上週特斯拉股價終於突破新高,往900大關邁進,恭喜所有大股東小股東奈米股東們,但我們也不能因為特斯拉目前的成功而自滿,在自動駕駛道路上有許多競爭對手相繼出爐,這一系列的文章主要是針對特斯拉自動駕駛技術的科普,我們根據特斯拉2021 AI day和特斯拉AI總監Andrej Karpathy(以下簡稱AK)在CVPR大會(頂尖電腦視覺演討會)和ScaledML(機器學習大會)上的演講,為大家整理並深入淺出介紹特斯拉自動駕駛背後的秘密!
首先在講特斯拉自動駕駛之前,我們要先知道,要完成自動駕駛解決方案,一個核心的概念就是獲取深度資訊,一般我們人在開車的時候,我們的兩隻眼睛就是一個測深度的工具,兩隻眼睛因為有瞳距,所以我們可以利用雙目視覺(stereo vision)的方式,計算出與前車(人)的距離(詳細的計算之後會提到),所以要完成自動駕駛必須先獲取深度!那目前主流的兩大自動駕駛解決方案(獲取深度的方法)分別為:
光達LiDAR (Light Detection And Ranging) :包含Google waymo、奧迪、華為和小鵬等等…
偽光達Pseudo-LiDAR:包含特斯拉和Intel mobileye等等…
接下來大家就跟著阿財,一步步的進入特斯拉自動駕駛的世界,看看這個充滿爭議但卻引領世界的企業是怎麼實現他們心目中的自駕車。
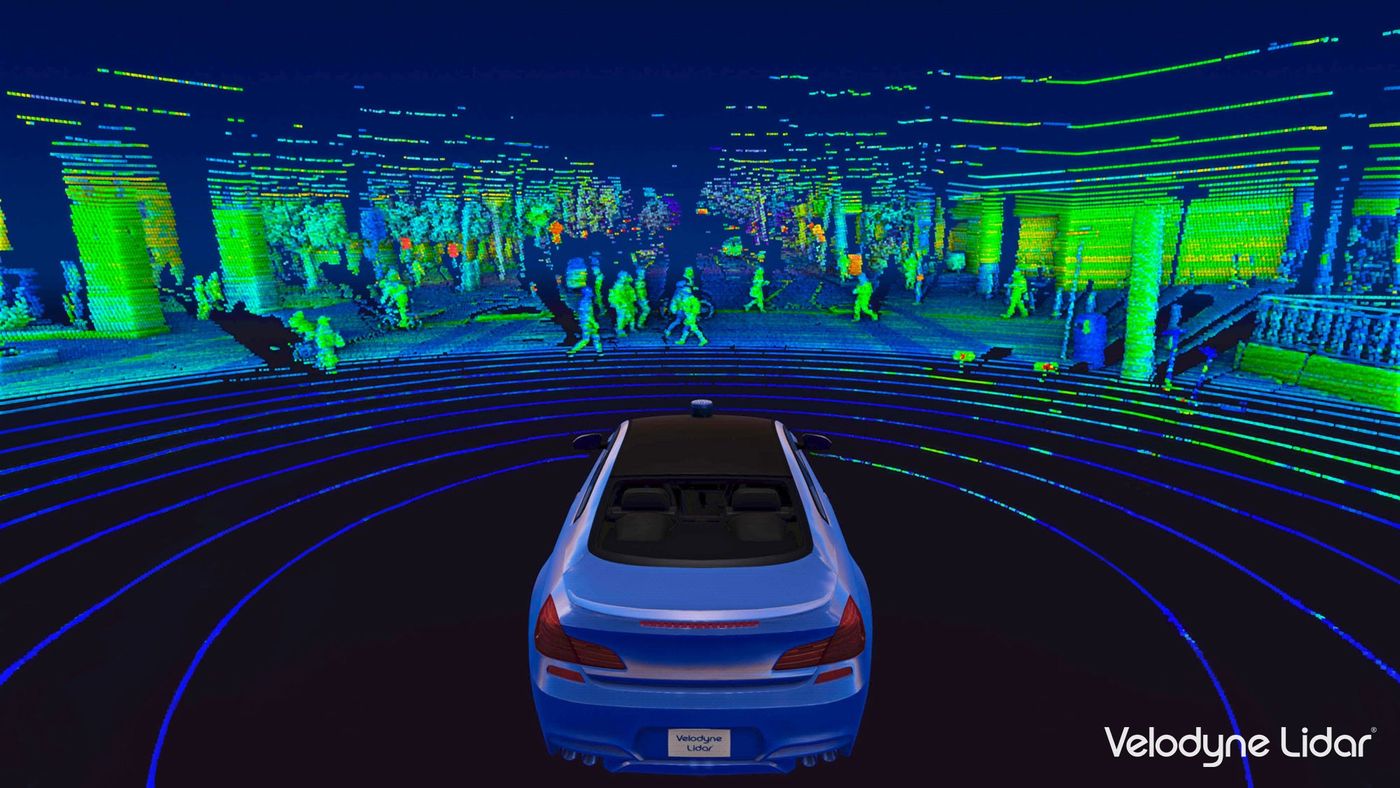
我們都知道馬斯克在很早之前就放棄使用光達,他覺得光達又貴又醜,所以特斯拉一直致力於自動駕駛視覺的解決方案,並且在2021年5月更宣布連原本車上配有的雷達,他們都要拿掉,實現真正意義上的純視覺。
那要實現純視覺,一定脫離不開相機,所以我們簡單看一下特斯拉車上的相機配置情形:

