當談到大型模型的訓練和推理時,我們經常涉及到精度的概念,而這些精度種類繁多。同等精度級別下,還有不同的格式。然而,網上比較少有全面介紹的文章。在這裡,我將總結一份簡單的介紹。
在電腦領域中,浮點數的儲存方式由三個部分組成:符號位元(sign)、指數位元(exponent)和小數位元(fraction, 理解成小數點後的數)。通常,符號位佔用1位元,指數位元影響浮點數的範圍,而小數位元則影響浮點數的精確度。換句話說,指數位決定了浮點數的級別,而小數位元則決定了浮點數的精細程度。
原理的理解可以參照IEEE 754:
用IEEE754做簡單的解講,讓我們來看看十進位數字 -27.15625 在半精度浮點數 (Half Precision)的計算過程:
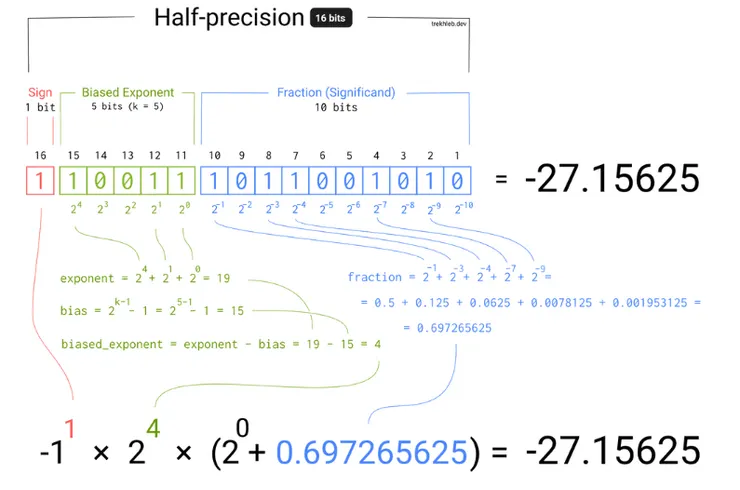
IEEE754 全精度/雙精度線上計算機可以參考:
原始碼有興趣的可以參考這邊:
一些常見的浮點數精度
- 雙精度(FP64):64位浮點數,由1位符號位、11位指數位和52位小數位組成。
- 單精度、全精度(FP32、TF32: A100開始的):32位浮點數,由1位符號位、8位指數位和23位小數位組成。
- 半精度(FP16、BF16):16位浮點數,用於機器學習,由1位符號位、5位指數位和10位小數位組成。
- 8位精度(FP8):非IEEE標準格式,由4位指數和3位尾數(E4M3)或5位指數和2位尾數(E5M2)組成。
- 4位精度(FP4、NF4):NF4是一種用於量化的特殊格式,建立在分位數量化技術的基礎之上。
量化精度(Quantization)
- INT8:8位整數,用於量化,占用1個字節。
- INT4:4位整數,也有其他量化格式(6位、5位甚至3位)。
多精度和混合精度
- 多精度計算:使用不同精度進行計算,選擇最適合的一種。
- 混合精度計算:在單個操作中使用不同的精度級別,實現計算效率,同時不犧牲精度。
特別關注的除了FP32、FP16 之外,nVidia有介紹了A100開始的TF32精度,由於我們多數仍使用nVidia作為計算的硬體,這個TF32非常值得參考與關注(當然你不一定有A100以上的卡片,但仍然應該了解一下該架構):
官網中說到TF32 是 Ampere 世代 GPU 架構中新增到 Tensor Core 的新運算模式。點積計算構成了矩陣乘法和卷積的構建塊,將 FP32 輸入舍入為 TF32,在不損失精度的情況下計算乘積,然後將這些乘累積加到 FP32 輸出中:
