這一期我一樣只挑了三個跟我們比較有切身關係,偏應用端的主題,很巧的是這三個都是在講cGAN的。人工智慧能做的事,已經越來越開始挑戰我們的想像極限,正開始有那種「只有你想不到,沒有AI做不到」的味道出來了。希望我能一直保持寫作輸出的習慣,讓對人工智慧有興趣,但英文苦手的朋友們儘量一起跟上世界趨勢。
Andrew Says
在思考機器學習框架的未來時,最近我重讀了電腦科學家Fred Brooks的經典文章「No Silver Bullet: Essence and Accidents of Software Engineering」。從文章公布後三十年了,它仍是建造機器學習工具的軟體工程師們,值得好好學習的一課。儘管我們的寫作工具,從以前的打字機到現在的文字編輯器,為什麼寫作仍然是這麼困難的一件事?因為文字編輯器並不能幫我們完成寫作最困難的部分:把你思考的結果說出來。
編程工具也是一樣。很高興我是用Python而不是Fortran開發,但就像Brooks指出的,再先進的編程工具也沒有辦法減少軟體開發本質的複雜性。這複雜性就在於軟體如何描述出一個設計模式來解決已知的問題,而不是如何用編程工具設計出那個軟體。

而深度學習正革命性的在解決這個本質的複雜性。比如說電腦視覺系統,比起傳統軟體開發的模式:需要實作深奧的演算法,多層次的軟體通道來實作特徵提取(Feature Extraction),座標轉換(Geometric Transformations)等等這麼複雜的開發流程,深度學習要做的就是取得足夠多的資料,訓練神經網路,就能解決這個超級複雜的問題。兩者的差異就在於,深度學習的方式並沒有描述如何設計出解決問題的設計模式,而是直接解決問題。它完全改變了我們透過設計模式去解決問題的流程了。
當我們在設計機器學習的框架時,我們應該進一步去思考如何減少建立這個系統其本質的複雜性。這不只包括建立一個神經網路(當然,現在用TensorFlow或PyTorch已經比用C++簡單許多了),還需要決定什麼是真正需要被解決的問題,從資料取得,模型訓練到部署應用,設計一個整體性的流程。
我不曉得是否有什麼妙招可以直接減少這個複雜性,不過我想應該會有軟體複用,訓練好的Model或函式庫的複用,甚至是資料的複用這樣的方向。對於非監督式或其他型式的機器學習,應該都能成為一個有所突破的助力。
News
Anonymous Faces
許多國家都有限制,不可未經許可,就將個人資料做為商業用途,除非它是完全匿名的。一篇新的論文提出了一個新的方法去「匿名化」臉部資料,而且可以不影響「匿名化」後的臉在臉部偵測系統的運作。

What’s new:
挪威科技大學的研究員,發表了「DeepPrivacy」。這是一個透過合成換臉的方式,將臉部資料「匿名化」的系統。他們也提供了「Flickr Diverse Faces」資料集,這147萬張帶有補充性元資料的臉圖,就是用來訓練「DeepPrivacy」的。
Key insight:
由於原臉圖的特徵並不會再出現在合成圖上,研究員Håkon Hukkelås, Rudolf Mester及Frank Lindseth都認為,這樣的匿名化保護,比傳統「像素化」或「模糊化」的作法更能保護其隱私。
How it works:
