前情提要:
市面上有幾款免費開源的記憶體工具,Ex: Volatility、Bulk Extractor等等
有時候在幫客戶分析記憶體時,想看證據映像檔的封包時,可以使用Bulk Extractor提取pcap檔案
是相當方便且建議大家一定要認識的鑑識工具
在安裝Bulk Extractor前,請大家先下載Java,以免於安裝過程中跳出報錯訊息喔!!!
下載網址: https://downloads.digitalcorpora.org/downloads/bulk_extractor/
來簡單介紹一下Bulk Extractor這套記憶體分析工具,它是一個從記憶體提取檔案,進行人工檔案(Artifact)分析的一套工具
它可以呈現記憶體內的 "電子信箱帳號"、"信用卡號碼"、"網址"、"網域域名"、"使用者"等等資訊
簡單來說,可以查看證物本機先前所瀏覽的網頁,下載哪些東西,在數位鑑識中佔重要的一環這邊節錄 Bulk Extractor詳細定義,資料來源參考 bulk extractor 1.4 - USER MANUAL - March 23, 2015 (https://digitalcorpora.s3.amazonaws.com/downloads/bulk_extractor/BEUsersManual.pdf)
bulk_extractor operates on disk images, files or a directory of files and extracts useful information without parsing the file system or file system structures. The input is
split into pages and processed by one or more scanners. The results are stored in feature files that can be easily inspected, parsed, or processed with other automated tools.
bulk_extractor also creates histograms of features that it finds. This is useful because
features such as email addresses and internet search terms that are more common tend
to be important.
以下操作會於Windows進行,請先安裝bulk extractor
安裝後的執行檔案圖片

開啟Bulk Extractor Viewer
到上方工具列,選擇 "Tools" ,並點選 "Run bulk_extractor..."
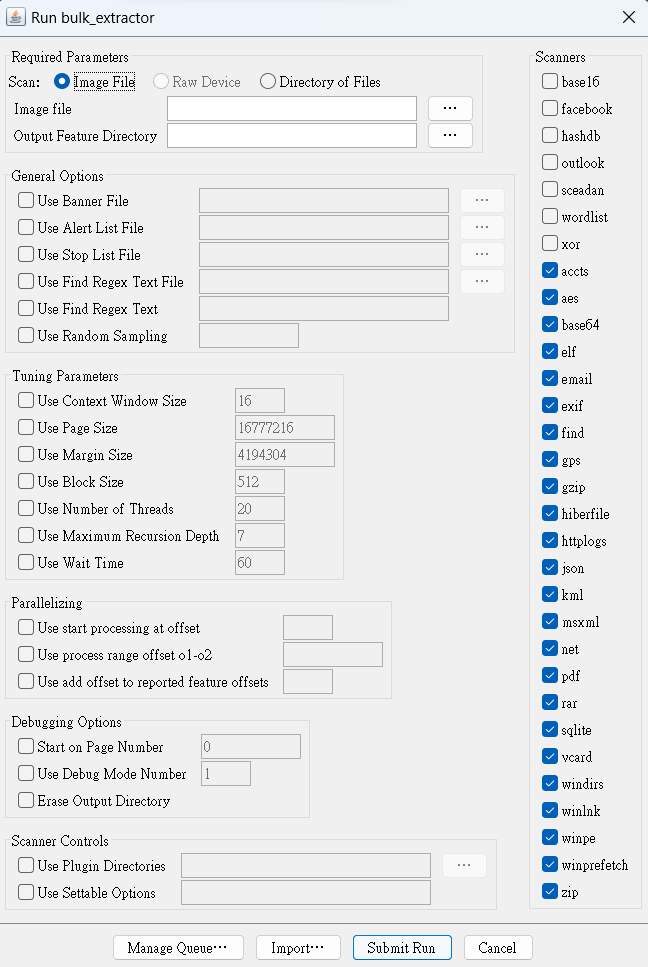
選擇 "Scan: Image File",於 "Image file" 欄位,選擇製作好的記憶體檔案(副檔名為:mem),本畫面使用dmp檔案作範例
"Output Feature Directory" 選擇輸出結果資料夾位置(可以於桌面創一個資料夾)選擇完畢後,於視窗下方按下 "Submit Run" 即可進行記憶體分析
選擇完畢後,於視窗下方按下 "Submit Run" 即可進行記憶體分析


