這篇來寫,嘗試用GPT4解決工作中,一個讓我渾身難受的問題。
任務說明
我要做的事情是,把word檔中表格的部分資訊擷取出來。下圖的示範表格即是一例。
我需要存取表格中特定元素資訊,例如 Net Calorific Value,我得存下Min. 4,750這個訊息,同理可知,Total Sulfur的話,我需要記下他是 Max. 0.6。
背景 (涉及一點技術上的名詞)
先前的作法是,我用python的docx讀取word檔案,並且識別文件中可能存在的「表格」。第二步用正則表達式──如果不知道這是啥,就把它當作是一個找尋規則的方法──根據表格型態不同,擷取出目標元素的對應數值。
然而,這個方法令人痛苦......。因為這些word表格是人手去填的,規則不一。例如,可能有人會把Net Calorific Value寫在第三個列,有些人把他寫去第四列;有人的4,750有加逗號,有的沒有加(4750)。
這就導致了我所寫的規則,永遠都有例外,以至於這個工作長期停滯不前。執行上竟然花了兩周,才完成了20%的資料整理。
來點 AI !
仔細想想,應該讓AI來幫忙才對,因為AI適合在不規則中歸納訊息。怎麼做?
展示一下測試用的程式碼。
'''
1 接續前面步驟,讀取word檔並偵測出表格
2 回傳結果tables
'''
print(tables[3]) # 查看眾多tables中的第4個table,即本文的表1
這是一個二維的列表如下。
[['Item', 'Unit ', 'Limit of Range'],
['Total Moisture (TM) \n(As received basis)', '% WT', 'Max. 28'],
['Volatile Matter (Air dried basis)\nFixed Carbon (Air dried basis)\nAsh (Air dried basis)', '% WT\n% WT\n% WT', 'Min. 22∼Max. 45\nMax. 60\nMax. 17'],
['Total Sulfur (As received basis)', '% WT', 'Max. 0.6'],
['Grindability (HGI)', '', 'Min. 45~Max. 65'],
['(As Received Basis)\nGross Calorific Value\nNet Calorific Value *', '\nkcal/kg\nkcal/kg', '\n\nMin. 4,750'],
['Nitrogen (Dry ash free basis)', '% WT', 'Max. 2.2'],
['Ash Fusion Temperature (IDT) \n(Reducing Atmosphere) ', 'oC', 'Min. 1,150'],
['CSN(Crucible Swelling Number)', '', 'Less than 2\n(0≤CSN<2)'],
['Mercury(HG)', '㎍/g', ''],
['Ash Analysis\nSiO₂\nFe₂O₃\nNa₂O\nK₂O', '\n% WT\n% WT\n% WT\n% WT', '\nMax. 70\nMax. 16\nMax. 2\nMax. 3'],
['Size Distribution\nAbove 50mm\nUnder 2mm \nUnder 0.25mm', '\n%\n%\n%', '\nMax. 5\nMax. 40\nMax. 17']
]
這個表格,就是本文表例1的完整長相,現在變成python列表。
我要讓AI理解這個列表,並且摘要出我需要的元素數值。
下面做的事情很簡單,就是把前面python 列表所有元素,全部都融合為一段文字,很長的文字。
import openai
openai.api_key = TOKEN # 輸入你的API KEY
tb_specs = tables[3] # 本文的表1
output_txt = ""
for sub_lst in tb_specs:
for ele in sub_lst:
output_txt += " " + ele.strip("\n")
print(output_txt)
產出如下,所有的列/欄位名稱與數值,通通都混在一起,變成一串很長的文字。
