原論文名稱:Deep Frequency Re-calibration U-Net for Medical Image Segmentation
期刊年份:ICCV 2021
Official Github repo: https://github.com/rezazad68/FRCU-Net
緒論/Introduction
醫學影像是目前診斷中關鍵的判斷依據,取得準確的醫療影像可以減少診斷時間以及醫療成本。現代醫療成像方法包括MRI、CT都是常見於觀察不同身體部分的影像技術,因此自動處理這類型的影像對於疾病診斷是非常必要的。醫療影像分割任務為了要精準診斷與縮短時間,需要異常區域或重要區域預分割(Pre-segment)影像。影像分割包括大量的應用,從RGB影像之皮膚癌(Skin cancer)、肺組織CT影像分割到病理影像分析。

醫學影像由於其複雜性導致分割任務成為一個很挑戰性的任務,舉例來說:皮膚癌影像分割存在大量類別外變異性(Intra-Class Variabilities)與類別內相似性(Inter-Class Similarity),由於顏色、紋理、形狀、大小、對比度甚至於Lesion位置的不同都會導致分割任務變得困難(如上圖)。為了解決這些問題出現很多以深度學習為基礎的電腦視覺任務出現,像是從人類皮質視覺原理啟發的CNN就可以使用分層結構學習比較複雜的影像特徵。
深度學習最主要的缺點在於需要大量標記過的資料,但是醫學影像領域中取得有標記的影像非常困難,更遑論是大規模的資料集。為了解決此問題Ronneberger團隊在U-Net上延伸出FCN的方法。相較於先前的方法U-Net較能夠有好的表現以及利用這些資料。為了進一步優化U-Net性能有許多方法被提出來,例如在原本U-Net加入注意力機制、RNN或是在卷積層中加入一些非線性函數(Non-linear functions),不過這些方式的共通點是過多著重在紋理方面多過於形狀方面,限制CNN利用有用的低頻資訊(Low-frequency information),像是形狀。先前研究證明使用形狀資訊可以提高CNN的表現,然而設計一種可以衰減高頻局部分量(High-frequency local components)並從低頻資訊中受益的有效方法仍然是一個尚未嘗試的方向。
此研究為了解決以上問題而提出了叫做Frequency Re-calibration U-Net (FRCUNet)的網路,使用頻率級別注意力機制控制與聚合表示空間(Representation space),使用不同頻率資訊的加權組合。為了從紋理與形狀的影響中得到好處,此研究在U-Net之Bottleneck使用Laplacian pyramid,Laplacian pyramid的低頻率域(domain)讓網路學習形狀(Shape)資訊,而高頻率域負責紋理(Texture)相關的特徵,從而減少噪聲對最終表示的影響。傳統影像處理上Laplacian pyramid取得巨大成功,例如SIFT,在Laplacian pyramid使用Gaussian kernels在物件的多頻率域呈現高表徵力。
為了提升不同頻率階層[註1]之不同通道(Channels)的判別力,FRCUNet模型利用Channel-wise Attention重新校正頻率表徵(Frequency Representations,啟發自squeeze and excitation modules),接著提出加權結合函數用於聚合來自Laplacian pyramid的所有layers的所有特徵,讓網路根據最終表現自己學習權重代表之重要性。
[註1]這裡的階層(Level)指的是不同深度特徵圖,越深處的階層特徵圖越能夠呈現紋理,越淺處的階層越能呈現形狀。
