想學習Elasticsearch搜尋引擎資料庫的夥伴歡迎參考:
📚 喬叔帶你上手Elastic Stack:Elasticsearch的最佳實踐與最佳化技巧
另外再推薦您一個基礎知識的文章:
那這次要介紹的主題主要是在Elasticsearch 搜尋引擎中的跨詞搜尋,你知道詞與詞之間也是存在著距離的嗎? 那這些詞可能是相近的,比如說: 打、藍球,這兩個詞之間的距離肯定是非常相近的,透過這樣的關係我們可以更加精確的找出我們的資料內容,至於為什麼能夠搜尋的這麼快呢? 這得感謝一項重要的技術:
【資料庫寶典】資料檢索技術 — 倒排索引(Inverted Index)
透過這項技術讓我們可以將一整篇文章根據文字內容切碎成詞,以「詞」為單位進行索引,顛覆了以往我們對於資料庫的認識,過往的資料庫系統是以「欄位」為索引進行資料的整理,現如今因應大數據時代的來臨,做了創新的索引技巧,讓我們更能夠精確的找出我們想要的資料。
精華區在這裡...
範例句:
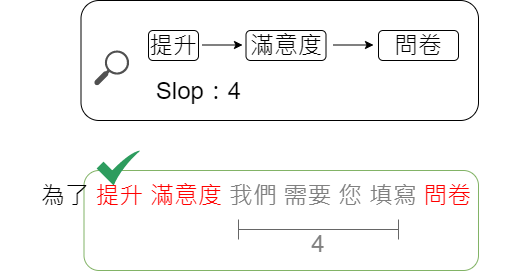
假設我們有一段文章以空白隔開的方式來切割詞彙,內容如下:
為了 提升 滿意度 我們 需要 您 填寫 問卷假設條件為:
- clauses:[提升,滿意度,問卷] 。
- slop:4。
- in_order: true
❗ 這裡的Slop代表範圍內不匹配的最大數量,從開始匹配的字詞框到最後加總一併進行計算。
查詢結構會是如此
{
"span_near": {
"clauses": [
{
"span_term": {
"dialogs": "提升"
}
},
{
"span_term": {
"dialogs": "滿意度"
}
},
{
"span_term": {
"dialogs": "問卷"
}
}
],
"slop": 4,
"in_order": true
}
}
請問上述條件是否能正確搜尋出文本?
答案: 可以, 因為「提升→ 滿意度 → 問卷」之間跨詞數量為4, 而我們條件是限定跨詞距離為4,符合搜尋條件, 因此可以被正確搜尋。
如果想要正確被搜尋出來只能增加跨詞距離來囊括匹配的範圍,但這個距離要怎麼抓呢? 勢必得根據需求以及觀察資料後才能決定這個部份的應用方式了,以上只是說明了Span Near Query的搜尋原理。
結語
原來所謂的跨詞距離就是將文字進行斷詞之後,進行逆向索引 , 以此為根基進行儲存並記載這個「詞」在哪個文件中的哪個位置,有了這些資訊之後就能夠在搜尋上加上「詞」與「詞」之間多少距離的查詢語法,這樣就能更貼近我們語言的去搜尋資料了,但這仍然不夠,規則還是有點硬邦邦的,更聰明的技術有沒有?
當然有! 但在這之前,務必請你閱讀一些關於自然語言處理的文章,累積一些基礎知識,之後再來談談關於Elasticsearch與自然語言之間究竟有什麼關係吧!
關於自然語言處理,也推薦你以下的免費文章進行閱讀:
- 【自然語言處理 - 概念篇】最基礎的Bag-of-Words模型是什麼呢?
- 【自然語言處理 - 概念篇】 來認識一下詞向量(Word Embedding or Word Vector)吧
- 【自然語言處理 - 概念篇】 探索TF-IDF, 關於詞的統計與索引隱含著什麼奧秘呢?
- 【自然語言處理 - 概念篇】 詞性標注POS在NLP的世界扮演什麼樣的角色呢?
- 【自然語言處理 - 概念篇】 拆解語句組成的規則, 何謂依存句法分析(Dependency Parsing)?
- 【自然語言處理 - spaCy】初探強大的工具庫spaCy, 讓機器讀懂我們的語言
- 【自然語言處理 - spaCy】善用ChatGPT幫我們訓練出自訂的Name Entity Recognition實體