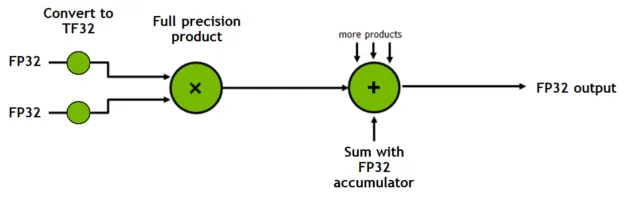
TF32 Tensor Core 操作涉及的指令圖。
A100 Tensor Core 與 FP32 CUDA 核心的數學吞吐量參考如下:
FP32:1x
TF32:8x
FP16 / BF16:16x
各種精準度的比較:
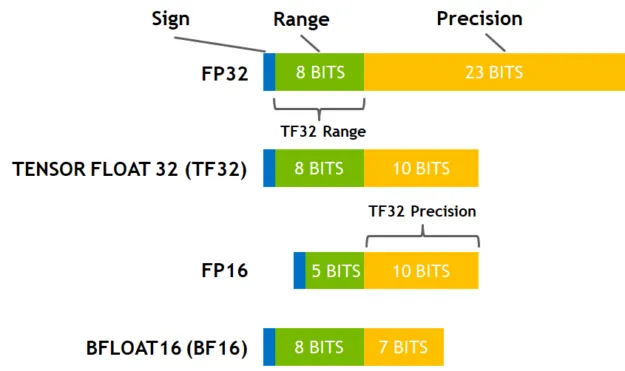
常見 DL 精度格式的符號、範圍和尾數位細分。
TF32模式採用8位指數位、10位尾數和1位符號位。因此,它涵蓋了與 FP32 相同的值範圍。TF32 也保持了比 BF16 更高的精度和與 FP16 相同的精度。TF32 的精度仍然是與 FP32 的唯一區別,經過廣泛的研究,它對於 AI 工作負載具有足夠的餘裕,底下是參考的數據:
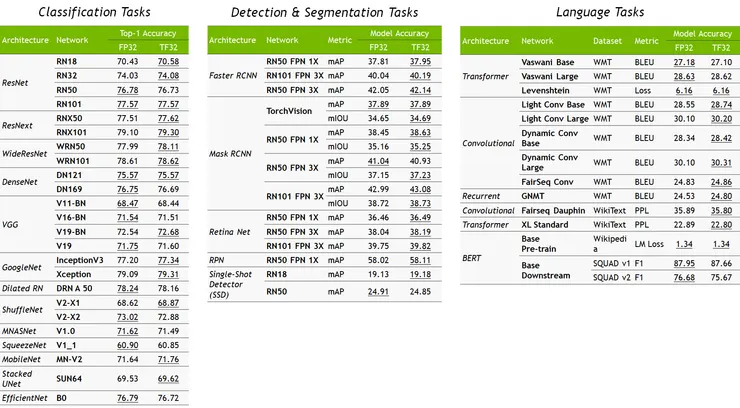
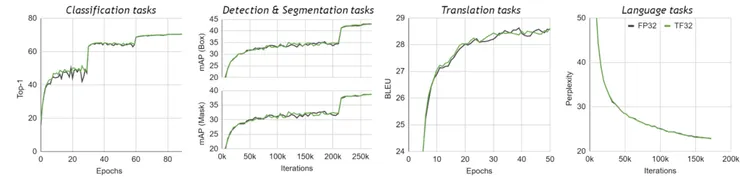
四種不同 AI 工作負載的 FP32 和 TF32 精度曲線。
TF32之後接著要關注的是BF16,Brain Float 16 是由 Google Brain 提出的浮點數格式,專為機器學習而設計。它由以下部分組成:1 位符號位、8 位指數位(與 FP32 相同)和 7 位小數位(低於 FP16)。因此,雖然精度低於 FP16,但其表示範圍與 FP32 相同,並且在 FP32 和 Brain Float 16 之間進行轉換非常容易。bfloat16 格式是一種縮短的IEEE 754 單精度32 位元浮點數,允許與 IEEE 754 單精度 32 位元浮點數之間進行快速轉換;在轉換為 bfloat16 格式時,指數位被保留,而尾數段可以透過截斷(因此對應於向 0 舍入)或其他舍入機制來減少,忽略NaN特殊情況。保留指數位可維持 32 位元浮點數的範圍為 ≈ 10^-38到 ≈ 3 × 10^38。

Bfloat16 – a brief intro - AEWIN
BF16降低了精準度,但可以輕易地與其他格式進行交換,這點在各種不同運算卡之間的通用性變得非常值得關注。
如果在進行LLM finetune時,而你手上卡片記憶體真的不多的時候,嘗試BF16,有些時候可以讓你失敗的訓練重拾成功的可能。實作上,可以透過底下方式確認是否支援bf16,如果是True,那就是恭喜! 不是的話,請........跳過bf16.........
