
題目概述[問題連結]
這題想解的是:當我們手上有一份記錄了機器上 process 的開始與結束時間的表格,要怎麼計算「每台機器平均每個 process 花了多少秒」?資料是 event log 的形式,也就是每筆記錄只說了 start 或 end,而不是完整的一段處理區間。要先重組出每個 process 的起訖時間,才能進一步算處理時間。
這就像我們在分析操作 log、出貨記錄時,常遇到「只看到某一步驟的時間戳」的狀況,要自己補回整段活動時間。
Input 格式表格名稱為 Activity,包含以下欄位:
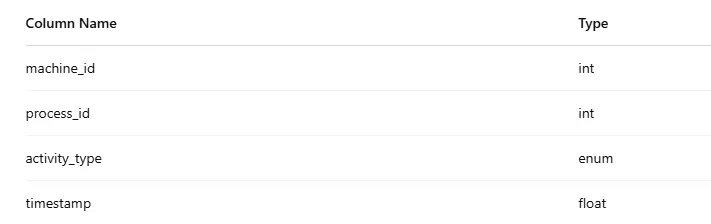
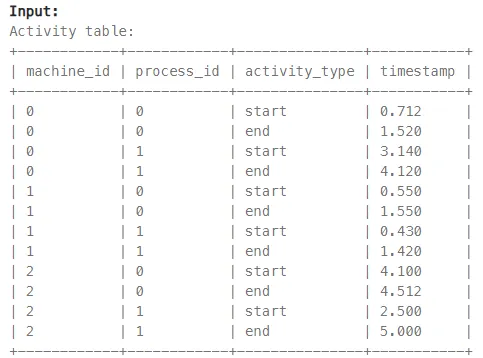
每台機器每個 process 都會對應兩筆記錄:一筆 start、一筆 end,沒有缺漏。
Output 格式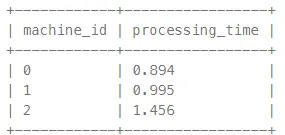
代表每台機器平均處理一個 process 所花的時間(end - start),四捨五入到小數後三位。
Pandas 解法 1Step 1: 把 activity_type 的值 pivot 成欄位,取得 start 和 end 時間
Step 2: 計算每個 process 的處理時間
Step 3: 每台機器平均處理時間,保留三位小數
import pandas as pd
def get_average_time(activity: pd.DataFrame) -> pd.DataFrame:
#1
df_pivot = pd.pivot(activity,index=['machine_id', 'process_id'],columns='activity_type',values='timestamp').reset_index()
#2
df_pivot['processing_time'] = df_pivot['end'] - df_pivot['start']
#3
result = df_pivot.groupby('machine_id')['processing_time'].mean().round(3).reset_index()
return result
Pandas 解法 2反轉 timestamp 巧妙處理 start & end
這個方法用「符號反轉」的技巧,輕鬆對應 start / end,快速算出每個 process 的總花費時間。非常適合對 pivot_table 還不太熟的人。
Step 1: 把 start 的時間變成負數!為什麼?因為等下你直接把所有時間加總起來,就會是 end - start 的總和!
Step 2: 用 groupby + sum 把每台機器的:
- 總處理時間(start是負的、end是正的,加總後剛好是處理時間)
- 唯一 process 數量
Step 3: 最後每台機器的平均處理時間 = 總時間 / process 數量,記得保留三位小數
def get_average_time(activity: pd.DataFrame) -> pd.DataFrame:
#1
filt = activity['activity_type'] == 'start'
activity.loc[filt, 'timestamp'] = activity.loc[filt, 'timestamp'] * -1
#2
activity_sum = activity.groupby(['machine_id', 'process_id'], as_index=False)['timestamp'].sum()
result = activity_sum.groupby(['machine_id'], as_index=False)['timestamp'].mean().round(3).rename(columns={'timestamp': 'processing_time'})
return result
Pandas 解法 2.1極簡精煉版的「start 反號法」
使用apply + lambda 就可以在一行程式碼把 start 的時間變成負數
import pandas as pd
def get_average_time(activity: pd.DataFrame) -> pd.DataFrame:
activity['timestamp'] = activity.apply(lambda x: x.timestamp*-1 if x.activity_type == 'start' else x.timestamp, axis=1)
activity_sum = activity.groupby(['machine_id', 'process_id'], as_index=False)['timestamp'].sum()
result = activity_sum.groupby(['machine_id'], as_index=False)['timestamp'].mean().round(3).rename(columns={'timestamp': 'processing_time'})
return result
Pandas 解法 3直接「一筆 start 對一筆 end」,超直觀,最適合初學者理解。
Step 1: 分出 start / end 資料,先把 start 跟 end 資料拆開,就像在查 log 時先分類成「進場記錄」與「出場記錄」。
Step2: 將 end 的 timestamp 欄改名以便後續運算 (為了後續 merge 後不混淆,把 end 的時間戳重命名為 end_time。)
Step3: 依 machine_id + process_id 合併 start 和 end (用 machine_id 和 process_id 把 start 跟 end 配對在一起,這樣每筆 row 就有完整的時間段。)
Step4: 計算處理時間(end - start)
Step5: 平均每台機器的處理時間(保留三位小數)
def get_average_time(activity: pd.DataFrame) -> pd.DataFrame:
# 1
df_start = activity[activity['activity_type'] == 'start'].reset_index(drop=True)
df_end = activity[activity['activity_type'] == 'end'].reset_index(drop=True)
# 2
df_end = df_end.rename(columns={'timestamp': 'end_time'})
# 3
df_merged = df_start.merge(df_end[['machine_id', 'process_id', 'end_time']],on=['machine_id', 'process_id'],how='left')
# 4
df_merged['processing_time'] = df_merged['end_time'] - df_merged['timestamp']
# 5
result = df_merged.groupby('machine_id')['processing_time'].mean().round(3).reset_index()
return result
Pandas 解法 4只靠 diff() 就搞定!
這個方法很像是「走位精準型」的技巧。不用 merge、不用 pivot,什麼都不用,只要記得 start 在前、end 在後,diff() 自然幫你算出處理時間。
Step 1: 依照 machine、process、時間排序,確保順序正確(先排序是為了讓 start 真的在 end 前面出現。否則 diff() 出來會是錯的。)
Step2: 用 groupby + diff 算出每個 process 的處理時間,用 diff(),就會在第二筆(end)自動產出處理時間。第一筆(start)會變成 NaN,後面我們會把它濾掉
Step3: 只取 end 的 row,因為 diff 後的處理時間會出現在 end 這一筆
Step4: 每台機器的平均處理時間(保留三位小數)
def get_average_time(activity: pd.DataFrame) -> pd.DataFrame:
# 1
activity = activity.sort_values(by=['machine_id', 'process_id', 'timestamp'])
# 2
activity['processing_time'] = activity.groupby(['machine_id', 'process_id'])['timestamp'].diff()
# 3
df_end = activity[activity['activity_type'] == 'end']
# 4
result = df_end.groupby('machine_id')['processing_time'].mean().round(3).reset_index()
return result
謝謝您花時間將此篇文章讀完,若覺得對您有幫助可以幫忙按個讚、分享來或是珍藏喔!也歡迎Follow我的Threads/ FB,持續追蹤生產力工具、商業分析、商業英文的實用範例,提升自己的職場力喔!






