相關研究/Related Work
深度學習研究成長非常快速,而且在醫學影像歌上已經是非常常見的策略。FCN為首度使用卷積神經網路用於醫學影像分割任務的方法其中之一,是一種pixels-to-pixels網路,為了維持分辨率所有全連結層都被替換成卷積層與反卷積層(Deconvolution layers)。Ronneberger團隊在醫學影像分割採用U-Net方法整合不同階層與scale的特徵。
有許多使用U-Net方法的延伸被用於影像分割。處理3D影像來說也有將所有2D操作全部改為3D操作的U-Net;U-Net++可以解決邊緣資訊還有因為下採樣導致的小物件消失問題;ResUNet提出更好的CNN骨架改善傳統U-Net,可以提取出更多scales的資訊;PraNet通過Skip-connection連結得到多個scale視覺特徵…;通過添加RCNN以及Residual RCNN(循環殘差卷積層)使用進行累積確保更好的特徵表示。Deeplab在多個網格尺度上利用了多孔空間金字塔池 (ASPP) 的思想,使用多種Dilate-rate捕捉不同尺度的資訊而在多個測試中呈現很好的表現。
實驗方法/Method

Encoder
U型結構主要在於取分層語意特徵與捕捉上下文資訊,此實驗之Encoder使用預訓練模型利用先前大量訓練模型參數進行Transfer learning可以減少後續訓練資料需求量。由於Xception的收斂速度以及準確性,這次實驗中使用Xception作為模型骨架。卷積層部分使用的是分層卷積的方式,分為Channelwise 3 × 3 spatial convolution與1 × 1 pointwise convolution以節省運算量。
Frequency Re-calibration Module
U型結構包含一系列的常規卷積層在Bottleneck中,卷積層具有很強的紋理歸納偏差,換句話說,這些模型傾向使用物件的紋理來執行辨識任務,但是人類認知更常被物件的形狀所影響,利用在頻率域(Frequency domain)中的卷積層提取出的特徵,可以同時使用紋理以及形狀的優勢訓練模型。根據不同任務與資料,紋理與形狀的重要性各自不同,比如說:提取的特徵圖的低頻域包含輸入數據的形狀資訊,而較高的頻率域負責紋理資訊。比起只著重在以上2種常見之特徵,此研究也提出頻率校正(Frequency Re-Calibration, FRC)模組包含了Laplacian pyramid與頻率注意力(Frequency attention),透過Laplacian pyramid計算提取特徵圖的頻率等級。FRC模組被利用在bottleneck層。以下是FRC模組計算方式:
Laplacian Pyramid
從卷積層提取的特徵圖透過Laplacian pyramid納入頻率域中。 為了逼近Laplacian pyramid,首先從Encoder的特徵圖(X ∈ H×W×C)提取一個 (L + 1) 高斯特徵,使用不同的值作為高斯函數的方差以生成不同的尺度。
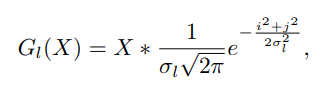
其中 σ_l 是第 l 個高斯函數的方差,i 和 j 表示編碼特徵空間中的空間位置,X 是編碼特徵圖的輸入,由大小為 H × W 的 C 個通道組成,* 表示 卷積算子。 為了對不同尺度的頻率信息進行編碼,我們應用了一個方差增加的 DoG 金字塔。 金字塔的第 l 層計算為:

其中LP_l是Laplacian pyramid的第l層,G_l是第l個高斯函數的輸出,L是金字塔的層數。
Frequency Attention
