我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
Transformers for Natural Language Processing and Computer Vision, 2024 這本書中講 Decoder 的部分不是很底層解析,因此今天內容引自台大 李宏毅教授上課內容。
首先解釋何謂 Decoder 是基於 Auto-Regressive Model
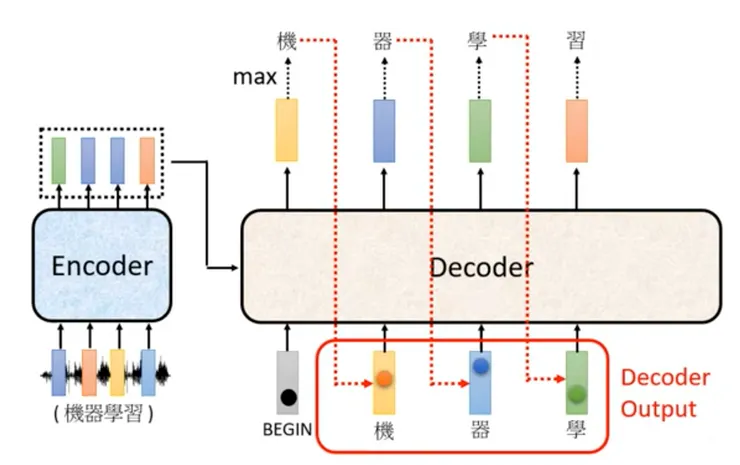
- 假設輸入一段「機器學習」的聲音,希望做語音辨識,而且目前已經執行完 Encoder 部分,關於 Encoder 部分參見 AI說書 - 從0開始 - 39 至 AI說書 - 從0開始 - 65
- Decoder 首先輸入 Begin Token ,同時匯入 Encoder 的精華資訊,預期第一個字經過 Softmax 操作後會得到「機」,接著將輸出的「機」,再匯入 Decoder ,預期第二個字經過 Softmax 會得到「器」,以此類推,這種 Uses the previous output sequences as an additional input 的機制稱為 Auto-Regressive Model
注意在 Encoder 時做的是 Multi-Head Attention,而在 Decoder 時做 Masked Multi-Head Attention,我們來說明其差異:
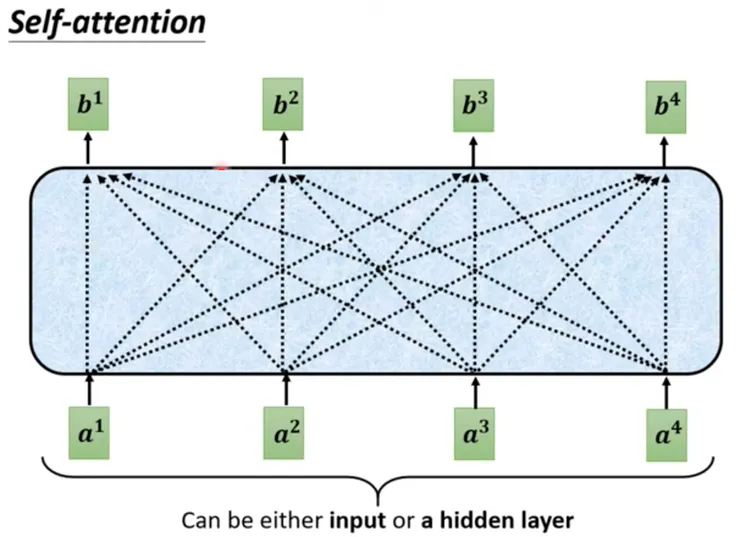
- 左圖是我們在 AI說書 - 從0開始 - 52 中提及的 Attention 機制,注意 b1 產生的過程是參閱了 a1、a2、a3、a4
