作者:陳華夫
人工智慧的學習可分為4類:(1)監督學習;(2)非監督學習;(3) 半監督學習及(4)強化學習。前三者的學習中,它的大數據庫裡都有「真品」(本尊),所以都是在「真品」的監督下學習或識別與分類,而強化學習卻是在尋找和探討「真品」。所以,在前三者的領域中,人工智慧與人類的學習各有優勢;以人臉辨識領域來說,人類圖像識別的能力可說是與生俱來,不需學習,人們不可能錯把隔壁的大嬸,誤認為自己的母親,相反的,人臉辨識卻要辛苦的從事監督學習,才能提高辨識率,目前人臉辨識軟體的準確性大幅提高,可以用於門禁管理,金融付款,及監控辨識等應用。而語音辨識技術之應用,包括語音撥號、語音導航、室內裝置控制、語音文件檢索、簡單的聽寫資料錄入等。人類辨認語言的不同口音,問題不大。但語音辨識軟體要即時把聲音轉換成正確的字幕,挑戰很大,譬如電視新聞,國會問政轉播要即時打上字幕,難度就很高。但若是先由語音辨識軟體打出辨識結果,再由速記員校正錯誤之處,則上傳速度與準確度都大幅提高。(見最熟陳時中與劉寶傑聲音的AI!陽明交大團隊:肯蹲低,才精準)
第3種半監督學習,最近在蛋白質摺疊領域受到矚目,谷歌(Google)的DeepMind公司發展的深度學習軟體─AlphaFold 在2018/12月的第13屆蛋白質結構預測技術的關鍵測試(CASP)的總體排名中名列第一。其加強版AlphaFold2的蛋白質預測準度逼近滿分,結構生物學家 Petr Leiman 感嘆,用價值一千萬美元的電子顯微鏡努力地解了好幾年,AlphaFold2 竟然一下就算出來了。蛋白質摺疊的研究對癌症、病毒類感染,抗生素、靶向藥的開發,新效率的酶研發等極為重要。(見兩大頂級 AI 演算法開源!Alphafold2 蛋白質預測準度逼近滿分,將顛覆生醫產業樣貌, AlphaFold2 爆火背後 人類為什麼要死磕蛋白質)
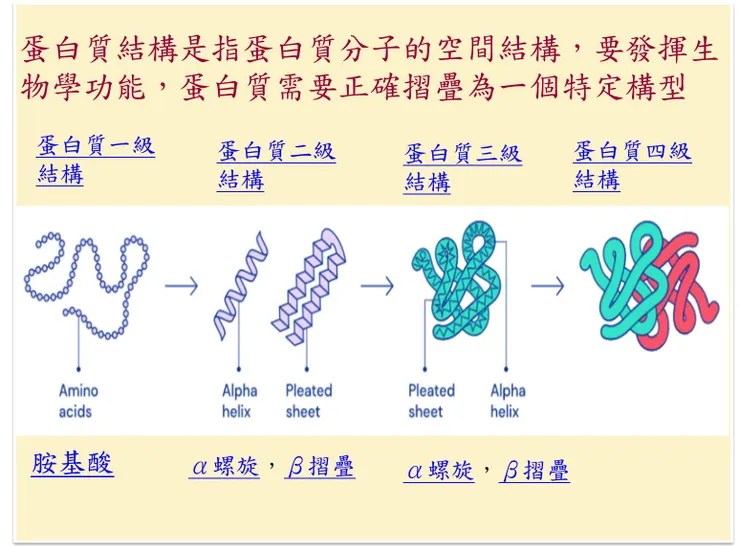
據英國《金融時報》2022/7/29日的報導,谷歌(Google)的DeepMind公司發展的深度學習軟體─AlphaFold構建了迄今最完整、最準確的數據庫,其中包含逾2億種已知蛋白質。已經超越科學知識的極限,預測出幾乎所有已知蛋白質的形狀。這項突破將顯著加快生物學發現的步伐。它的CEO德米斯•哈薩比斯表示:「我們可以開始考慮端到端的藥物設計。那將是我的夢想,在開發新藥和治療方法時,你可以加快整個過程,而不僅是結構部分的工作。這一天即將到來。」也就是可以展開癌症、病毒類感染,抗生素、靶向藥、新效率的酶等藥物研發。(見DeepMind宣布可預測幾乎所有蛋白質結構)
但第四類強化學習才是真正意義上的學習,這門學問起步很早,在1998年,強化學習的聖經─《Reinforcement learning─ An introduction》(第一版)─即問世,但因為裡面包括「動態規劃」(Dynamic Programming,DP)及「馬可夫決策過程」(Markov Decision Processes,MDP)等數課題,所以比前3者較難入門,所以一直不是熱門的研究。