此實驗提出的頻率注意力機制用來聚合所以階層的頻率域,換句話說,這個網路利用Laplacian pyramid的每個頻率階層的所有全局特徵。這個想法有助於網絡選擇性地強化內容豐富的頻率階層並抑制不太有用的頻率階層。一開始對於Laplacian pyramid的每個階層進行input的標準化,為此,利用輸入特徵之全局特徵的全局上下文資訊產生每個Laplacian pyramid中的所有輸入通道的權重,全局平均池化計算(Global Average Pooling, GAP)方式如下:

其中 LP^f_ l 是第 l 個Laplacian pyramid階層的頻率特徵的第 f 個通道,H × W 是每個通道的大小,GAP^f_ l 是第 l Laplacian pyramid階層的第 f 個通道的全局平均池化函數輸出, 然後使用兩個全連接層(FCL)來捕獲每個級別的特徵圖的通道依賴關係,如下所示:
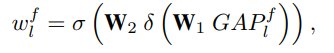
其中 W1 和 W2 是 FCL 的參數,δ 和 σ 分別是 ReLU 和 Sigmoid 激活函數,w^f_ l 是第 l 層的第 f 個通道的學習權重。 每個通道中的最終特徵圖是通過將學習的權重與輸入通道特徵點積相乘來計算的。

重新校準每一階層中的所有特徵圖之後,根據每個階層的判斷力(Discriminative power)聚合所有Laplacian pyramid階層的特徵。 為此,為每個階層學習一個權重,並利用非線性深度聚合將這些特徵以下公式組合:
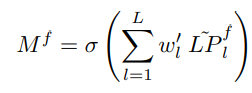
其中 w’_l 是第 l 層的學習權重,LP^f_ l 是第 l 層特徵集的第 f 個通道,M^f 是輸出特徵圖的第 f 個通道。
Code實現方式(Tensorflow)
## Gussian filtering
G1 = Sigma1_layer(x)
G2 = Sigma2_layer(x)
G3 = Sigma3_layer(x)
G4 = Sigma4_layer(x)
G0 = x
## Laplacian Pyramid
L0 = G0
L1 = layers.Subtract()([G0, G1]) # 計算2向量之差G0-G1
L2 = layers.Subtract()([G1, G2])
L3 = layers.Subtract()([G2, G3])
L4 = layers.Subtract()([G3, G4])
## Frequency Attention
L0_1 = layers.Reshape((1, 1, 256))(layers.GlobalAveragePooling2D()(L0))
L0_1 = Dense2(Dense1(Dense0(L0_1)))
L1_1 = layers.Reshape((1, 1, 256))(layers.GlobalAveragePooling2D()(L1))
L1_1 = Dense2(Dense1(Dense0(L1_1)))
L2_1 = layers.Reshape((1, 1, 256))(layers.GlobalAveragePooling2D()(L2))
L2_1 = Dense2(Dense1(Dense0(L2_1)))
L3_1 = layers.Reshape((1, 1, 256))(layers.GlobalAveragePooling2D()(L3))
L3_1 = Dense2(Dense1(Dense0(L3_1)))
L4_1 = layers.Reshape((1, 1, 256))(layers.GlobalAveragePooling2D()(L4))
L4_1 = Dense2(Dense1(Dense0(L4_1)))
