
原文来自于:
https://semianalysis.com/2025/01/31/deepseek-debates/
DeepSeek Debates: Chinese Leadership On Cost, True Training Cost, Closed Model Margin Impacts H100 Pricing Soaring, Subsidized Inference Pricing, Export Controls, MLA
The DeepSeek Narrative Takes the World by Storm
DeepSeek took the world by storm. For the last week, DeepSeek has been the only topic that anyone in the world wants to talk about. As it currently stands, DeepSeek daily traffic is now much higher than Claude, Perplexity, and even Gemini.
But to close watchers of the space, this is not exactly “new” news. We have been talking about DeepSeek for months (each link is an example). The company is not new, but the obsessive hype is. SemiAnalysis has long maintained that DeepSeek is extremely talented and the broader public in the United States has not cared. When the world finally paid attention, it did so in an obsessive hype that doesn’t reflect reality.
We want to highlight that the narrative has flipped from last month, when scaling laws were broken, we dispelled this myth, now algorithmic improvement is too fast and this too is somehow bad for Nvidia and GPUs.
The narrative now is that DeepSeek is so efficient that we don’t need more compute, and everything has now massive overcapacity because of the model changes. While Jevons paradox too is overhyped, Jevons is closer to reality, the models have already induced demand with tangible effects to H100 and H200 pricing.
DeepSeek and High-Flyer
High-Flyer is a Chinese Hedge fund and early adopters for using AI in their trading algorithms. They realized early the potential of AI in areas outside of finance as well as the critical insight of scaling. They have been continuously increasing their supply of GPUs as a result. After experimentation with models with clusters of thousands of GPUs, High Flyer made an investment in 10,000 A100 GPUs in 2021 before any export restrictions. That paid off. As High-Flyer improved, they realized that it was time to spin off “DeepSeek” in May 2023 with the goal of pursuing further AI capabilities with more focus. High-Flyer self funded the company as outside investors had little interest in AI at the time, with the lack of a business model being the main concern. High-Flyer and DeepSeek today often share resources, both human and computational.
DeepSeek now has grown into a serious, concerted effort and are by no means a “side project” as many in the media claim. We are confident that their GPU investments account for more than $500M US dollars, even after considering export controls.
Let me provide a careful translation of this text into Simplified Chinese:
關於DeepSeek深度探索的辯論:中國在成本方面的領先地位、真實訓練成本、封閉模型利潤影響H100價格飆升、補貼推理定價、出口管制、MLA
DeepSeek話題席捲全球
DeepSeek引起了全球轟動。在過去的一週裡,DeepSeek成為了全世界唯一想談論的話題。目前,DeepSeek的日均流量已經遠遠超過Claude、Perplexity,甚至Gemini。
但對於該領域的密切關注者來說,這並非"新聞"。我們已經討論DeepSeek數月之久(每個連結都是一個例子)。這家公司並不新,但瘋狂的炒作卻是新現象。 SemiAnalysis一直認為DeepSeek極具才華,而美國大眾在此之前並不關心。當世界終於開始關注時,卻以一種不反映現實的瘋狂炒作方式進行。
我們想強調的是,敘事已經從上個月的"擴展定律被打破"轉變了,我們駁斥了這個說法,現在演算法改進太快,這似乎也對英偉達和GPU不利。現在的敘事是DeepSeek效率如此之高,以至於我們不需要更多運算能力,而且由於模型的變化,現在一切都出現了大量過剩產能。雖然傑文斯悖論也被過度炒作,但傑文斯更接近現實,這些模型已經在H100和H200的定價上產生了實際的需求效應。
DeepSeek與幻方量化
幻方是一家中國對沖基金,也是在交易演算法中使用AI的早期採用者。他們早期就意識到AI在金融以外領域的潛力以及擴展的關鍵洞見。因此,他們一直持續增加GPU供應。在使用數千個GPU叢集進行模型實驗後,幻方在2021年投資了10,000個A100GPU,*這是在美國施加出口限制之前*。這個投資得到了回報。
隨著幻方的進步,他們意識到是時候在2023年5月分拆出"DeepSeek",目標是更專注地追求AI能力。由於當時外部投資者對AI興趣不大,主要擔憂是缺乏商業獲利模式,因此幻方對專案進行了自籌資金。
如今幻方和DeepSeek經常共享資源,包括人力和運算資源。
DeepSeek現已發展成為一個嚴肅的、協調一致的努力,絕非媒體所稱的"副業項目"。我們相信,即使考慮到出口管制,他們在GPU上的投資也超過5億美元。

The GPU Situation
We believe they have access to around 50,000 Hopper GPUs, which is not the same as 50,000 H100, as some have claimed. There are different variations of the H100 that Nvidia made in compliance to different regulations (H800, H20), with only the H20 being currently available to Chinese model providers today. Note that H800s have the same computational power as H100s, but lower network bandwidth.