import transformers
transformers.utils.import_utils.is_torch_bf16_gpu_available()
當然我們也可以透過一些指令知道他支援的精確範圍:
import torch
torch.finfo(torch.bfloat16)
回應:
finfo(resolution=0.01, min=-3.38953e+38, max=3.38953e+38, eps=0.0078125, smallest_normal=1.17549e-38, tiny=1.17549e-38, dtype=bfloat16)
可以看出bfloat16的10進位間隔精度為0.01(註:在-1~1之間精確度為0.001),表示範圍是[-3.40282e+38,3.40282e+38]。可以明顯的看到bfloat16比float16精度降低了,但是表示的範圍更大了,能夠有效的防止在訓練過程中的溢出,也因此,我們算是蠻常用到bf16的。
resolution(解析度):這個浮點數類型在十進制上的分辨程度,表示兩個不同值之間的最小間隔。
對於 bf16,解析度是 0.01,就是說兩個不同的 torch.bfloat16 數值之間的最小間隔是 0.01。
min(最小值):對於 torch.bfloat16,最小值是 -3.38953e+38。
max(最大值):對於 torch.bfloat16,最大值是 3.38953e+38。
eps(機器精度):機器精度表示在給定資料類型下,比 1 大的最小浮點數,對於 torch.bfloat16,機器精度是 0.0078125。
smallest_normal(最小正規數):最小正規數是大於零的最小浮點數,對於 torch.bfloat16,最小正規數是 1.17549e-38。
tiny(最小非零數):最小非零數是大於零的最小浮點數,對於 torch.bfloat16,最小非零數也是 1.17549e-38。
實際操作的驗證參考:
上面以常用浮點數精度FP32/FP16/TF32/BF16進行的說明,希望可以讓大家進入AI領域的時候,少點兒麻煩。如果你已經有了基本的應用經驗,有時候會碰到拿到的pretrain model參數超大,無法被我們這種市井小兒的小電腦(像是3060 12G、3070 12G......好一點16G,最高級的像是4090 24G仍然是小小孩的級別-與A100、H100等企業級比較而言)進行finetune時,這時候就是可以參考Quantization使用的時機了。
前面簡單的介紹過量化精度是使用整數去進行的一種精度,作法上就是把浮點數裝箱到整數,就像我們把數字裝箱到0~1、-1~1......的做法,大家可以想像,浮點數列的數值與數值之前的距離可以透過這樣的技巧,被轉換到整數數列中;訓練完之後也可以被依據當時轉換過去的邏輯反轉回原來的浮點數字(Dequantize,反向量化: https://www.tensorflow.org/api_docs/python/tf/quantization/dequantize、https://pytorch.org/docs/stable/generated/torch.dequantize.html、https://docs.nvidia.com/deeplearning/tensorrt/operators/docs/Dequantize.html),雖然你會覺得這樣會產生誤差吧?答案:是的,但有一好沒兩好的選擇下,我們仍然覺得這是非常好的手段之一。使用這樣的精度手段,可以讓我們一般的卡片有機會可以finetune一個13B、17B的適中模型(甚至更高)。以下介紹幾個比較常看到的做法,實際上有更多資源,值得大家去探索:
像這個專案:
GitHub - NetEase-FuXi/EETQ: Easy and Efficient Quantization for Transformers
可以這樣使用:
from eetq.utils import eet_quantize
eet_quantize(torch_model)
他們也提供了使用範例: EETQ/examples/models/llama_transformers_example.py at main · NetEase-FuXi/EETQ · GitHub
實務上的程式碼會大概像這樣:
import torch
from transformers import LlamaForCausalLM, LlamaTokenizer
MAX_NEW_TOKENS = 128
model_name = "meta-llama/Llama-2-7b-hf"
text = "Hamburg is in which country?\n"
tokenizer = LlamaTokenizer.from_pretrained(model_name)
input_ids = tokenizer(text, return_tensors="pt").input_ids
max_memory = f"{int(torch.cuda.mem_get_info()[0]/1024**3)-2}GB"
n_gpus = torch.cuda.device_count()
max_memory = {i: max_memory for i in range(n_gpus)}
model = LlamaForCausalLM.from_pretrained(model_name, device_map="auto", load_in_8bit=True, max_memory=max_memory)
generated_ids = model.generate(input_ids, max_length=MAX_NEW_TOKENS)
print(tokenizer.decode(generated_ids[0], skip_special_tokens=True))
如上面的範例,在model處使用load_in_8bit=True, 詳細的文件可以參考這裡:
如果使用load_in_4bit=True的方法可以透過from transformers import BitsAndBytesConfig這個類別設定,例如:
import torch
from transformers import BitsAndBytesConfig
from transformers import LlamaForCausalLM as ModelCls
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_quant_type="nf4",
bnb_4bit_use_double_quant=True,
)
model: ModelCls = ModelCls.from_pretrained(
"TheBloke/Llama-2-7b-chat-fp16",
device_map="auto",
quantization_config=quantization_config,
)
另外這個專案是蠻常被使用的項目,是一個易於使用的 LLM 量化包,具有用戶友好的 API,基於 GPTQ 演算法(僅權重量化),2023-08-23 - (新聞) - 🤗 Transformers、optimum 和 peft 已集成auto-gptq,因此現在每個人都可以更方便地運行和訓練 GPTQ 模型!:
