這個星期的大語言模型(Large Language Model, LLM)課堂講的主題是RAG,檢索增強生成(Retrieval-Augmented Generation, RAG),這個主題算是2024年在談大語言模型的時候很常談到的一個概念。從2023年底ChatGPT的發布,大眾對於AI聊天機器人的認識已經越來越深,但隨著互動的增加,也發現到大語言模型時常會有「幻覺(hallucination)」的產生,並且由於訓練資料已經固定,沒有辦法回答最新的問題,所以為了擴大LLM的使用情境,使用了RAG來強化大語言模型應用程式的效能。
我們希望AI提供什麼樣的資訊?
讓AI不要有幻覺:使用RAG
最開始ChatGPT等LLM模型剛開始發展的時候,LLM還侷限在沒有辦法有效的解決含有數學式子、具有領域知識等具有特定脈絡的問題。在這樣的脈絡之下,透過檢索增強生成(RAG)的技術,可以透過提供外部知識文件(External Knowlegdge Documents)來作為LLM可以參考的資料,讓使用者的問題(query)和外部文件一起作為LLM的Prompt被LLM理解之後,生成出回答。RAG架構的核心就是Retrieval 和 Generate,在Rothman(2024)介紹RAG技術的書中,提到了一個比喻。想像你今天想知道一個問題,要去圖書館找答案,你去書架上找到了與該問題相關的幾本書,然後你找到了一個座位坐下,開始閱讀、做筆記,最後找出解答。圖書館本身可以想像成RAG的知識庫(knowledge base),從書架上拿了幾本書的過程就是Retrieval,在座位上閱讀、做筆記的過程就是Generate。
而優化RAG技術的方法有很多,其中一個方法就是Rerank,將已經變成片段塊狀的文本脈絡重新進行排序,選出與使用者問題(user query)最具有相關的文本。而為了不要讓經過rerank的文本和原本使用者問題所加起來的tokens數太多,以至於餵給LLM的時候有太多冗餘的資訊影響了最後產出,所以選擇要排行到多少名的文本,提供多少文字量,如何做更好的減省等等,都是rerank的課題。若回到圖書館的比喻來說,優化RAG的方法就是讓在找到書之後,可以重新排序最幾個書頁當中最有用的資訊,然後用來生成筆記。
RAG的使用情境,核心的關鍵之一在於外部知識文件,但與其說是「外部」,對於企業、組織來說,其實是內部文件,也就是對於LLM原始的訓練模型來講是外部,專屬於組織特定的領域知識。這就好像讓LLM可以「開書考」,若LLM的使用情境僅在於企業內部本身,且企業內部本身的文件資料又常常需要彈性調整範圍,那麼就很適合使用RAG導入到LLM的應用程式當中,來作為其中一個企業的知識大腦。
而通常這樣的LLM應用程式,在進行與使用者的問答時,往往也都會在回應當中,提供所擷取的文本來源供使用者參考,而這樣的作法就像人類學者寫論文一樣,在發表相關看法與論點的時候,若是來自於其他的研究,也會寫出引用來源,確保論證的可信度,並且也守護學術倫理。
當AI只引用單一參考來源時
AI Chatbot和搜尋引擎(search engine)有什麼差別