「DeepPrivacy」使用的是「條件化對抗式生成網路(conditional generative adversarial network)」,或簡稱「cGAN」),它的其中一個主要的應用,就是以非噪音式的生成臉圖。原理就是由網路中的鑑別器(Discriminator)負責鑑別是真實臉圖還是生成臉圖,而生成器(Generator)則基於U-Net架構被特化成有效的去創造各式各樣的臉圖,嘗試去騙過鑑別器。U-Net也是一個cGAN,它本是用在生物醫學圖像分段,希望能用最少的資料做到最好的分段效果,在這裡的應用則是用於生成各種不同的臉圖。大致的運作過程如下:
- 由「Single Shot Scale Invariant Face Detector」先檢測出輸入圖的「臉」。
- 再透過「Mask R-CNN」去定位出眼,鼻,耳,肩的關鍵點。
- 然後是把「臉」的像素都先換成亂數。
- 生成者在收到「臉」的關鍵點後,就可以開始生成各式各樣不同的「臉」來訓練這個模型,嘗試騙過鑑別者,使其分不清這是真臉還是假臉。
Results:
研究員將「WIDER-Face」資料集(將近32000張圖像,含有約394000張臉)中的臉圖,用「DeepPrivacy」及傳統匿名法都處理過一遍。受傳統匿名法的影響,在「Dual Shot Face Detector」只保有了96.7%的辨識率,而使用「DeepPrivacy」的方法,可達到高達99.3%的辨識率。由此可證透過這種匿名法,可在幾乎不影響臉部辨識系統運作的前提下,匿名你的身份。
Why it matters:
歐盟訂定了GDPR,設定了極高的標準來限制以個資驅動為主的應用及服務。透過這樣的匿名法,直接把用戶的臉換成另一張臉,就可以在仍需臉圖的神經網路訓練或實際應用服務中,更有效的符合GDPR的規範。
Yes, but:
「DeepPrivacy」只將臉換掉,但臉以外仍有許多可資辨識的資訊,像是只要有球員身上的球衣號碼,不用看臉也知道是誰。
We’re thinking:
機器學習對資料的依賴是禮物也是詛咒。資料的收集及匯總技術十分進步的現在,隱私權的倡導也同步在把資料往更保密的方向收緊。「DeepPrivacy」將會是邁向折衷方向的有趣一步,能同時讓用戶及AI工程師都滿意。
Nothing but (Neural) Net
籃球教練常常會用白板手繪的方式,來指導球員們如何將球順利的傳到籃網前。而有一個新的AI模式可以預測,對手可能會如何來對付教練的規劃出來的戰術。
What's new
來自台灣的研究團隊,使用cGAN模型配合NBA的賽事資料,訓練了一個神經網路來展示對手將會用何種方式來對抗教練手繪規劃的戰術。
How it works
研究團隊建立了一個二維的半場地圖(也有三分線),讓教練可拖曳5個球員(紅點)及傳球路徑(綠點)。不過不支援灌籃操作。
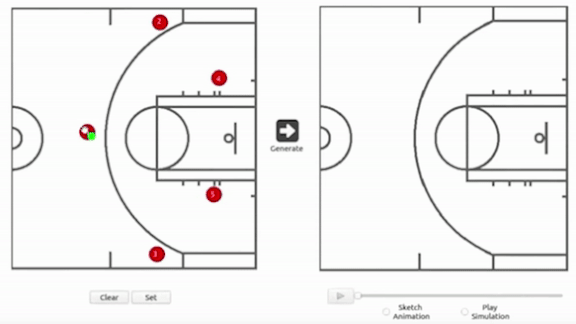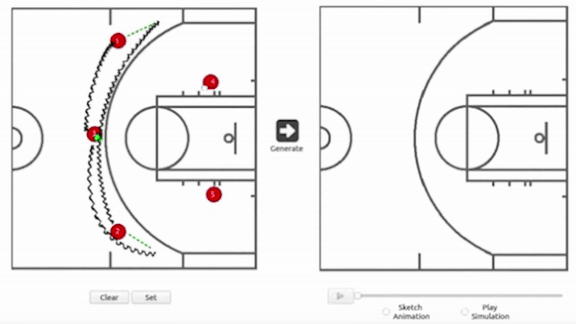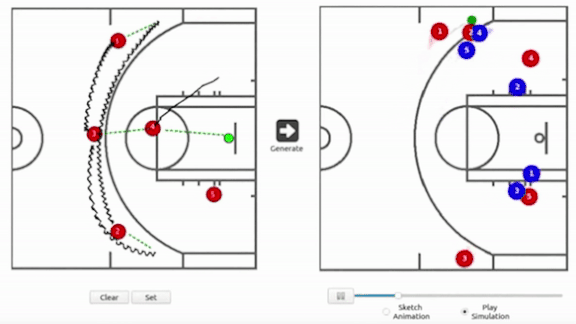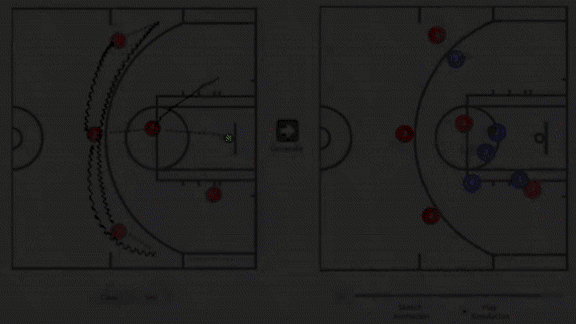
- 一但教練拉完整個戰術流程,產生器就會產出防守端5個球員將會如何行動。
- 鑑別器則是負責確保這5個球員的行為是符合真實的球賽行為的。