bulk extractor跑完結果圖
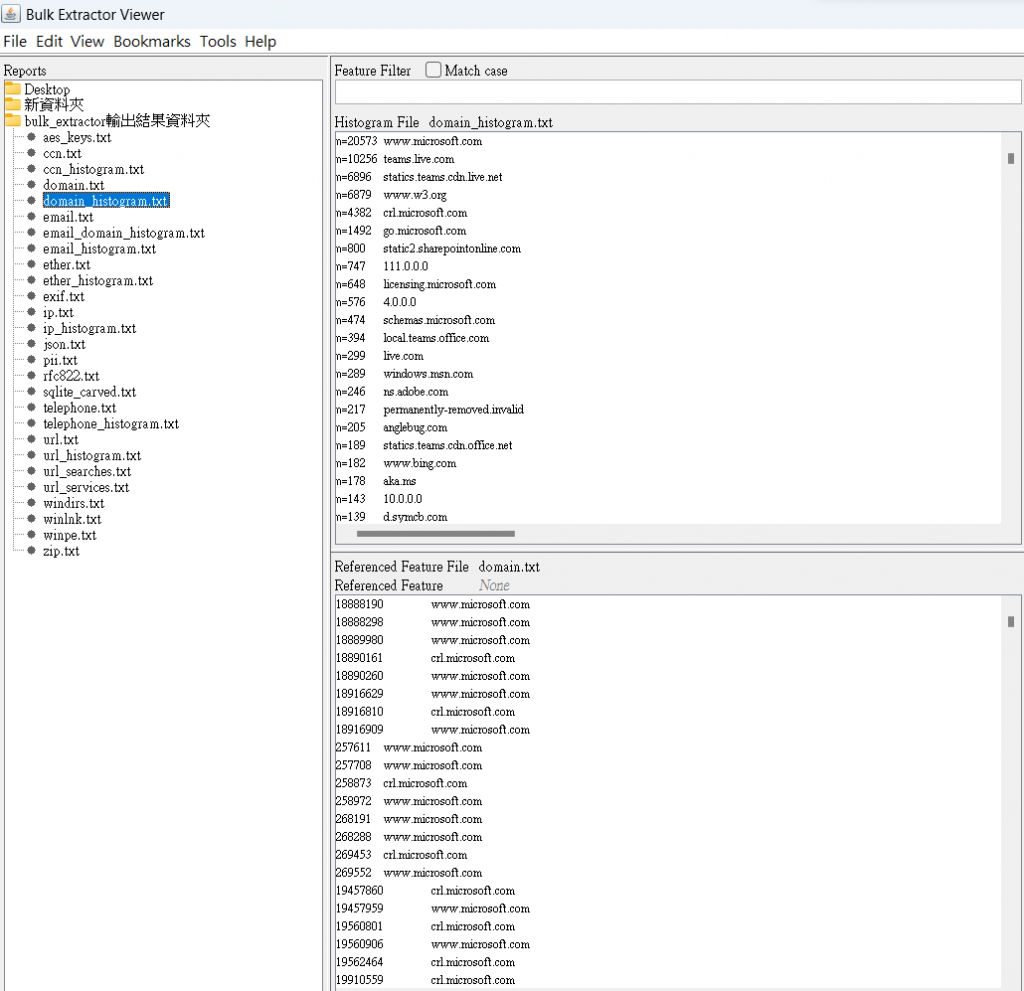
本畫面的樣本含有惡意程式片段(Ransomware),可以從bulk extractor分析畫面中看出

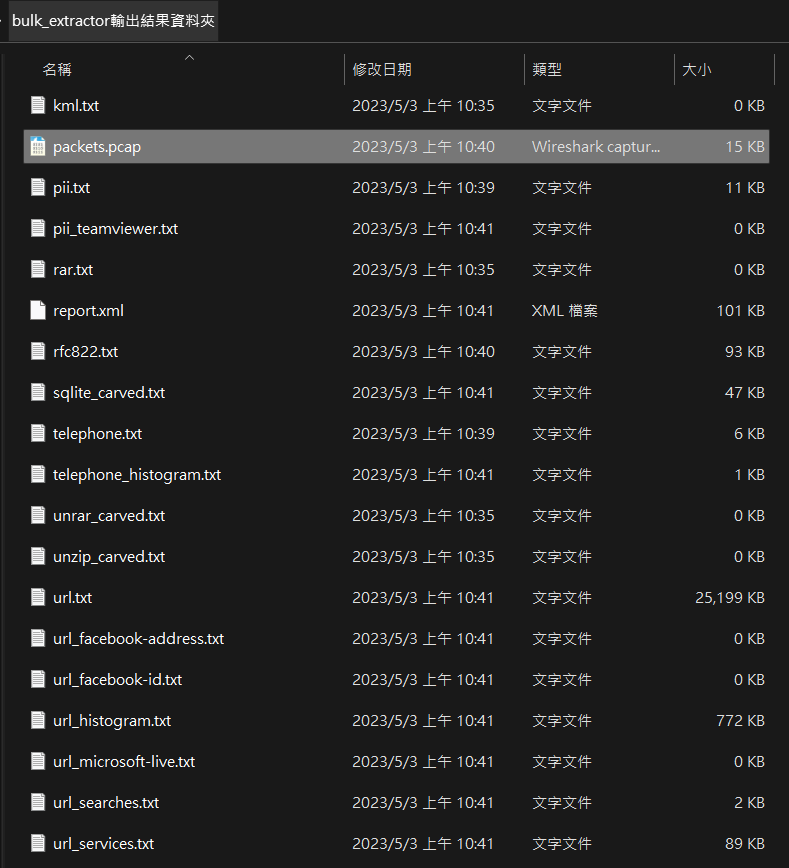
bulk extractor 分析結果輸出資料夾中,含有分析的pcap檔案
以上就是今天的記憶體鑑識工具分享,大家可多多利用此工具分析!!!





