We believe DeepSeek has access to around 10,000 of these H800s and about 10,000 H100s. Furthermore they have orders for many more H20’s, with Nvidia having produced over 1 million of the China specific GPU in the last 9 months. These GPUs are shared between High-Flyer and DeepSeek and geographically distributed to an extent. They are used for trading, inference, training, and research. For more specific detailed analysis, please refer to our Accelerator Model.
GPU情況我們認為他們擁有約50,000個Hopper GPU,這與一些人聲稱的50,000個H100不同。英偉達為了遵守不同的法規製造了多個H100變體(H800、H20),目前中國AI模型提供者只能獲得H20。需要注意的是,H800的運算能力與H100相同,但網路頻寬較低。
我們認為DeepSeek可以使用大約10,000個H800和約10,000個H100。
此外,他們還訂購了更多H20,英偉達在過去9個月裡已經生產了超過100萬個專供中國市場的GPU。這些GPU在幻方和DeepSeek之間共享,並在地理位置上有所分佈。它們被用於交易、推理、訓練和研究。關於更具體的詳細分析,請參考我們的加速器模型。
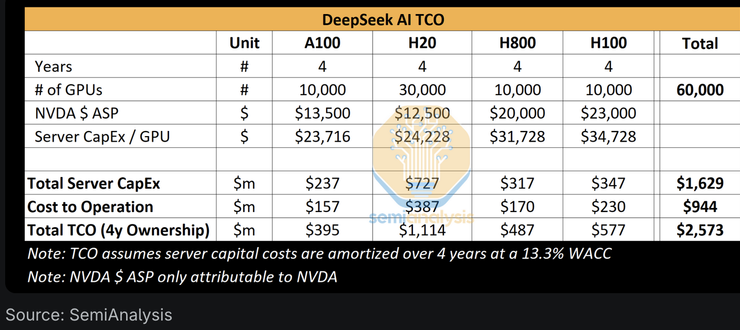
Source: SemiAnalysis, Lennart Heim
Our analysis shows that the total server CapEx for DeepSeek is ~$1.6B, with a considerable cost of $944M associated with operating such clusters. Similarly, all AI Labs and Hyperscalers have many more GPUs for various tasks including research and training then they they commit to an individual training run due to centralization of resources being a challenge. X.AI is unique as an AI lab with all their GPUs in 1 location.
DeepSeek has sourced talent exclusively from China, with no regard to previous credentials, placing a heavy focus on capability and curiosity. DeepSeek regularly runs recruitment events at top universities like PKU and Zhejiang, where many of the staff graduated from. Roles are not necessarily pre-defined and hires are given flexibility, with jobs ads even boasting of access to 10,000s GPUs with no usage limitations. They are extremely competitive, and allegedly offer salaries of over $1.3 million dollars USD for promising candidates, well over the competing big Chinese tech companies and AI labs like Moonshot. They have ~150 employees, but are growing rapidly.
