Sora 是一個 AI 模型,可以根據文字指令創建現實且富有想像的場景。Sora 可以產生長達一分鐘的Video。
官網上的幾個例子:
Prompt: Several giant wooly mammoths approach treading through a snowy meadow, their long wooly fur lightly blows in the wind as they walk, snow covered trees and dramatic snow capped mountains in the distance, mid afternoon light with wispy clouds and a sun high in the distance creates a warm glow, the low camera view is stunning capturing the large furry mammal with beautiful photography, depth of field.
請點選看上面文字內容影片。

Prompt: A movie trailer featuring the adventures of the 30 year old space man wearing a red wool knitted motorcycle helmet, blue sky, salt desert, cinematic style, shot on 35mm film, vivid colors.

Prompt: This close-up shot of a Victoria crowned pigeon showcases its striking blue plumage and red chest. Its crest is made of delicate, lacy feathers, while its eye is a striking red color. The bird’s head is tilted slightly to the side, giving the impression of it looking regal and majestic. The background is blurred, drawing attention to the bird’s striking appearance.
看影片。

prompt: A Chinese Lunar New Year celebration video with Chinese Dragon.

官網說該模型對語言有深入的理解,使其能夠準確地解釋提示並產生引人注目的特色元素來表達充滿活力的情感。Sora 還可以在單一生成的影片中做出多個鏡頭,準確保留角色和視覺風格。
但也存在"沒有因果關係"的缺點。例如,一個人可能咬了一口餅乾,但之後餅乾可能沒有咬痕。還有空間感錯置等等等的問題。


要達到這些結果的背後需要幾個技術的結合,包括像是把圖像(高維度)降階為低維度的資料進行相關後續的訓練程序。
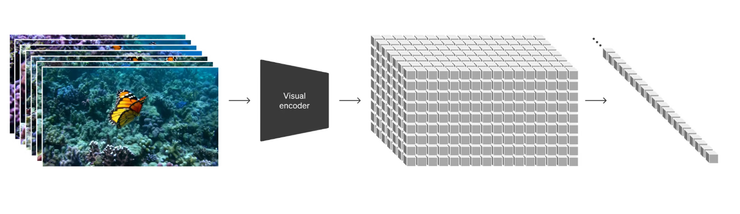
然後透過diffusion model,生成圖像。Sora 是一個diffusion transformer。過去已經有許多研究了各種方法對視訊資料進行生成的模型,像是recurrent networks, generative adversarial networks, autoregressive transformers, diffusion models等等等。這些作品通常專注於一小類視覺數據、較短的影片或固定大小的影片。Sora 官方宣稱自己是視覺資料的通用模型,它可以產生跨越不同的持續時間、長寬比和解析度的影片和影像,最多可達一分鐘的高清影片。將視覺數據轉化為一系列的連續影片。

他們利用一個降低維度的視覺資料訓練出一個神經網路。此網路將原始視訊作為輸入,並輸出包括時間和空間上的資訊。Sora以這樣的資料來訓練模型(潛在空間的向量運算),並且也訓練了對應的解碼器(decoder)模型,將產生的latents 映射回像素空間。
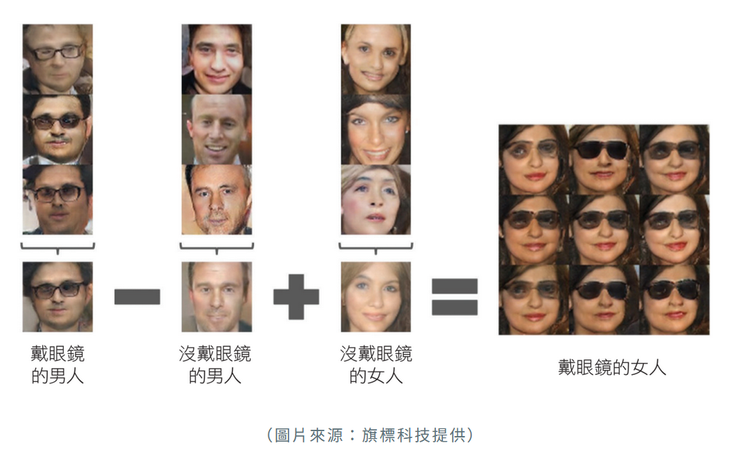
潛在空間(latent space)可以用下圖的三維潛在空間來做說明:
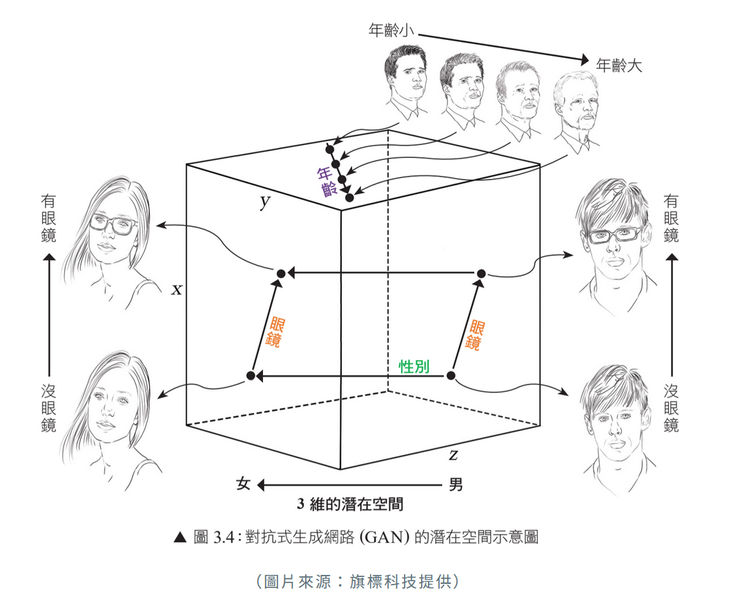
上面只是為了讓人類容易理解的三維空間,兩點在潛在空間中的位置越近,則代表圖片也就越相似,跟詞向量空間接近,在潛在空間中朝特定方向移動也是有意義的,例如順著 x 軸的箭頭代表人臉有沒有戴眼鏡;z 順著 y 軸的箭頭移動會看到年齡的變化;z 順著 z 軸的箭頭移動則代表性別的變化。真正的潛在空間是n維的,但不管幾維,他們就是順著這樣的理論在做事的。對基礎理論有興趣的讀者,不妨可以買本書來提升一下功力,在我們的Ref中可以參考。
總結,Sora結合了圖像的diffusion跟文字的transformer成功製造了Video的GAN模型,我們離駭客任務的世界,越來越近了。以後,所見不一定是所得,DAAS已經在身邊。
Ref.
https://openai.com/research/video-generation-models-as-world-simulators
https://www.books.com.tw/products/0010901055



























