摘要
隨著大型語言模型(Large Language Models, LLMs)在 2024 年至 2025 年間的參數規模與推論能力飛速增長,其在企業級應用與高風險領域的部署面臨著一個核心障礙:幻覺(Hallucination)。本文檔旨在提供一份詳盡的研究報告,深入探討近期針對「降低」幻覺所提出的新技術、演算法革新及學術論文。報告首先重新定義了幻覺的分類學,特別是針對代理(Agentic)系統的新型態幻覺;接著,深入剖析了目前被視為「最佳解」的混合架構,包括微軟的 GraphRAG、推理時干預(Inference-Time Intervention, ITI)及分層對比解碼(DoLa);最後,基於 Vectara、HalluLens 及 Artificial Analysis 等權威基準,量化分析了當前最先進模型(如 Gemini 3 Pro, GPT-5, Claude 3.5/4.5)的準確率與幻覺率。分析顯示,雖然單一模型在特定任務上的事實一致性已可達 96% 以上,但在廣泛的知識檢索與推理任務中,依賴檢索增強生成(RAG)與校準訓練(Calibration Training)仍是不可或缺的防線。
1. 幻覺的本質與演變:從事實錯誤到代理失控
在探討解決方案之前,必須先理解 2025 年學術界對於「幻覺」定義的典範轉移。早期的研究僅將幻覺視為事實性錯誤,但隨著模型向代理(Agent)化發展,幻覺的定義已擴展至涵蓋邏輯推理斷裂、目標誤解及記憶篡改等多維度失效。
1.1 幻覺分類學的重構:HalluLens 與內外之別
根據 2025 年發布的 HalluLens 基準測試框架,幻覺被嚴謹地劃分為「內在幻覺」(Intrinsic Hallucination)與「外在幻覺」(Extrinsic Hallucination),這一區分對於選擇緩解策略至關重要 [1]。
- 內在幻覺(Intrinsic Hallucination): 指模型生成的內容與當前提供的輸入上下文(Input Context)相矛盾。例如,使用者提供了一份財報顯示「淨利潤為 5 億美元」,模型卻總結為「虧損 2 億美元」。這類錯誤反映了模型在邏輯推理、注意力機制或指令遵循上的失敗。
- 外在幻覺(Extrinsic Hallucination): 指模型生成的內容無法由輸入上下文驗證,且與現實世界的客觀事實或預訓練語料庫相悖。這通常發生在模型試圖「填補空白」時。例如,在沒有相關背景資料的情況下,模型自信地編造了某個不存在的歷史事件細節。外在幻覺更難以檢測,因為它需要外部知識源(Oracle)進行驗證。
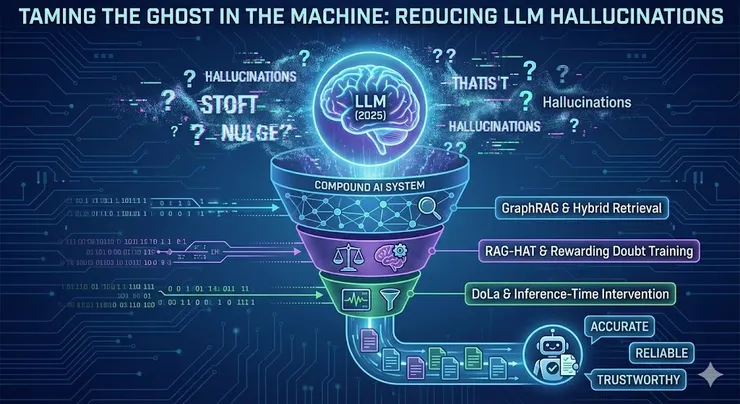
這一分類揭示了當前緩解技術的分野:RAG 技術主要解決外在幻覺,通過引入外部知識來填補空白;而推理時干預(如 DoLa)與校準訓練(如 Rewarding Doubt)則更多地針對內在幻覺與模型自信度的校準。
1.2 代理系統中的幻覺新變種
隨著 LLM 被整合進自主代理系統(Agentic Systems),幻覺的形態變得更加複雜。2025 年的研究指出,代理幻覺不再僅僅是語言錯誤,而是涉及感知、記憶與行動模組的連鎖失效 [3]。

這種分類強調了單純依靠「提示工程」(Prompt Engineering)已不足以解決問題。現代的最佳解必須深入到模型的推理過程與架構層面。
1.3 校準問題:自信與能力的落差
2025 年的研究核心觀點之一是:幻覺本質上是一個校準(Calibration)問題。理想的模型應該具備「蘇格拉底式的智慧」——即知道自己不知道什麼。然而,當前的訓練機制往往獎勵自信的猜測。
OpenAI 在 2025 年 9 月的論文中指出,現有的預訓練與 RLHF(人類回饋強化學習)目標函數,傾向於獎勵那些看起來合理且自信的回答,而非誠實地表達不確定性 [5]。這導致了所謂的「自信-能力落差」(Confidence-Competence Gap)。例如,在 Gemini 3 Pro 的評測中發現,該模型雖然知識淵博,但在面對它不知道的問題時,往往選擇自信地編造答案,導致其在特定的可靠性指標(如 Omniscience Index)上得分偏低 [6]。這表明,降低幻覺的關鍵不僅在於增加知識,更在於讓模型學會「拒絕回答」(Abstention)。
