As history shows, a small well-funded and focused startup can often push the boundaries of what’s possible. DeepSeek lacks the bureaucracy of places like Google, and since they are self funded can move quickly on ideas. However, like Google, DeepSeek (for the most part) runs their own datacenters, without relying on an external party or provider. This opens up further ground for experimentation, allowing them to make innovations across the stack.
We believe they are the single best “open weights” lab today, beating out Meta’s Llama effort, Mistral, and others.
我們的分析顯示,DeepSeek的伺服器總資本支出約為16億美元,營運這些集群的相關成本高達9.44億美元。同樣,由於資源集中化是一個挑戰,所有AI實驗室和超大規模企業用於研究和訓練的GPU數量都遠超過他們承諾用於單次訓練的數量。 X.AI作為一個AI實驗室比較特殊,其所有GPU都集中在一個位置。
DeepSeek完全從中國招募人才,不過度看重以往資歷,而是高度重視能力與好奇心。 DeepSeek定期在北大和浙江大學等頂尖高校舉辦招募活動,許多員工都是這些學校的畢業生。職位不一定預先定義,新員工會獲得彈性,招募廣告甚至宣傳可以不受限制地使用數萬個GPU。他們提供的薪資極具競爭力,據稱對有潛力的候選人提供超過130萬美元的年薪,遠超其他中國大型科技公司和Moonshot等AI實驗室。他們目前有約150名員工,但正在快速擴張。歷史表明,一個資金充足且專注的小型新創公司往往能夠推動可能性的邊界。 DeepSeek沒有谷歌那樣的官僚作風,而且由於是自籌資金,可以快速推進想法。然而,和Google一樣,DeepSeek(在大多數情況下)經營自己的資料中心,不依賴外部方或供應商。這為實驗開闢了更多空間,使他們能夠在整個技術堆疊上進行創新。我們認為他們是當今最好的"開放權重"實驗室,超越了Meta的Llama專案、Mistral和其他機構。
DeepSeek’s Cost and Performance
DeepSeek’s price and efficiencies caused the frenzy this week, with the main headline being the “$6M” dollar figure training cost of DeepSeek V3. This is wrong. This akin to pointing to a specific part of a bill of materials for a product and attributing it as the entire cost. The pre-training cost is a very narrow portion of the total cost.
Training Cost
We believe the pre-training number is nowhere the actual amount spent on the model. We are confident their hardware spend is well higher than $500M over the company history. To develop new architecture innovations, during the model development, there is a considerable spend on testing new ideas, new architecture ideas, and ablations. Multi-Head Latent Attention, a key innovation of DeepSeek, took several months to develop and cost a whole team of manhours and GPU hours.
The $6M cost in the paper is attributed to just the GPU cost of the pre-training run, which is only a portion of the total cost of the model. Excluded are important pieces of the puzzle like R&D and TCO of the hardware itself. For reference, Claude 3.5 Sonnet cost $10s of millions to train, and if that was the total cost Anthropic needed, then they would not raise billions from Google and tens of billions from Amazon. It’s because they have to experiment, come up with new architectures, gather and clean data, pay employees, and much more.
So how was DeepSeek able to have such a large cluster? The lag in export controls is the key, and will be discussed in the export section below.
Closing the Gap – V3’s Performance
V3 is no doubt an impressive model, but it is worth highlighting impressive relative to what. Many have compared V3 to GPT-4o and highlight how V3 beats the performance of 4o. That is true but GPT-4o was released in May of 2024. AI moves quickly and May of 2024 is another lifetime ago in algorithmic improvements. Further we are not surprised to see less compute to achieve comparable or stronger capabilities after a given amount of time. Inference cost collapsing is a hallmark of AI improvement.