我們人類駕駛,使用眼睛感知周圍環境,而特斯拉的自動駕駛就要靠相機來獲取外界的資訊,根據特斯拉官網公布的,特斯拉總共有8台相機,每台相機的工作距離都略有不同,車身周圍還有12台超音波傳感器,這些就構建了車子360度的感知系統,在今年特斯拉AI day中AK也將相機與人眼作類比:
物體經過人眼成像在視網膜<==>物體經過相機鏡頭成像在感光元件上

人腦會將看到的物體計算深度並且判斷是什麼物體,而相機拍到的影像也會經過特斯拉的AI模型計算深度並且分類,至此特斯拉的AI就悄悄地展開了…
大家如果有follow特斯拉AI day的影片,主要分成四個部分:
自動駕駛-算法的演進
自動駕駛-路徑的選擇
自研晶片和超級電腦
特斯拉機器人
撇除掉機器人的部分,阿財其實在YouTube上有一系列的硬核影片,有興趣的朋友在延伸閱讀那兒有連結大家可以參考喔~當然方格子上的文章會更科普向一點,主要是紀錄阿財一路上研究的東西並且練習用最淺顯易懂的語言分享給大家。
回到正題,特斯拉是如何訓練他們的AI模型,我會從AK在AI day的部分為主軸,現在特斯拉有一堆解析度為1280x960的圖片和影片,這時候大家就會直覺想到,把這些東西丟進神經網絡裡面訓練學習,這時候會遇到兩個問題:
1. 你想學到什麼?
2. 學到的模型夠用嗎?
針對第一個問題,大家很直觀的會想聯想到,我想學深度資訊,也就是一張照片進來,我想知道照片中的是車子離我有多遠?
這個問題看似簡單,但其實要讓AI學起來十足的困難,首先第一點就是特斯拉每天有數百萬輛車在街道上蒐集圖片,這麼龐大數量的資料...
我們要用多深多大的網絡去訓練它?
這些網絡裡面的參數又要如何決定?
神經網絡怎麼知道圖片裡有車子和行人等物件...?
所以一個簡單的問題又分出數個問題,工程就是不斷提出問題並解決問題,首先這邊要顛覆大家一個概念,許多朋友沒有學過AI相關的課程,但卻多少有聽過神經網絡,大家會很自然地會覺得,神經網絡深度越深它的效果應該要是越好!
但微軟的團隊在2016年做了一個實驗,如下圖他們將同一筆資料丟進兩個不同深度的網絡去訓練,但我們可以發現到,不管是在訓練集裡面的誤差,還是在測試集裡面的誤差,淺層的網絡(20層)都比深層網絡(56層)要好,有沒有令大家覺得不可思議?作者也給出可能的原因,就是當我們在訓練每一層網絡的時候,都會有一些訊息丟失掉,所以當網絡越來越深,也就意味著丟失掉的訊息越來越多,就可能造成神經網絡的退化。
那如何解決,就是使用大名鼎鼎的殘差網絡(Residual neural network (ResNet)),ResNet想解決的問題很簡單,就是我深層網絡的能力至少要大於等於淺層網絡的能力(恆等映射的能力),當網絡加深我們希望這些多加的網絡(extra layer)不要影響我們原本網絡的能力,這時候就可以適時的跳過如右圖所示,我們假設輸入是x而經過中間的extra layer結果是F(x),那我們希望extra layer不影響我們輸出的結果(輸入=輸出),這時候在訓練過程中我們就要盡量讓F(x) = output-x = 0(這我們叫殘差residual)當然ResNet詳細的原理我就不在這邊展開,有興趣的朋友可以搜尋一下,許多大神都有給出很好的介紹。

看到這就相信大家會有一個疑問,既然淺層的網絡效果比較好,那為什麼還要加深網絡?
主要是因為越深的網絡它可以學到更多的細節和特徵,所以它可以應付更多的場景,假設現在數據集是A,它在20層就已經達到很好的表現,但今天我們有另一個比A還要複雜且龐大的數據B,它必須要用到更深的網絡,但我們又怕訓練得時候網絡退化,這時候ResNet就可以派上用場了!
所以像特斯拉這種每天蒐集到的資料都在不斷增加的情況,為了防止網絡退化,ResNet必不可少,所以ResNet可以說是加深網絡不可缺少的武器。
我們現在已經解決了加深網絡的問題,接下來就是我們要如何決定神經網絡裡面的參數,神經網絡裡面充滿了參數,像剛剛提到的網絡深度就是其中一個,當然還有網絡的寬度(神經元的數量)、訓練的回合數和激勵函數(activation function)的選擇等等,我們這邊是科普小教室,所以不需要知道每個參數實際的運作方式和原理,只需要明白神經網絡裡面充滿了各種參數的排列組合,不同的資料使用的參數都有所不同,所以必須做參數的優化。
但參數有這麼多種,排列組合的數量大得驚人,這裡特斯拉就參考FB AI團隊提出的RegNet的方法,FB團隊透過大量的實驗,利用統計的方法找出各種參數與模型之間的關係,就提供後人很多參考的空間,舉下圖為例,每一個藍點就代表一種神經網絡的模型(方法),在同一組數據的情況下,他們將不同模型應該用多深的網絡才能有最小誤差給大家呈現出來了!簡直是佛心到不行呢~

至此一開始的第一個問題:你想學到什麼?所延伸出來的兩個子問題特斯拉已經站在微軟和FB的肩膀上克服掉了,接下來第三個子問題:神經網絡怎麼知道圖片裡有車子和行人等物件呢...?還有要怎麼解決主要的大問題:我們到底要學到什麼?
下集待續~
延伸閱讀
參考資料
[1] 特斯拉官網
[2] 特斯拉AI日影片
[3] He, Kaiming, et al. "Deep residual learning for image recognition."Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[4] Radosavovic, Ilija, et al. "Designing network design spaces."Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.