- 最終,模型就來顯示教練的戰術及防守端的行為。
Results
一群由NBA職業球員,籃球迷和非籃球迷組成的團隊評估了所產生的防禦現實性。儘管非職業或一般球迷很難發現這些防守行為有何不尋常,但NBA職業球員可以告訴他們,這不是由人類教練設計的。
Behind the news
「SportVU」從2011年就收集了NBA所有球員的即時資料。這個系統使用了6個攝影機,以每秒25幀的速度拍攝了球員的走位及持球等相關資訊,這個模型就是透過這些資料來辨識運球,傳球,擋切或一對一等特殊事件。
Why it matters
職業運動比賽是一個高風險產業,因此這個產業也很積極的擁抱高科技來優化表現。可以預見的是,神經網路在將來的某天,或許會產出一個像AlphaGo那樣,沒人能預想的出來的必勝戰術。
We’re thinking
這不是「灌籃高手」的劇情,職業選手不會被唬過去。但它其實是夠複雜的,可以幫助一些新手不在場上打球的時候,也能進行一些策略性的思考。
Putting Text Generators on a Leash
僅管近期在產生文字有了巨大的進展,由神經網路產生有意義的文字,仍然是個艱難的命題。僅管功能強大的「GPT-2」文字產生器只需要讓用戶多按幾次按鈕,就能得到一份有意義的文字輸出,但許多研究員們仍然試圖找出對於產出的文字,是否有更好的控制方式。

What’s new
預先訓練好的文字產生器,若要產生特定主題的文字,通常需要有特定領域知識的專業人員加以調校,才能有較好的輸出。Saleforce研發了一個恰巧叫做「CTRL」的模型,讓用戶從新聞到恐怖故事,都可以無須進一步的再訓練,就能輸出不錯的結果。
Key insight
這個模型是由控制碼引導,搭配由人工根據內文設定好的標籤(也包括笑話這個分類)訓練而成的。這個模型學習的是指定的控制碼及內文意圖的風格的關係。
How it works
「CTRL」就像最先進的語言模型「BERT」,是基於大規模的文集資料,以非監督式去訓練的變形(transformer)神經網路。所使用的資料包括了Wikipedia,Reddit及Gutenberg的電子圖書庫。
- CTRL會基於字與字之前的關係去預測下一個字,這個關係就是預先訓練學習好的。
- 在訓練期,每一個字的輸入都會帶有一個控制碼。例如在合約上提取出來的文字,就會帶有「合法」的控制碼。
- 在生成器的生成中,任何一個控制碼都可以將模型導向去產生訓練資料集中的相關子集的文字。
Results
研究員提供了一個定性結果來展示,控制碼確實可以讓模型在不同的提示詞下,產出應與之呼應的文字。例如提示詞若是”小刀”,「評論」控制碼就會讓模型產出”小刀是一種工具,而這能很好地完成工作”,而「恐怖」的控制碼則會產出”從前面開口出拉出的刀柄”。
Why it matters
理想的文字產生器,應該要能夠產出適合各種用途的各種文章段。CTRL的研發團隊則是建議,透過非監督式訓練的單一模型,就可以達到這個目標。
We’re thinking
包括GPT-2的創造者在內的許多人都擔心更多用途的文字產生器會帶來更多的不當用途。CTRL的訓練及使用模式,是否能夠透過抑制某些類型(例如公然的政治假消息)的文字產生,以及支持其他有利社會大眾類型的文字產生呢?
