但是情況有了革命性的轉變;2017年谷歌(Google)的DeepMind公司在權威的《自然》期刊是發表了強化學習史上劃時代的論文:「Mastering the game of go without human knowledge,David Silver, .et.al, Nature, 550, 354-359, 2017」(中文翻譯:不需要人類圍棋經驗練的超級電腦圍棋軟體),而這個超級電腦圍棋軟體就是舉世聞名的 AlphaGo Zero。
AlphaGo Zero之所以是強化學習史上劃時代的進展,是因為它擺脫了它的前身版本─AlphaGo Lee及AlphaGo Master ─必須借助使用人類KGS圍棋伺服器棋譜進行監督學習,也就是要借助人類圍棋的經驗來培訓。但AlphaGo Zero不同,它完全由零(Zero)開始,不需要人為指導,自己和自己對弈訓練,而不斷的自我改善棋力,40天之內可以打敗它的前身版本,成為是圍棋史上棋力遠遠超過人類的最強的電腦圍棋軟體。(詳細,見拙文「人工智慧」的AlphaGo「圍棋革命」─圍棋的本質(1),及為什麼 AlphaGo Zero?)
AlphaGo Zero的遠近馳名的成功,強化學習也水漲船高,成為深度學習最熱門的課題之一,而應用到熱門的自動駕駛產業;目前世界電動車一哥特斯拉的技術非常先進,其Model S、Model X、Model Y 還是Model 3,Autopilot(AP,輔助駕駛) 都是標準配備。而2017年,中國百度Apollo(阿波羅)計畫正式上路,並以此構建自動駕駛商業生態。2021年,北京用戶可以在百度地圖及Apollo官網上預約體驗Robotaxi。 2021/4/7日百度研發製造的35輛百度Apollo(阿波羅)自動駕駛汽車首次獲得了商業運營許可。(見拙文電動汽車世界爭霸啟示錄(II)─科技與智慧(32))
目前人工智慧研究,加拿大和美國、中國和英國是公認的世界 4 大強國,特斯拉的馬斯克創辦的 OpenAI , Facebook(臉書) AI Research(FAIR),及谷歌的DeepMind是有名的三大公司。2021年,FAIR員工不到 400 人,而谷歌的DeepMind全球擁有約 1,000 名員工,大部分都在倫敦總部上班。其餘員工分布於加拿大及法國巴黎等地。如今爭奪世界最頂尖的 AI 人才的競爭激烈,頂尖 AI 研究人員的年薪有時高達 100 萬美元。(DeepMind 持續引爆全球頂尖 AI 人才搶奪戰,多倫多成為戰火延燒重點城市)