DeepSeek的成本和性能DeepSeek的價格和效率本週引發了轟動,主要頭條是DeepSeekV3的"600萬美元"訓練成本。這是錯誤的。這就像是指向產品物料清單的某個特定部分,並將其視為全部成本。預訓練成本只是總成本中很小的一部分。
訓練成本
我們認為預訓練數字遠低於模型的實際支出。我們確信他們在公司歷史上的硬體支出遠遠超過5億美元。在開發新架構創新時,模型開發過程中需要大量支出來測試新想法、新架構概念和消融實驗。多頭潛在註意力機制(Multi-Head Latent Attention)是DeepSeek的關鍵創新,花了數月時間開發,消耗了整個團隊大量的人力時間和GPU運算時間。
論文中提到的600萬美元成本僅指預訓練運行的GPU成本,這只是模型總成本的一部分。其中不包括研發和硬體本身的總擁有成本(TCO)等重要組成部分。作為參考,Claude 3.5 Sonnet的訓練成本達數千萬美元,如果這就是Anthropic所需的全部成本,他們就不會從谷歌籌集數十億美元,從亞馬遜籌集數百億美元。這是因為他們需要進行實驗、設計新架構、收集和清理資料、支付員工薪水等等。
那麼DeepSeek是如何擁有如此大規模的顯示卡與算力呢?美國出口管制的滯後性是關鍵,這將在下面的出口管制部分討論。
DEEPSEEK 縮小差距 – V3的效能令人印象深刻
V3無疑是一個令人印象深刻的模型,但值得強調的是相對於什麼而言令人印象深刻。許多人將V3與GPT-4o進行比較,並強調V3如何超越了4o的表現。這是事實,但GPT-4o是在2024年5月發布的。 AI發展迅速,2024年5月在演算法改進方面已經是很久以前的事了。
此外,在給定時間後,看到使用更少的運算資源就能達到相當或更強的能力,這並不令我們驚訝。推理成本的下降是AI進步的標誌。

Source: SemiAnalysis
An example is small models that can be run on laptops have comparable performance to GPT-3, which required a supercomputer to train and multiple GPUs to inference. Put differently, algorithmic improvements allow for a smaller amount of compute to train and inference models of the same capability, and this pattern plays out over and over again. This time the world took notice because it was from a lab in China. But smaller models getting better is not new.
舉個例子,能在筆記型電腦上運行的小型模型,其性能可以與需要超級電腦訓練和多個GPU進行推理的GPT-3相媲美。換句話說,演算法改進使得訓練和推理相同能力的模型所需的計算量更少,這種模式反覆出現。這次世界格外關注是因為這來自於一個中國的實驗室。但小模型變得更好並不是什麼新鮮事。

Source: SemiAnalysis, Artificialanalysis.ai, Anakin.ai, a16z
So far what we’ve witnessed with this pattern is that AI labs spend more in absolute dollars to get even more intelligence for their buck. Estimates put algorithmic progress at 4x per year, meaning that for every passing year, 4x less compute is needed to achieve the same capability. Dario, CEO of Anthropic argues that algorithmic advancements are even faster and can yield a 10x improvement. As far as inference pricing goes for GPT-3 quality, costs have fallen 1200x.
When investigating the cost for GPT-4, we see a similar decrease in cost, although earlier in the curve. While the decreased difference in cost across time can be explained by no longer holding the capability constant like the graph above. In this case, we see algorithmic improvements and optimizations creating a 10x decrease in cost and increase in capability.
到目前為止,我們觀察到的模式是,AI實驗室在絕對支出上投入更多,以獲得*更高*的智慧投資回報。估計演算法進步每年達到4倍,這意味著每過一年,實現相同能力所需的計算量就減少4倍。 Anthropic的CEO Dario認為演算法進步甚至更快,可以帶來10倍的提升。就GPT-3等級的推理定價而言,成本已經下降了1200倍。在研究GPT-4的成本時,我們看到類似的成本降低趨勢,儘管處於曲線的早期階段。雖然隨時間推移成本差異的減少可以解釋為不再像上圖那樣保持固定的能力。在這種情況下,我們看到演算法改進和最佳化創造了10倍的成本降低和能力提升。

Source: SemiAnalysis, OpenAI, Together.ai
To be clear DeepSeek is unique in that they achieved this level of cost and capabilities first. They are unique in having released open weights, but prior Mistral and Llama models have done this in the past too. DeepSeek has achieved this level of cost but by the end of the year do not be shocked if costs fall another 5x.