要使用之前要先安裝:
CUDA 11.8(PyTorch 2.2.1+cu118):
pip install auto-gptq --extra-index-url https://huggingface.github.io/autogptq-index/whl/cu118/
CUDA 12.1(PyTorch 2.2.1+cu121)
pip install auto-gptq
使用經典範例([BUG]CUDA OUT OF MEMORY · Issue #179 · AutoGPTQ/AutoGPTQ · GitHub),SCRIPT說明:
import time
import os
import logging
from transformers import AutoTokenizer, TextGenerationPipeline
from auto_gptq import AutoGPTQForCausalLM, BaseQuantizeConfig
import numpy as np
import torch
import torch.nn as nn
import argparse
def get_wikitext2(nsamples, seed, seqlen, tokenizer):
from datasets import load_dataset
logger = logging.getLogger(__name__)
wikidata = load_dataset('wikitext', 'wikitext-2-raw-v1', split='test')
wikilist = [' \n' if s == '' else s for s in wikidata['text'] ]
text = ''.join(wikilist)
logger.info("Tokenising wikitext2")
trainenc = tokenizer(text, return_tensors='pt')
import random
random.seed(seed)
np.random.seed(0)
torch.random.manual_seed(0)
traindataset = []
for _ in range(nsamples):
i = random.randint(0, trainenc.input_ids.shape[1] - seqlen - 1)
j = i + seqlen
inp = trainenc.input_ids[:, i:j]
attention_mask = torch.ones_like(inp)
traindataset.append({'input_ids':inp,'attention_mask': attention_mask})
return traindataset
def get_c4(nsamples, seed, seqlen, tokenizer):
from datasets import load_dataset
traindata = load_dataset(
'allenai/c4', 'allenai--c4', data_files={'train': 'en/c4-train.00000-of-01024.json.gz'}, split='train', use_auth_token=False
)
import random
random.seed(seed)
trainloader = []
for _ in range(nsamples):
while True:
i = random.randint(0, len(traindata) - 1)
trainenc = tokenizer(traindata[i]['text'], return_tensors='pt')
if trainenc.input_ids.shape[1] >= seqlen:
break
i = random.randint(0, trainenc.input_ids.shape[1] - seqlen - 1)
j = i + seqlen
inp = trainenc.input_ids[:, i:j]
attention_mask = torch.ones_like(inp)
trainloader.append({'input_ids':inp,'attention_mask': attention_mask})
return trainloader
def quantize(model_dir, output_dir, traindataset, bits, group_size, desc_act, damp, batch_size = 1, use_triton=False, trust_remote_code=False, dtype='float16'):
quantize_config = BaseQuantizeConfig(
bits=bits,
group_size=group_size,
desc_act=desc_act,
damp_percent=damp
)
if dtype == 'float16':
torch_dtype = torch.float16
elif dtype == 'float32':
torch_dtype = torch.float32
elif dtype == 'bfloat16':
torch_dtype = torch.bfloat16
else:
raise ValueError(f"Unsupported dtype: {dtype}")
logger.info(f"Loading model from {model_dir} with trust_remote_code={trust_remote_code} and dtype={torch_dtype}")
model = AutoGPTQForCausalLM.from_pretrained(model_dir, quantize_config=quantize_config, low_cpu_mem_usage=True, torch_dtype=torch_dtype, trust_remote_code=trust_remote_code)
logger.info(f"Starting quantization to {output_dir} with use_triton={use_triton}")
start_time = time.time()
model.quantize(traindataset, use_triton=use_triton, batch_size=batch_size)
logger.info(f"Time to quantize model at {output_dir} with use_triton={use_triton}: {time.time() - start_time:.2f}")
logger.info(f"Saving quantized model to {output_dir}")
model.save_quantized(output_dir, use_safetensors=True)
logger.info("Done.")