中國的商湯科技(創始人、CEO徐立)是電腦視覺和人臉辨識領域最大的系統開發商,還投入大筆資金創建了一個超級計算平台。該公司5000名員工中的70%以上是研發人員,其外國投資者包括軟銀(SoftBank)、老虎環球(Tiger Global)和銀湖(Silver Lake)。2018年,商湯科技是全球市值最高的人工智能創業公司,市值45億美元。商湯科技為了避免美國監管機構,謹慎選擇香港為配售市場,但在2020年,商湯科技與其中國競爭對手曠視科技(專注於圖像識別和深度學習)、依圖科技(專注於智能城市和醫療)、和 雲從科技 (專注於人臉辨識)一起被美國商務部列入黑名單,禁止向它們技提供美國技術。而在2021年底, 商湯科技在香港上市前幾天,被列入投資黑名單,於是推遲赴港IPO上市。(見商湯科技的未來,及美國制裁對中國人工智能的影響微乎其微,商湯科技徐立:人工智能的下一步)
底下的文章解釋什麼是強化學習及比較其與人類學習的優劣:
1)強化學習的架構及方法:
強化學習的學習模型是先假設一系列學習狀態:St,St+1,St+2....,然後,再建立一個策略函數π(a),以規範各個動作a1,a2,a3,是如何把各種狀態變成下一個狀態及分別得到獎勵:Rt,Rt+1,Rt+2....,而把任何一狀態St,經過策略函數π(a),學習到終點所得到的總獎勵定義為:價值函數 Vπ(s) = Rt + Rt+1+ ....然後不斷的改善π0(a),π1(a),π2(a),...,及Vπ0(s),Vπ1(s),Vπ2(s)....,直到學習出最佳的策略函數π*(a)及最佳的價值函數 V*(s),如下圖。基本上,強化學習的學習就是想法寫出深度學習的演算法電腦程式,以求出最佳的策略函數π*(a)及最佳的價值函數 V*(s)。(見強化學習教程)

2)比較強化學習與人類的學習:
強化學習的方法基本上是基與心理學的行為主義學派的操作制約。它不同於古典的巴夫洛夫制約非自願反應,它是「行為主體」(agent)自願學習、是以適時的獎勵或懲罰來控制「行為主體」的學習。強化學習可說是操作制約之人工智慧的深度學習版,如下圖:

而相對的,通常人類學習複雜的事物之有效方法是自學,就是自我有「有意識」的、自覺的學習,是學習複雜事物(如微積分,物理、心裡學、經濟學、圍棋、高爾夫球等)唯一最有效的方法,也是人類學習勝過人工智慧學習的唯一法寶。其實踐方法即是經過精心組織的「刻意練習」,其要訣是3F:(1)Focus─專注學習目標,(2)Feedback─回饋達標差距,(3)Fix─不斷改善達標差距。在「刻意練習」中,主掌腦部記憶的海馬體可以生長,神經元也變的連接更多。大腦變得更聰明,更高效。(見諾貝爾獎的教育反思─「自學」與「學校教育」─科技與智慧(11))
3)強化學習的記憶體是人工神經網絡是殘差網路(ResNet):
一般的卷積神經網路(CNN)中,插入一個以上的「捷徑連結」就成了殘差網絡(如下圖)。
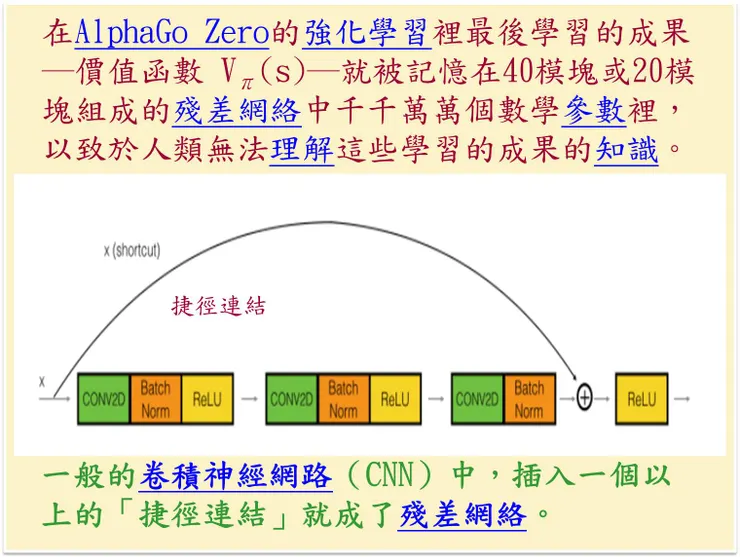
而在AlphaGo Zero的強化學習裡最後學習的成果─價值函數 Vπ(s)─就被記憶在40模塊或20模塊組成的殘差網絡中的千千萬萬個數學參數裡,以致於人類無法理解這些學習的成果。
