這篇文章想與你分享,我閱讀個人化聯邦強盜文章以後,所產生的思考與理解。
本文章收錄的一個思考與理解如下:
- 個人化聯邦學習,是有效利用全局模型與局部模型,完成任務。
思考 #1:個人化聯邦學習,是有效利用全局模型與局部模型,完成任務。
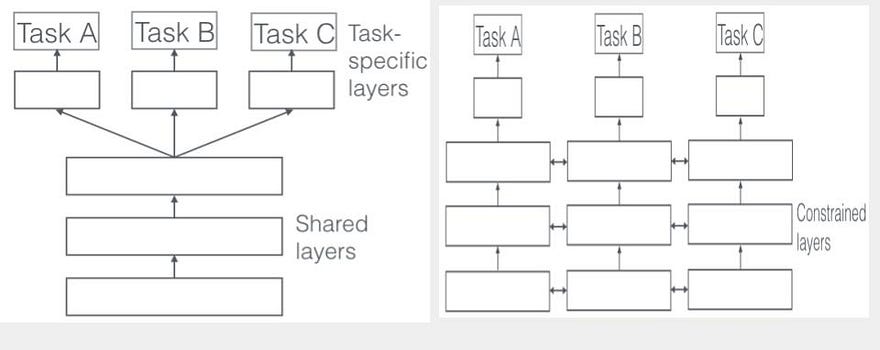
個人化聯邦學習,是一種學習方式,學習全局模型(Global model)與個人局部模型(Own local model)的混合。基本上,同時承認這兩個模型元素的存在,並且思考如何混合這兩個模型的資訊,來幫助任務更好達成。文章中則是很簡單地做重權重來學習強盜問題中的獎勵模型。
在我們的設定下,所有的用戶端(Client)都在解同一個強盜問題(Bandit problem),但由於每個用戶端的脈絡向量序列不同,其資料分布也不同。所以學習全局模型與局部模型的確是有意義,而我們對各自的結論都有給一些形式化後的結果。我們的任務,應該是「導讀」讀者去理解我們的結果。
我們的做法,是混合全局模型(Global model)與個人局部模型(Own local model)在決策的過程中。特別地,我們用全局模型(Teamwork Lasso)來執行聯邦篩選(Federated Screening),接著用局部模型(Egocentric Lasso)來執行自私決策(Egocentric Decision)。這樣的思維造就了我們特殊的Fedego Lasso策略,來提供聯邦線上高維度決策問題的解決方案。