Is R1’s Performance Up to Par with o1?
On the other hand, R1 is able to achieve results comparable to o1, and o1 was only announced in September. How has DeepSeek been able to catch up so fast?
The answer is that reasoning is a new paradigm with faster iteration speeds and lower hanging fruit with meaningful gains for smaller amounts of compute than the previous paradigm. As outlined in our scaling laws report, the previous paradigm depended on pre-training, and that is becoming both more expensive and difficult to achieve robust gains with.
The new paradigm, focused on reasoning capabilities through synthetic data generation and RL in post-training on an existing model, allows for quicker gains with a lower price. The lower barrier to entry combined with the easy optimization meant that DeepSeek was able to replicate o1 methods quicker than usual. As players figure out how to scale more in this new paradigm, we expect the time gap between matching capabilities to increase.
Note that the R1 paper makes no mention of the compute used. This is not an accident – a significant amount of compute is needed to generate synthetic data for post-training R1. This is not to mention RL. R1 is a very good model, we are not disputing this, and catching up to the reasoning edge this quickly is objectively impressive. The fact that DeepSeek is Chinese and caught up with less resources makes it doubly impressive.
But some of the benchmarks R1 mention are also misleading. Comparing R1 to o1 is tricky, because R1 specifically doesn’t mention benchmarks that they are not leading in. And while R1 matches in reasoning performance, it’s not a clear winner in every metric and in many cases it is worse than o1.
需要明確的是,DeepSeek獨特之處在於他們首先達到了這種成本和能力水準。他們發布開放權重的做法很獨特,但先前Mistral和Llama模型也這樣做過。 DeepSeek已經達到了這種成本水平,但到年底成本再下降5倍也不要感到驚訝。
R1的性能是否達到了o1的水平?
另一方面,R1能夠達到與o1相當的結果,而o1僅在9月才宣布。 DeepSeek是如何能夠如此快速追趕上的?答案是推理是一個新範式,與先前的範式相比,它具有更快的迭代速度,且較小的計算量就能獲得顯著收益的低垂果實。正如我們在擴展定律報告中所述,先前的範式依賴於預訓練,這種方式正變得既昂貴又難以實現穩健的收益。新範式透過合成資料產生和在現有模型上進行後訓練的強化學習,專注於推理能力,使得以更低的價格獲得更快的進步成為可能。較低的進入門檻加上容易優化意味著DeepSeek能夠比往常更快複製o1的方法。隨著各方逐漸摸索如何在這個新範式中擴展,我們預期達到匹配能力所需的時間差距會增加。
值得注意的是,R1論文完全沒有提到使用了多少計算資源。這不是偶然的 - 為R1後訓練產生合成資料需要大量計算資源。更不用說強化學習了。 R1確實是一個非常好的模型,我們並不否認這一點,如此快速地追趕上推理能力的前沿確實令人印象深刻。考慮到DeepSeek是中國公司且用更少的資源追趕上來,這就更加令人印象深刻了。
但R1提到的一些基準測試也是具有誤導性的。
將R1與o1進行比較很棘手,因為R1特意不提及那些他們沒有領先的基準測試。雖然R1在推理表現上相匹配,但它並不是在每個指標上都明顯獲勝,在許多情況下它比o1還要差。

Source: (Yet) another tale of Rise and Fall: DeepSeek R1
And we have not mentioned o3 yet. o3 has significantly higher capabilities than both R1 or o1. In fact, OpenAI recently shared o3’s results, and the benchmark scaling is vertical. “Deep learning has hit a wall”, but of a different kind.
我們還沒有提到 o3。 o3 的能力明顯高於 R1 或 o1。事實上,OpenAI 最近分享了 o3 的結果,基準擴展是垂直的。 “深度學習遇到了瓶頸”,但類型不同。

Source: AI Action Summit
Google’s Reasoning Model is as Good as R1
While there is a frenzy of hype for R1, a $2.5T US company released a reasoning model a month before for cheaper: Google’s Gemini Flash 2.0 Thinking. This model is available for use, and is considerably cheaper than R1, even with a much larger context length for the model through API.
