或 JSONL 格式,可以使用:
load_dataset("json", data_files=url)
load_dataset("csv", data_files=url)
下載本地資料
from datasets import load_dataset
dataset = load_dataset('text', data_files="C:/Users/Dale/Downloads/example.txt")
print(dataset['train'][0])
只要換成本地的檔案路徑就可以囉!
參考資料