' Item Unit Limit of Range Total Moisture (TM) \n(As received basis) % WT Max. 28 Volatile Matter (Air dried basis)\nFixed Carbon (Air dried basis)\nAsh (Air dried basis) % WT\n% WT\n% WT Min. 22∼Max. 45\nMax. 60\nMax. 17 Total Sulfur (As received basis) % WT Max. 0.6 Grindability (HGI) Min. 45~Max. 65 (As Received Basis)\nGross Calorific Value\nNet Calorific Value * kcal/kg\nkcal/kg Min. 4,750 Nitrogen (Dry ash free basis) % WT Max. 2.2 Ash Fusion Temperature (IDT) \n(Reducing Atmosphere) oC Min. 1,150 CSN(Crucible Swelling Number) Less than 2\n(0≤CSN<2) Mercury(HG) ㎍/g Ash Analysis\nSiO₂\nFe₂O₃\nNa₂O\nK₂O % WT\n% WT\n% WT\n% WT Max. 70\nMax. 16\nMax. 2\nMax. 3 Size Distribution\nAbove 50mm\nUnder 2mm \nUnder 0.25mm %\n%\n% Max. 5\nMax. 40\nMax. 17'再來如下,把那串長字丟到ChatGPT裡面,讓他閱讀與回答。
選用模型 (model) 為GPT4。在message參數中,輸入你要他做的事情 (input),餵給他剛才那個很長很長的文字串(output_txt)。
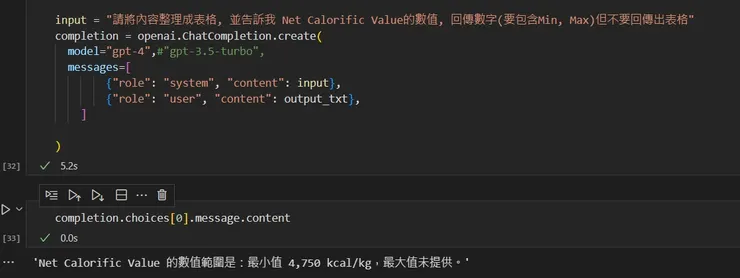
input = "請將內容整理成表格, 並告訴我 Net Calorific Value的數值, 回傳數字(要包含Min, Max)但不要回傳出表格"
completion = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": input},
{"role": "user", "content": output_txt},
]
)
然後察看結果
print(completion.choices[0].message.content)
'Net Calorific Value 的數值範圍是:最小值 4,750 kcal/kg,最大值未提供。'
回應內容非常正確,Net Calorific Value的數值範圍,就是Min. 4,750,你可以回去看一下表1。
如果我想看Total Sulfur,不知道能否做到?如法炮製前面的步驟,只是換一個問題。
input = "請將內容整理成表格, 並告訴我 Total Sulfur (As received basis) 的數值, 回傳數字(要包含Min, Max, 如果有的話)但不要回傳出表格"
completion = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": input},
{"role": "user", "content": output_txt},
]
)
print(completion.choices[0].message.content)
'Total Sulfur (As received basis) 的數值為 % WT Max. 0.6。'
結果還是對的!
兩種後續嘗試
1. 我會繼續用上述方式,找尋其他更多我要的資訊,如果都能成功,我就可以減輕寫複雜程式的痛苦。
2. 嘗試下出更好的input,也就是讓GPT4直接吐給出我想要的數值。目前他的回答都是一串完整的句子,其實我不用,我比較需要這樣形式:
Net Calorific Value: Min. 4,750
這樣資料整理起來就更輕鬆。
三個心得
1. 我覺得GPT4非常強大,我們給他讀的是一串混亂的文字,他竟然能理解出哪個數字對應哪個名稱。他的理解力確實不一般,我還有其他領域的嘗試,也發現了這點──之後有機會繼續分享!
2. 問問題的能力很重要。
我是經過反覆試驗,了解到怎麼樣的問法才是合適的問法,並讓GPT明白如何回答。請看我上面程式碼,我是先叫 GPT 把輸入那串複雜文字,整理成「表格」,再讓他回傳 Net Calorific Value 的數字。如果沒有整表格這一步,他回傳任何數字都是錯的。
3. 也因此,我們注意到ChatGPT的極限:他對理解表格訊息的理解,是一個大罩門。原因我大概想了幾點,之後有機會再繼續!
關於這個讓人渾身難受的任務,現在已經看見希望的曙光了。























