文前碎碎唸
「人工智障計畫」也執行了好一段時間了,關於這個專案中文字轉語音的方案,在之前的筆記中也有稍微提到,為了達成能自訂聲線,並且能完全離線運作兩個條件,我已經做過了不少嘗試。

最終,我選擇了 VITS 模型作為原本 GTTS 的替代方案,並且也成功讓它在新的硬體上運作了一段時間。
而近期剛好遇到電腦更換及維修,作業環境必須重新設置,一切幾乎從零開始。在我翻著白眼,把所有相關套件一一裝回來,並面對各種相容性問題的同時,我也在思考著,不如就藉此機會,將環境設置與訓練的流程紀錄一下吧!
模型與工具
在開始之前首先要提起的是,VITS 是一種文字轉語音的 Text-to-Speech(TTS)技術,由 Google AI 團隊開發。其合成的語音具有高品質、自然流暢的特點,可以用作智慧助理、有聲書籍等應用。
而這次的模型訓練,要使用的是 VITS-fast-fine-tuning 這個工具,它將 VITS TTS 模型的訓練流程簡化,並透過對既有模型的微調來省去從頭開始的痛苦,並降低了整體運算資源的需求。

雖然這個專案本身有提供 Colab 版本,讓使用者可以直接使用 Google 雲端資源來執行,但說實在 Google 免費版雲端所提供的資源真的十分有限。
一來是訓練所需的原始音訊跟中間所產出的暫存很容易就會塞爆空間,二來是雲端訓練時間有限制,無法真正有效率的將模型微調到滿意的狀態,因此我們就來直接在自己的機器上執行。
不過在開始之前,有些事情要注意,這次使用的工具對相關套件的版本要求頗嚴格,因此建議直接使用說明中指定的方式做安裝。
著手環境
關於本機端訓練環境的相關設定流程,在工具頁面中都有已經有蠻詳細的介紹。
基本上只要硬體與系統方面設定正確的話,直接按照說明中的指令逐步執行即可。不過為了註記實作時踩到的雷點,這裡我還是將建立環境時的參數簡單做一下紀錄。
硬體與系統
這裡先假設大家手邊都已經有一台具備 NVIDIA 顯示卡的電腦。

這裡我使用的參考硬體是 ROG G14 電競筆電,處理器為 AMD Ryzen 9 並具備 GeFoorce RTX-4080 顯示卡。
顯卡驅動
根據說明中所需要的是 Cuda 11.6 或 11.7 版本,若尚未安裝 Cuda 的話,可以到這裡選擇與自己電腦相對應的系統下載安裝檔。

軟體環境
接著要確認電腦中安裝且執行的環境是 Python 3.8 版本,建議直接建立額外的虛擬環境來做區隔。
我已試過直接以新的 3.11 版本做設定,但會卡死在找不到相應套件版本的錯誤。

如果是跟我一樣使用 Anaconda 工具來安裝 Python 的朋友,可以直接開啟 Anaconnda Navigator,並從 Enviroments > Create 選項建立。
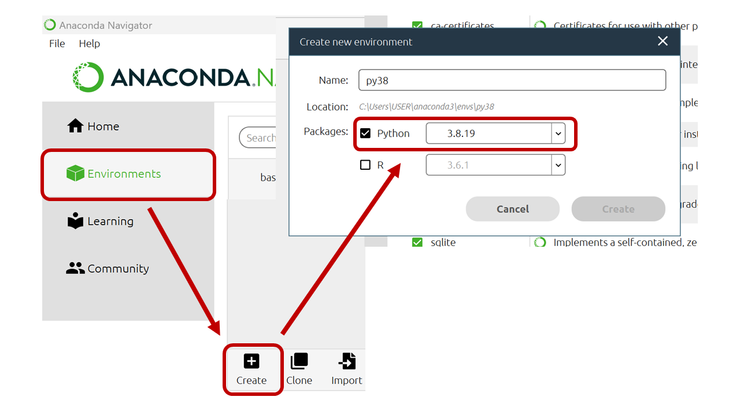
接著從環境選單中,選擇剛剛建立的 Python 3.8 並點一下 Open Terminal 即可開啟命令視窗。

再來要安裝 Microsoft C++ Build Tools 跟 CMake Pacakge,其中 C++ Build Tools 可以到這裡下載。

而 CMake 則是直接用 pip install cmake 指令安裝即可。
工具設定
最後就可以從 Github 上將 Repo 下載回來,在目錄下執行 pip install -r requirements.txt 指令,進行所需套件的安裝。
接著根據電腦上所安裝的顯卡驅動類型,來選擇適用的 GPU 版本 PyTorch,目前我電腦上已經裝好的是 CUDA 11.7,因此直選則說明中標示 # CUDA 11.7 的指令執行即可。
pip install torch==1.13.1+cu117 torchvision==0.14.1+cu117 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu117
正常來說,如果前置的系統環境設定皆正確的話,應該就能順利完成安裝,接下來就只要依照順序執行後續指令,直到第 7 步驟為止。
不過要注意的是,如果是在 Windows 環境下,直接輸入第 6 步驟中的 wget 跟 unzip 兩個動作的話,可能會出現無法執行的錯誤。