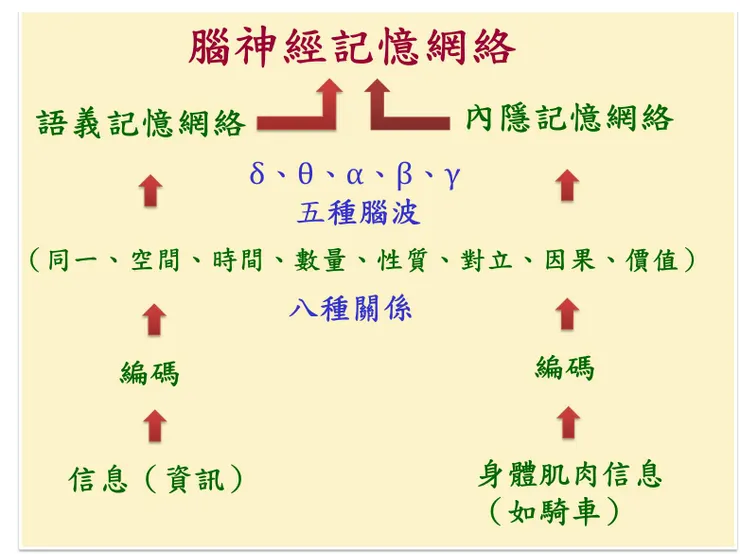
相反的,腦神經記憶網絡是由「語義記憶網絡」與「內隱記憶網絡」組成(如下圖所示):
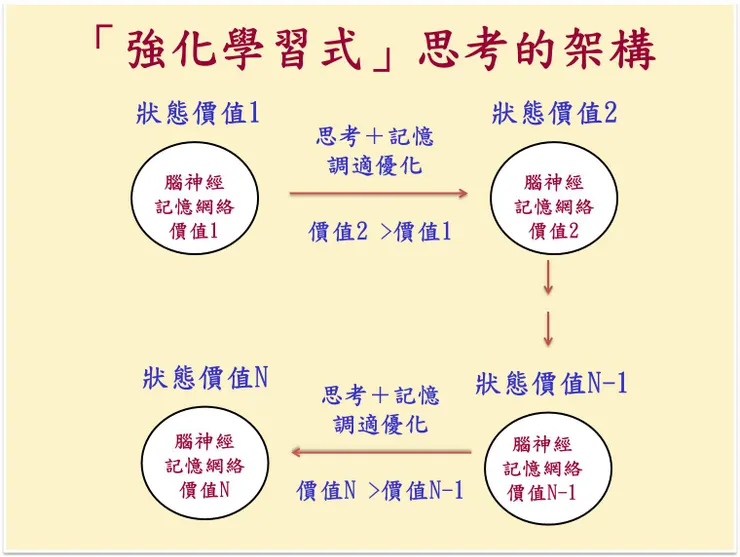
而我吸取強化學習之演算法的精髓,發展出人類的「強化學習式思考」架構,如下圖,詳細請看拙文思考、記憶、人腦解決之「強化學習式」思考架構─學習的本質(1)。
4)強化學習的學習成果無法舉一反三的學習轉移到新領域:
強化學習基本屬於深度學習,其演算法是無法提煉出規則和知識。那就意味著,無法舉一反三的學習轉移─也就是說,每次碰到類似問題,並非提煉舊有的知識,應用到新系統中,而必需重建和訓練新系統。例如,Google的DeepMind公司發展AlphaGo Lee,AlphaGo Master,及AlphaGo Zero等3個版本時,各個版本都是獨立構造,和獨立進行訓練的,各版本的圍棋知識無法舉一反三的學習轉移到其它的版本上,造成浪費資源。(詳細,見拙文AI「深度學習」的缺陷及我親身的補正?─科技智慧(5),及AlphaGo使用的強化學習是人工智慧新星?讓專家告訴你為什麼這不是通用解方)
而就因為人類可以舉一反三的學習,顯示人類不僅僅是以試錯(trial and error)產生的「實際經驗」,人類的思考可以在心靈中建立理論模型,產生「模擬經驗」來學習,可以大幅增加人類學習效率。(見拙文什麼是「思考」?如何「洞識」?何謂「思想家」?─開悟的本質(2))
至於人工智能的下一步會如何發展?商湯科技的創始人、CEO徐立的演講中有一段發人深省的話:「人類過往科研創新的範式,從最早經驗歸納的範式,到演繹推理的範式,被稱為是第一、第二範式。經驗歸納從培根開始,講了用資料做歸納。當有了電腦之後,比如模擬類比就是電腦在做推理演繹,比如大資料,第四範式大資料科學可以對應到經驗的歸納。這樣的範式在過往很長時間當中把創新的模式總結到這個框架當中。(見商湯科技徐立:人工智慧的下一步)
英國《金融時報》2022/4/11報導,迄今為止,許多最知名的人工智慧應用出現在遊戲、圖像識別和語音辨識。谷歌的DeepMind開發了舉世聞名的超級電腦圍─AlphaGo Zero,棋力遠遠超過人類。而生成式對抗網路(Generative Adversarial Network,GAN)讓兩個神經網路相互博弈的方式進行學習,而創造了深度偽造(deepfake)的視頻,將美国演员伯特•雷諾茲(Burt Reynolds)的臉替換成007詹姆斯•邦德(James Bond)電影中肖恩•康納利(Sean Connery)的臉;OpenAI以GPT-3為基礎的語言寫API(Application Programming Interface),而能模仿埃米莉·狄更生(Emily Dickinson)的風格寫詩歌。