On reported benchmarks, Flash 2.0 Thinking beats R1, though benchmarks do not tell the whole story. Google only released 3 benchmarks so it’s an incomplete picture. Still, we think Google’s model is robust, standing up to R1 in many ways while receiving none of the hype. This could be because of Google’s lackluster go to market strategy and poor user experience, but also R1 is a Chinese surprise.
谷歌的推理模型與R1不相上下
雖然R1引發了一陣炒作狂潮,但一個市值2.5兆美元的美國公司在一個月前發布了一個更便宜的推理模型:Google的Gemini Flash 2.0 Thinking。這個模型現已可供使用,而且透過API提供的模型上下文長度更大,價格卻比R1便宜得多。在公佈的基準測試中,Flash 2.0 Thinking擊敗了R1,不過基準測試並不能說明全部問題。谷歌只發布了3個基準測試,所以這是一個不完整的畫面。
儘管如此,我們認為谷歌的模型很穩健,在許多方面可以與R1抗衡,卻沒有受到任何炒作。這可能是因為Google的上市策略乏力和使用者體驗不佳,但也因為R1是來自中國的意外之喜。

Source: SemiAnalysis
To be clear, none of this detracts from DeepSeek’s remarkable achievements. DeepSeek’s structure as a fast moving, well-funded, smart and focused startup is why it’s beating giants like Meta in releasing a reasoning model, and that’s commendable.
Technical Achievements
DeepSeek has cracked the code and unlocked innovations that leading labs have not yet been able to achieve. We expect that any published DeepSeek improvement will be copied by Western labs almost immediately.
What are these improvements? Most of the architectural achievements specifically relate to V3, which is the base model for R1 as well. Let’s detail these innovations.
Training (Pre and Post)
DeepSeek V3 utilizes Multi-Token Prediction (MTP) at a scale not seen before, and these are added attention modules which predict the next few tokens as opposed to a singular token. This improves model performance during training and can be discarded during inference. This is an example of an algorithmic innovation that enabled improved performance with lower compute.
There are added considerations like doing FP8 accuracy in training, but leading US labs have been doing FP8 training for some time.
DeepSeek v3 is also a mixture of experts model, which is one large model comprised of many other smaller experts that specialize in different things, an emergent behavior. One struggle MoE models have faced has been how to determine which token goes to which sub-model, or “expert”. DeepSeek implemented a “gating network” that routed tokens to the right expert in a balanced way that did not detract from model performance. This means that routing is very efficient, and only a few parameters are changed during training per token relative to the overall size of the model. This adds to the training efficiency and to the low cost of inference.
Despite concerns that Mixture-of-Experts (MoE) efficiency gains might reduce investment, Dario points out that the economic benefits of more capable AI models are so substantial that any cost savings are quickly reinvested into building even larger models. Rather than decreasing overall investment, MoE’s improved efficiency will accelerate AI scaling efforts. The companies are laser focused on scaling models to more compute and making them more efficient algorithmically.
In terms of R1, it benefited immensely from having a robust base model (v3). This is partially because of the Reinforcement Learning (RL). There were two focuses in RL: formatting (to ensure it provides a coherent output) and helpfulness and harmlessness (to ensure the model is useful). Reasoning capabilities emerged during the fine-tuning of the model on a synthetic dataset. This, as mentioned in our scaling laws article, is what happened with o1. Note that in the R1 paper no compute is mentioned, and this is because mentioning how much compute was used would show that they have more GPUs than their narrative suggests. RL at this scale requires a considerable amount of compute, especially to generate synthetic data.
Additionally a portion of the data DeepSeek used seems to be data from OpenAI’s models, and we believe that will have ramifications on policy on distilling from outputs. This is already illegal in the terms of service, but going forward a new trend might be a form of KYC (Know Your Customer) to stop distillation.