這時可以直接手動從 wget 後面的網址下載 sampled_audio4ft_v2.zip 這個檔案後,再解壓縮到工具目錄下即可。
到這裡,基本的設定就已完成,接著就可以開始準備訓練了。
訓練準備
還記得前段最後停在說明文件的第 7 步驟,是因為從這裡開始就是要下載預訓練模型了,而文件中將這個步驟分歧為 Windows 與 Linux 兩部分進行說明。
預訓練模型
不過如果仔細觀察,其差異應該就跟前面環境設定中所遇到的 wget 指令無法在 Windows 上執行的問題相同。
如果是使用 Windows 系統的話,就必須手動至指令中的
[https://DOWNLOAD_FROM_THIS_URL]
網址進行下載模型檔,重新命名成
[NEW_FILE_NAME]
後放到 pretrained_models 資料夾底下。
網址與名稱於指令中的位置,如下列範例所示。
wget [https://DOWNLOAD_FROM_THIS_URL] -O ./pretrained_models/[NEW_FILE_NAME]
模型部分則是有分為三種,分別代表不同支援的語言。
- CJE: 中文 / 日文 / 英文
- CJ: 中文 / 日文
- C: 中文
可以依照需求擇一下載使用,每種模型皆包含 D_*.pth、G_*.pth、config.json 三個檔案,下載下來後請依指示將三個檔案分別命名,並放到指定資料夾裡。
- 原始檔名 → 新檔名 [放置資料夾]
- D_*.pth → D_0.pth [pretrained_models]
- G_*.pth → G_0.pth [pretrained_models]
- config.json → finetune_speaker.json [configs]
完成後,就可以基於這些基本模型進行聲音微調啦。
材料準備
最重要的訓練材料部份,這套工具貼心的支援了三種不同來源可供選擇,除了可以使用單個較長,或是多個 10 秒內的短音訊檔外,還可以支援影片檔案或是網址的輸入,不過網址部分在文件中提到目前僅支援 Bilibili,不確定其他來源是否可以使用。
而這裡為避免侵犯他人權益,我是使用自己之前的 Podcast 純人聲錄音檔,在稍作聲音調整後,直接作為來源進行訓練,畢竟聲音複製這檔事還算是有爭議,還是小心點處理比較好。
接下來的準備步驟,我是以長音訊檔作處理範例,其他來源可參考說明文件。
準備好聲音來源後,先將檔案轉換成 WAV 格式,以 [ 角色名稱_隨機數字 ] 的格式來命名,並放到 raw_audio 這個資料夾中。

接著就可以開始對資料進行處理跟標註等前處理,從指令中可以觀察到,它的流程應該是先對聲音檔進行降噪後,在用 Whisper 做文字標註,再將檔案與註記分段為訓練資料。
python scripts/denoise_audio.py
python scripts/long_audio_transcribe.py --languages "{PRETRAINED_MODEL}" --whisper_size {WHISPER_MOD_SIZE}python scripts/resample.py
## 如果不需要加入輔助訓練資料
python preprocess_v2.py --languages "{PRETRAINED_MODEL}"
## 如果要加入輔助訓練資料
python preprocess_v2.py --add_auxiliary_data True --languages "{PRETRAINED_MODEL}"
這段指令中,需要修改的部分就是 {PRETRAINED_MODEL} 這部分,要替換成先前下載的預訓練模型縮寫,像是如果使用 中日英 模型的話,就要換成 "CJE"。
另外就是 {WHISPER_MOD_SIZE} 這部分,說明文件中預設是使用 large 進行標註,但使用的前提是電腦的 GPU 必須要具備有至少 12 GB 的記憶體可以使用,不然就要改用 medium 或是 small 模型,避免記憶體不足。
插曲
雖然說資料準備所使用的指令看似相當簡單,但其實在實際執行時也遇到了不少插曲。
像是在首次執行第二條標註指令時,系統卻報出未找到檔案的錯誤,而經追查後,確定是因為 Whisper 所依賴的 Ffmpeg 沒有安裝好所致,如果在資料準備過程中有遇到相關問題的話,也可以往這方面嘗試 Debug 看看。
另外還有一點,不確定是否是因為 Whisper 模型改版的關係,雖然理論上模型會自己判斷繁簡字,但這次標註所識別出來的句子,大概八到九成都是簡體的。

雖然不確定對於後續推論時的影響,但考慮使用習慣,還是決定先進行轉換,後來上網查閱了一些資料,也順利找到應對的方案,不過會需要對工具的程式進行一些修改。
首先要目錄中找到 scripts 資料夾。