根據斯坦福大學最新的人工智慧指數,2021年全球對人工智慧的私人投資同比增長了逾一倍,達到935億美元。自2015年以來,人工智慧的專利數量增加至30倍。雖然大宗商品、食品和能源價格一直以來都在飆升,但在過去五年里,一個機械臂的中位價格下降了46.2%。但人工智慧AI產業化轉型面臨著私營和公共部門之間知識和權力的日益失衡,而私營企業自然會優先考慮財務回報,而不是更廣泛的社會公益。(見人工智慧產業化的希望與風險共存)
2022/5/29日英國《金融時報》的為什麼你的公司裡找不到人工智慧?說:「雖然雲平台現在廣泛可用,但要想利用其潛力,還需要有精通雲計算的大學和組織。最後,組織需要特定的數據來賦予它們競爭優勢。數據可以來自內部,這意味著組織必須收集和處理數據;也可以來自外部,這種情況下,數據必須要超越基本交易數據才能發揮作用。僅憑上述的這些能力是不夠的。人工智慧的進步需要有競爭力的集群。雖然已經實現了知識全球化,但創新仍是地方性的。如果不能更好地理解這一切因素,越來越多的企業將被人工智慧革命甩在後面。」
請看「陳華夫專欄」─學習的本質─系列文章:
(
「思考是有意識的系列回憶」理論開啟了思想史革命─學習的本質(1)
什麼是「思考」?如何「洞識」?何謂「思想家」?─學習的本質(2)
什麼是「記憶」?如何「記憶」?「記憶」的本質?─學習的本質(3)
學習的真相與反思─學習的本質(4)
「施捨」就是人生的「現代開悟」─學習的本質(5)
談「恐懼」─學習的本質(6)
探究華人的「罪惡感」?─學習的本質(7)
你孤獨了嗎?─學習的本質(8)
人腦如何創新思考?─學習的本質(9)
「現代開悟」的本質及釋義─學習的本質(10)
你「現代開悟」了嗎?─學習的本質(11)
人工智慧的「強化學習」與人類學習的優劣─學習的本質(12)
伽馬波(40赫茲)、記憶、失智症、及音樂治療(2023年版)─學習的本質(13)
省思物理科學教育的真相─學習的本質(14)
人類智慧真正優於AI人工智慧之處為何?─學習的本質(15)
細述我親歷40年的學習之旅─學習的本質(16)
AI幫助人們改善記憶、思考能力─適用於年輕與銀髮人─學習的本質(17)
AI徹底改變大學理工教育的面貌─學習的本質(18)
AI模擬人類學習真能比人類更創新嗎?─學習的本質(19)
AI深度學習與《易經》的學習真有差異嗎?─學習的本質(20)
AI之ChatGPT的繪畫審美能力賞析─學習的本質(21)
請看懂智慧的本質:GPT-4的「人工通用智能」(AGI)落後人類有多遠?─學習的本質(22)
臺灣許皓鋐圍棋亞運金牌在學習圍棋上的意義─學習的本質(23)
論才華、機運、及成功─學習的本質(24)
DeepSeek影像生成之有「氣質」、「貴氣」的中國女士─學習的本質(25)
)
DeepMind 持續引爆全球頂尖 AI 人才搶奪戰,多倫多成為戰火延燒重點城市
AlphaGo設計師黃士傑:「最強的學習技能在人類的腦袋裡」
人類才不會被AI取代!《大腦如何精準學習》揭大腦6大優點:目前的人工智慧永遠學不來
