## Final feature map in each channel
m0 = layers.multiply([L0, L0_1])
m1 = layers.multiply([L1, L1_1])
m2 = layers.multiply([L2, L2_1])
m3 = layers.multiply([L3, L3_1])
m4 = layers.multiply([L4, L4_1])
Decoder
本次研究使用使用了與常規 U-Net 中相同的Decoder,來自Encoder部分的特徵與來自前一個Decoder層的上採樣特徵相連接,然後將連接的特徵傳遞給兩個 3 × 3 的卷積函數。 我們利用交叉熵能量函數(cross entropy energy function)來訓練網絡。
實驗結果/Result
這次實驗在五個資料集上面測試:ISIC 2017、ISIC 2018、PH2、Lung segmentation、SegPC 2021 challenge datasets。模型是用Tensorflow的框架架構、Batch size設定為8,訓練資料沒有經過資料增量(Data augmentation),並將此實驗並使用GTX1080進行訓練。使用Adam優化器(Optimizer)並設定其學習率為0.0001,同時也採用訓練策略當validation loss連續10個epochs都沒有改變時就會終止訓練。以Accuracy(AC)、sensitivity (SE)、specificity(SP)、F1-Score、Jaccard similarity(JS)在實驗測試指標(Metrics)。基準模型使用的是相同結構的FRCU-Net,但不包含FRC模組。
ISIC 2017資料集
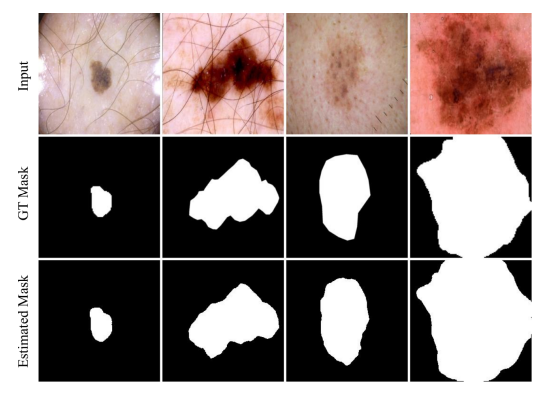

首先在ISIC 2017資料集,其中1250張影像用於訓練(62.5%)、150張用驗證(7.5%)而其他600張用於測試(30%)。原本的影像Size是576 × 767 pixels,使用前處理將影像縮減為256 × 256 pixels。上圖顯示了FRCU-Net的部分分割結果。 在表 1 中,將該資料集上所提出的網絡的定量結果與其他一些相關方法進行了比較。 在所有指標上,FRCU-Net 的性能都優於基準模型。 結果顯示除了靈敏度之外,FRCU-Net比其他方法取得了更好的結果。
ISIC 2018 Dataset
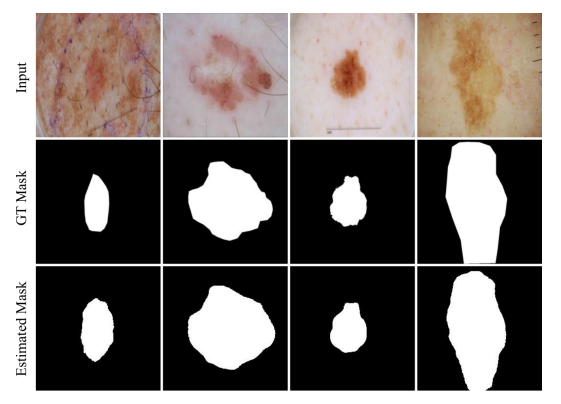

國際皮膚成像協作組織 (ISIC) 於 2018 年將該資料集作為皮膚鏡圖像的大規模數據集發布,其中包括 2594 張圖像及其相應的Ground Truth(包含癌症或非癌症病變)。實驗採用 1815 幅圖像進行訓練,259 幅圖像用於驗證,520 幅圖像用於測試。 我們調整每個樣本的原始大小,從 2016 × 3024 變更到 256 × 256 像素。 上圖顯示為FRCU-Net的部分輸出。上表也列出了不同替代方法的定量結果以及在該數據集上測試過的網絡效能,可以看出FRCU-Net實現了更好的性能,在所有測試指標(F1 分數、靈敏度、準確性和 Jaccard 相似性)FRCU-Net 優於基準模型。
Lung Segmentation Dataset

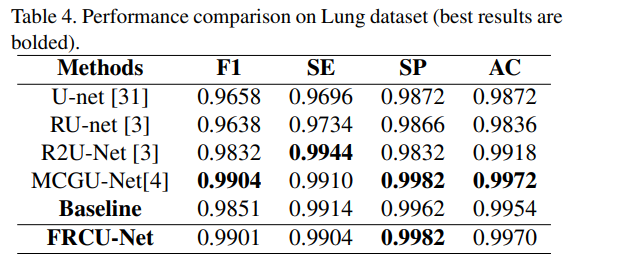
2017 年 Kaggle Data Science Bowl的肺結節分析 (LUNA) 競賽引入了肺分割數據集 [1]。 該數據包括帶有肺分割標籤的 2D 和 3D CT 圖像。 此實驗使用 70% 的數據作為訓練集,其餘 30% 作為測試集。 每張圖像的大小為 512 × 512 像素。