- 但是我們剛剛說 Decoder 是基於 Auto-Regressive Model,因此 Decoder 在產生 b2 時只能參閱 a1,同理產生 b3 時只能參閱 a1、a2,以此類推,不可以偷看未來的結果,因此 Decoder 的 Attention 機制變成下圖:
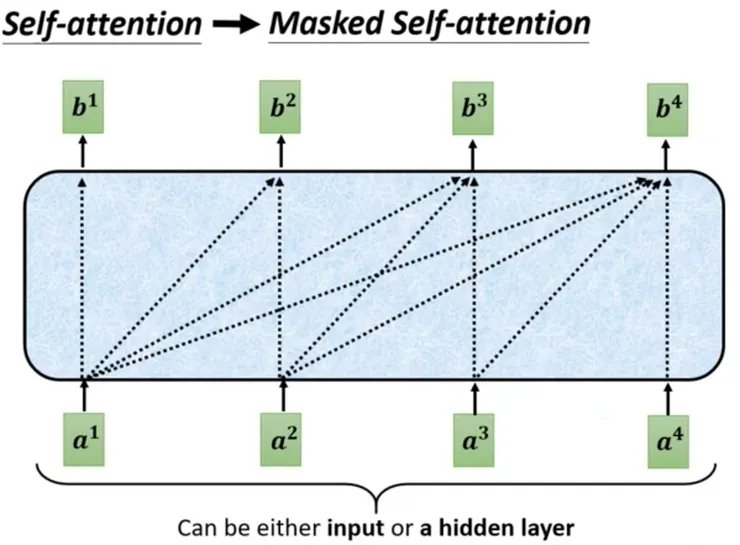
- 左圖是 Decoder 中的 Attention 機制,多加上一個關鍵字「Masked」,旨在說明:當下產生結果的過程不可以偷看未來的輸入
以上是概覽,現在來看具體機制,何謂不可以偷看:
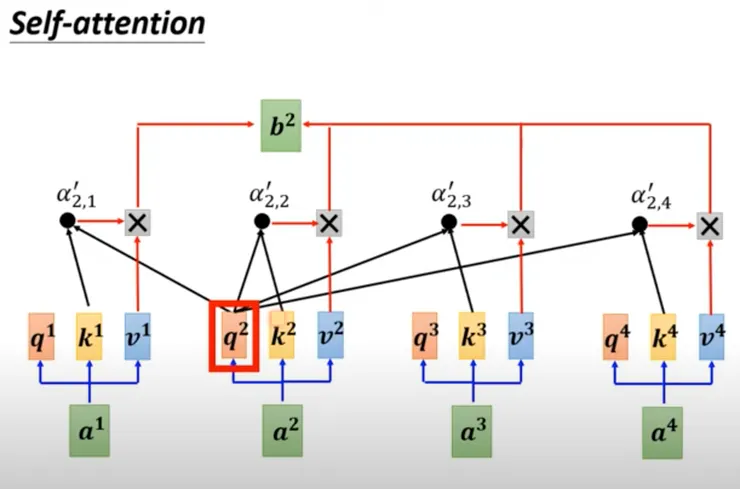
- 回顧 AI說書 - 從0開始 - 52,我們說 b2 產生的過程是使用 q2 然後參閱k1、k2、k3、k4、v1、v2、v3、v4
- 但是我剛剛說不可以偷看未來的資訊,因此變成下圖的 Masked Self-Attention:
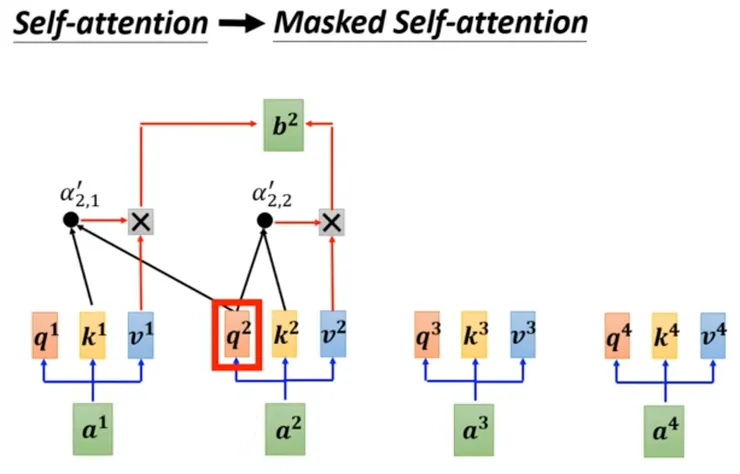
- b2 產生的過程是使用 q2 然後參閱k1、k2、v1、v2
可以看到這樣就是類似文字接龍的過程,那究竟什麼狀況會讓 Decoder 終止輸出呢?
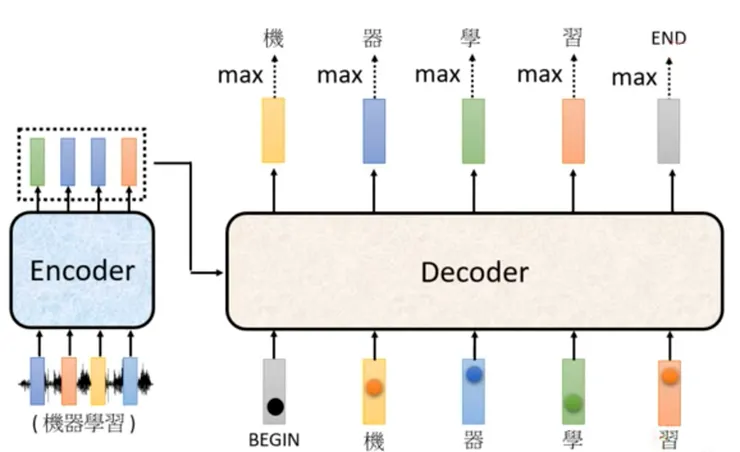
- 事實上機器學習模型中,除了字典中所有的文字之外,尚會納入 Begin Token 與 End Token,如此一來當「習」這個字匯入 Decoder,產生 End Token 時,就宣告整體文字接龍過程結束