進入後可以看到一些程式的本體檔案,應該分別可以對應到前面所執行的指令。
像是在這次範例中用來標註長語音的,就是 long_audio_transcribe.py 這個檔案。
而這裡就要針對這些標註用的工具做修改,先使用習慣的 Python IDE 或是文字編輯器打開後,找到下面這一句,大約在 41 行左右。
result = model.transcribe(parent_dir + file, word_timestamps=True, **transcribe_options)
這一行就是針對轉文字功能進行參數設置的步驟,我們要在這裡多插入一段引導用的 initial_prommpt 參數,內容應該沒有限定,唯一要求就是要用繁體中文輸入。
result = model.transcribe(parent_dir + file, word_timestamps=True, initial_prompt='請使用繁體中文的語音辨識。', **transcribe_options)
改完儲存後重新執行一次。

這樣就可以看到標註出來的句子變成繁體中文囉,不這個解決方案雖然對我這段基本上就只有中文的錄音,可能比較沒關係,但如果是多語言混雜的就不確定了,使用上還是要稍微留心。
接下來就可以執行下去讓他生成訓練資料,沒意外的話就能開始訓練啦。
微調訓練
最後一步,其實就只需要輸入一條指令,就可以開始模型的訓練。
python finetune_speaker_v2.py -m ./OUTPUT_MODEL --max_epochs "{Maximum_epochs}" --drop_speaker_embed True
這裡唯一要修改的就是 {Maximum_epochs} 這個參數了,也就是你想要執行的訓練循環次數,基本上訓練循環越多,音色及語調也會越接近你的原始資料,說明中是建議設定成 100 或以上。
這裡我就先給它跑個 200 輪,執行後如果沒有特別出現錯誤訊息的話,就可以先把螢幕關上,打包出門喝個咖啡、繞個兩圈在洗洗睡囉,畢竟雖然是模型微調,但還是需要不少時間來執行的。
如果中間真的心癢癢,想要先觀察目前的訓練情況的話,可以「另外開一個命令視窗」並執行下列指令。
tensorboard --logdir=./OUTPUT_MODEL
接著來到自己慣用的瀏覽器,在網址列輸入 localhost:6006 之後,就可以從 Tensor Board 看到訓練情況囉。

如果順利完成的話,就可以獲得一份基於 VITS 的文字轉語音模型了。
模型推論
訓練完成後,當然就是要實際用用看啦,輸出後的模型會被放在 OUTPUT_MODEL 這個資料夾中,點進去後只要抓出 D_latest.pth、G_latest.pth 以及 config.json 三個檔案即可推論使用。

另外在工具說明文件中,有提供幾個可以用來測試模型的工具可以參考,我個人則是使用另外 vits-simple-api 這個工具來做聲音的合成。
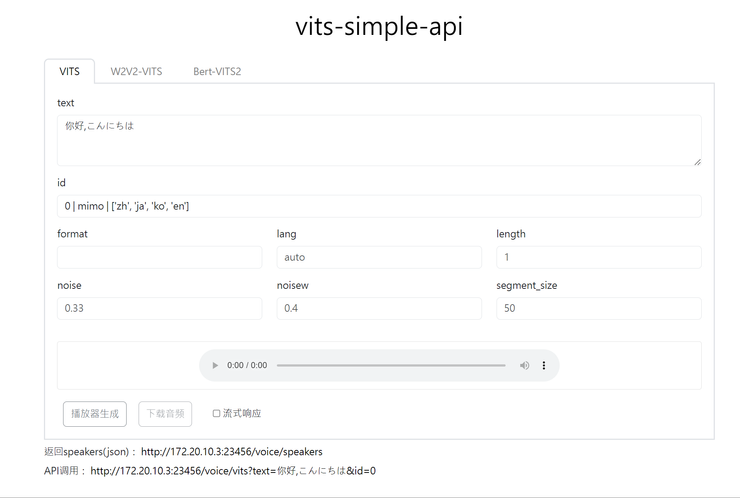
簡單來說,這是一款能簡化模型操作流程,讓使用者可以透過網頁介面或是 API 來取用模型生成結果聲音的東西。
不過這裡因為篇幅關係便不多作介紹,在 Repo 文件中皆有說明模型替換步驟,有興趣的朋友可以自行研究一下。
以上,就是快速訓練自己的 VITS 語音合成模型的筆記拉。
結語
所謂斯斯有三種(絕對沒業配),人有百百樣,文字轉語音模型,當然也不只有 VITS 一個可以使用,只是這次剛好殺出一個能有效將門檻降低,且效果依然不錯的解決方案,才決定踏入嘗試。
不過,以這套方案訓練出來的模型,依然還是有幾個小缺點,或許是因為微調基礎模型的緣故,就算使用自己的聲音進行訓練,實際由模型所推論出來的感覺,跟「正版」間還是會有明顯的口音跟語調差異。
而且中、日、英不同語言合成的感覺都有所不同,但也不是不自然,就是有種說不上來的怪異,或許是互相干擾的結果,但由於目前還沒測試其他基礎模型,所以也不得而知了。
總之,透過這個方式,我的「人工智障」專案也成功獲得了自己的聲音了,真是可喜可賀呢。
《全文。終了》



