if __name__ == "__main__":
logger = logging.getLogger()
logging.basicConfig(
format="%(asctime)s %(levelname)s [%(name)s] %(message)s", level=logging.INFO, datefmt="%Y-%m-%d %H:%M:%S"
)
parser = argparse.ArgumentParser(description='quantise')
parser.add_argument('pretrained_model_dir', type=str, help='Repo name')
parser.add_argument('output_dir_base', type=str, help='Output base folder')
parser.add_argument('dataset', type=str, help='Output base folder')
parser.add_argument('--trust_remote_code', action="store_true", help='Trust remote code')
parser.add_argument('--use_triton', action="store_true", help='Use Triton for quantization')
parser.add_argument('--bits', type=int, nargs='+', default=[4], help='Quantize bit(s)')
parser.add_argument('--group_size', type=int, nargs='+', default=[32, 128, 1024, -1], help='Quantize group size(s)')
parser.add_argument('--damp', type=float, nargs='+', default=[0.01], help='Quantize damp_percent(s)')
parser.add_argument('--desc_act', type=int, nargs='+', default=[0, 1], help='Quantize desc_act(s) - 1 = True, 0 = False')
parser.add_argument('--dtype', type=str, choices=['float16', 'float32', 'bfloat16'], help='Quantize desc_act(s) - 1 = True, 0 = False')
parser.add_argument('--seqlen', type=int, default=2048, help='Model sequence length')
parser.add_argument('--batch_size', type=int, default=1, help='Quantize batch size for processing dataset samples')
parser.add_argument('--stop_file', type=str, help='Filename to look for to stop inference, specific to this instance')
args = parser.parse_args()
stop_file = args.stop_file or ""
tokenizer = AutoTokenizer.from_pretrained(args.pretrained_model_dir, use_fast=True, trust_remote_code=args.trust_remote_code)
if args.dataset == 'wikitext':
traindataset = get_wikitext2(128, 0, args.seqlen, tokenizer)
elif args.dataset == 'c4':
traindataset = get_c4(128, 0, args.seqlen, tokenizer)
else:
logger.error(f"Unsupported dataset: {args.dataset}")
raise ValueError(f"Unsupported dataset: {args.dataset}")
abort = False
iterations=[]
for bits in args.bits:
for group_size in args.group_size:
for desc_act in args.desc_act:
for damp in args.damp:
desc_act = desc_act == 1 and True or False
iterations.append({"bits": bits, "group_size": group_size, "desc_act": desc_act, "damp": damp})
num_iters = len(iterations)
logger.info(f"Starting {num_iters} quantizations.")
count=1
for iter in iterations:
if not os.path.isfile("/workspace/gptq-ppl-test/STOP") and not os.path.isfile(stop_file) and not abort:
bits = iter['bits']
group_size = iter['group_size']
desc_act = iter['desc_act']
damp = iter['damp']
output_dir = args.output_dir_base
try:
os.makedirs(output_dir, exist_ok=True)
# Log file has same name as directory + .quantize.log, and is placed alongside model directory, not inside it
# This ensures that we can delete the output_dir in case of error or abort, without losing the logfile.
# Therefore the existence of the output_dir is a reliable indicator of whether a model has started or not.
logger.info(f"[{count} / {num_iters}] Quantizing: bits = {bits} - group_size = {group_size} - desc_act = {desc_act} - damp_percent = {damp} to {output_dir}")
try:
quantize(args.pretrained_model_dir, output_dir, traindataset, bits, group_size, desc_act, damp, args.batch_size, args.use_triton, trust_remote_code=args.trust_remote_code, dtype=args.dtype)
except KeyboardInterrupt:
logger.error(f"Aborted. Will delete {output_dir}")
os.rmdir(output_dir)
abort = True
except:
raise
finally:
count += 1
else:
logger.error(f"Aborting - told to stop!")
break
使用範例:
python3 quant_autogptq.py /workspace/llama-30b /workspace/llama-30b-gptq wikitext --bits 4 --group_size 128 --desc_act 0 --dtype float16
抱抱笑臉上邊也有很多使用GPTQ量化過的模型(Models - Hugging Face),可以直接下載使用。
附帶一提,不只是訓練時需要使用到這種技巧,我們曾經講過的這個專案:
你也可以來這邊參考這個專案中的量化做法,能夠讓你使用更大的模型,消耗更少的記憶體:
簡單講,不管是訓練上的需求或使用模型的需求,有了量化的幫忙,我們都有機會可以使用到超大參數的模型。
如果你嘗試了ollama Quantization過的 4Bit模型,甚至可以將70B的模型載進去32G的GPU裡面運算。