上圖顯示了FRCU-Net的部分輸出。 上表將 FRCU-Net 在該數據集上的性能與其他SOTA方法進行了比較。,可以看出除了MCGU-Net以外,表中列出的其他方法中,FRCU-Net 在表中列出的其他方法中實現最佳 F1-Score 和準確度。 由於MCGU-Net 在跳躍連接層使用雙向 ConvLSTM,在瓶頸層使用密集連接。 因此,與 FRCUNet 相比,MCGU-Net 包含更多的訓練參數,因此需要更長的收斂時間。
SegPC 2021 Challenge dataset
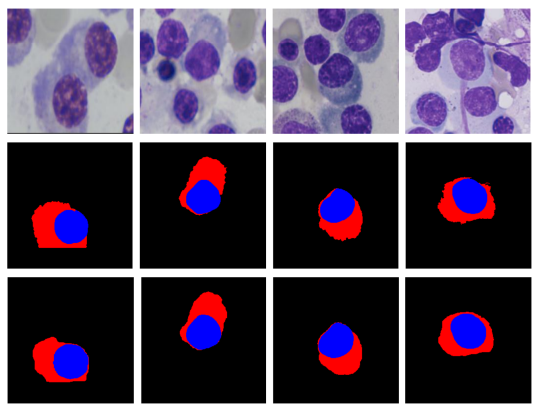
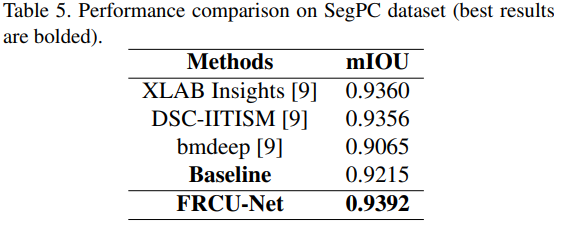
這個實驗在 SegPC 2021資料集提供多發性骨髓瘤細胞分割重大挑戰上評估FRCU-Net的表現。 該資料集中的影像是從被診斷患有多發性骨髓瘤 (MM)(是White blood cancer的一種)的患者骨髓抹片構成的。 該資料集由一個包含 290 個樣本的訓練集、一個包含 200 個樣本的驗證集和一個包含 277 個樣本的測試集組成。 由於測試數據不公開,訓練數據集拆分為訓練和驗證集,並在原始驗證集上評估該方法作為我們的測試集。 所有樣本均由病理學家進行標註,並為每個骨髓瘤漿細胞(Myeloma plasmacells)提供Ground Truth mask。
FRCU-Net 的一些分割輸出如上圖,FRCU-Net的 mIOU 與上表中其他方法進行了比較。排名第一的團隊(XLAB Insights)利用了三個實例分割網絡(SCNet、ResNeSt、Mask-RCNN ) 稍作修改以適應當前任務。 第二個團隊(DSCIITISM)採用具有大量數據增強方法的 Mask RCNN 模型。 而bmdeep使用了一種注意力DeeplabV3+ 方法和區域基礎的多尺度訓練策略。 在此實驗也使用這個這樣的策略並將注意力DeeplabV3+替換為FRCU-Net。 我們的實驗結果表明與上述所有方法相比FRCU-Net確實有性能提升。
Effect of the FRC Module
FRCU-Net的 FRC 模塊用於組合這些類型的特徵,讓網路學習最具辨別力的特徵。 與 U-Net 相比FRCU-Net 產生更準確的輸出分割,提供比較準確和平滑的分割邊界,正確定義皮膚病變的形狀,就像在ISIC 2017結果看到的皮膚病變不像其他測試項目那樣明顯,並且背景和病變(Lesion)之間存在重疊。總體而言,可以看出 FRCU-Net 的視覺性能優於原始 U-Net。
總結/Conclusion
這個研究提出了用於皮膚病變分割的 FRCU-Net。結果顯示常規卷積層傾向於學習基於紋理(Texture)的特徵,而在不同應用任務中多重視形狀特徵可以提供更精準地分割資訊。為了考慮這兩種特徵,通過設計並插入 FRC 模塊來擴展原始的 U-Net,該模塊包括兩部分:Laplacian pyramid和Frequency Attention。頻率域中表示卷積層的提取特徵圖,提取基於紋理與基於形狀的的資訊。為了聚合Laplacian pyramid各個階層的特徵而提出Frequency Attention,首先,每組特徵圖通道通過使用全局平均池化(GAP)重新校準。然後利用非線性聚合函數組合來自Laplacian pyramid不同階層的特徵。從結果來看對五個公用醫學圖像分割數據集的評估表現,此研究提出的 FRCU-Net優於SOTA的方法。
以上翻譯皆由本人與Google進行,文章包含個人理解,如有錯誤敬請指教!






