如果沒有相關的知識庫,但是又希望提升AI chatbot回答問題時的可靠性,現在很常見的一個做法就是串接搜尋引擎的API來協助AI可以不要只靠原本的training來進行回答。這樣的想法理論上認為AI chatbot的training 完成的是它自然語言生成的部分,所以它能夠像人一樣說話,但為了避免它總是不停地說出「像人話一樣的廢話」,所以希望它可以借助搜尋引擎的力量,來減少它的幻覺產生。
於是,2025年的現在,多數常見的AI chatbot,例如ChatGPT、Gemini、Copilot等等,在使用者問它們需要提供資訊的問題時,它們的回答常常會使用搜尋引擎,然後在回答問題的同時,也提供出網址,讓使用者可以進一步的去查詢資料。
有人說,現在人有問題,不需要去「Google」搜尋,現在流行的講法是,「去問ChatGPT」。
於是我進行了相關測試:
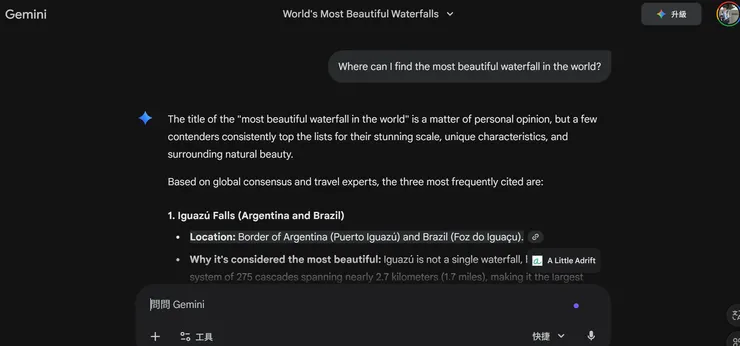
問Gemini「「請問世界上最美的瀑布在哪裡」」
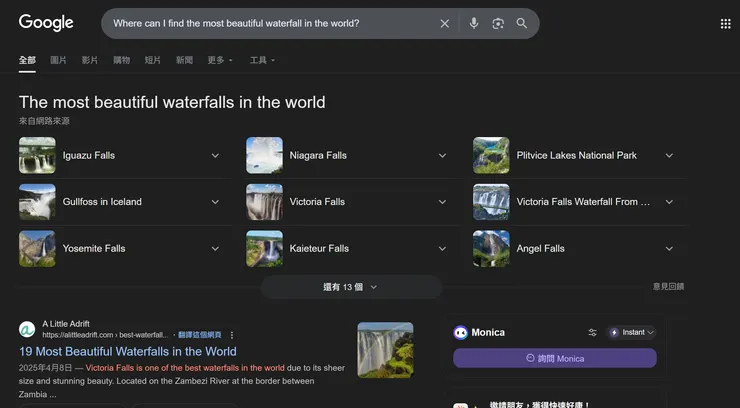
Google搜尋「請問世界上最美的瀑布在哪裡」
為了確保背後的模型機制差不多,所以我問了Google搜尋引擎和Google Gemini同樣的題目:「請問世界上最美的瀑布在哪裡」。Gemini給我的答案是Iguazu瀑布,和搜尋引擎相同,而且搜尋引擎所提供的第一個答案,也是Iguazu瀑布,然後第一個網站,和Gemini引用的連結,是同一個網站。
這個問題也是我隨意在亂聽podcast的時候聽到的雜談中的一個觀點:如果AI的回答跟搜尋到的結果一樣,那我們為什麼還需要AI呢?
當然,我問這個瀑布問題,也許太簡單了,但假設它只能整理單一文件,沒有辦法融會貫通,那麼問AI問題就彷彿是使用Google好手氣一樣,我們只是換了一個會說人話的搜尋引擎。
人類的強項或許仍然是「讀書破萬卷,下筆如有神」
其實我自己也沒有明確的答案,我在大語言模型的課堂中,總是不停地強調,不管什麼樣的開發,終歸都還是要取決於應用情境(scenario),才能決定要怎麼安排整個應用程式開發的細節架構。講完RAG之後,我也提出了一個疑問。
我們希望AI講的話具有可靠度,但我們又希望它能幫助人類消化大量的資料來提供見解。所以我們到底怎麼設計出一個讓人想用而且覺得好用的AI呢?
畢竟現實的侷限仍然卡在單次的token數還是有極限,回到圖書館的比喻,感覺上AI還是只能像人一樣,為了得到正確性,仍然只能讓它找到特定幾本書之後回答,而不是一次從好幾十甚至幾百本書來整理出答案。
那麼,從這個角度來看,能夠讀書破萬卷,能融會貫通,產出知識,甚至能夠靈活掌握已知領域知識來對付新問題的學者,還是頗有超越AI的價值吧。
那麼我繼續認真讀論文吧

Reference
Denis Rothman, RAG-Driven Generative AI: Build custom retrieval augmented generation pipelines with LlamaIndex, Deep Lake, and Pinecone , Packt Publishing, 2024.