And speaking of distillation, perhaps the most interesting part of the R1 paper was being able to turn non-reasoning smaller models into reasoning ones via fine tuning them with outputs from a reasoning model. The dataset curation contained a total of 800k samples, and now anyone can use R1’s CoT outputs to make a dataset of their own and make reasoning models with the help of those outputs. We might see more smaller models showcase reasoning capabilities, bolstering performance of small models.
需要明確的是,這些都不會削弱DeepSeek的卓越成就。 DeepSeek作為一個快速發展、資金充足、智慧專注的創業公司,正是因為這種結構使其能夠在發布推理模型方面擊敗*Meta*這樣的巨頭,這值得稱讚。
技術成就
DeepSeek已經破解了密碼,實現了領先實驗室尚未能夠實現的創新。我們預計,任何已發布的DeepSeek改進都會被西方實驗室幾乎立即複製。這些改進是什麼?大多數架構成就特別涉及V3,它也是R1的基礎模型。讓我們詳細說明這些創新。
訓練(預訓練和後訓練)
DeepSeek V3使用了前所未見規模的多令牌預測(MTP),這些是新增的注意力模組,可以預測接下來的幾個令牌而不是單一令牌。這提高了訓練期間的模型性能,並且可以在推理時丟棄。這是一個透過演算法創新實現更低計算量更高效能的例子。還有一些其他考慮因素,例如在訓練中使用FP8精度,但領先的美國實驗室已經進行FP8訓練一段時間了。 DeepSeek v3也是一個專家混合模型,它是由許多專門處理不同事物的較小專家組成的一個大模型,這是一種湧現行為。
MoE模型面臨的一個困難是如何決定哪個令牌去往哪個子模型或"專家"。 DeepSeek實現了一個"門控網路",以平衡的方式將令牌路由到正確的專家,而不會影響模型性能。這意味著路由非常高效,相對於模型的整體大小,每個令牌在訓練期間只需要改變很少的參數。這提高了訓練效率和降低了推理成本。
儘管有人擔心專家混合(MoE)效率提升可能會減少投資,但Dario指出,更強大的AI模型帶來的經濟效益如此巨大,以至於任何成本節省都會很快被重新投資於建立更大的模型。 MoE的改進效率不會減少整體投資,反而會加速AI擴展努力。這些公司專注於擴展模型以獲得更多運算能力,並在演算法上使其更有效率。就R1而言,它極大地受益於擁有一個強大的基礎模型(v3)。這部分是因為強化學習(RL)。 RL有兩個重點:格式化(確保提供連貫的輸出)和有用性與無害性(確保模型有用)。推理能力是在合成資料集微調過程中出現的。這,正如我們在擴展定律文章中所提到的,就是o1發生的情況。請注意,在R1論文中沒有提到計算量,這是因為提到使用了多少計算量會顯示他們擁有的GPU比他們敘述中暗示的要多。這種規模的RL需要相當大的計算量,特別是在產生合成資料時。此外,DeepSeek使用的部分數據似乎來自OpenAI的模型,我們認為這將對從輸出中提取的政策產生影響。這在服務條款中已經是非法的,但未來可能會出現一種新趨勢,即某種形式的KYC(了解你的客戶)來阻止提取。說到提取,R1論文中最有趣的部分可能是能夠透過用推理模型的輸出對較小的非推理模型進行微調,將其轉變為推理模型。資料集包含總計80萬個樣本,現在任何人都可以使用R1的CoT輸出來建立自己的資料集,並在這些輸出的幫助下製作推理模型。我們可能會看到更多較小的模型展示推理能力,增強小型模型的表現。
Multi-head Latent Attention (MLA)
MLA is a key innovation responsible for a significant reduction in the inference price for DeepSeek. The reason is MLA reduces the amount of KV Cache required per query by about 93.3% versus standard attention. KV Cache is a memory mechanism in transformer models that stores data representing the context of the conversation, reducing unnecessary computation.
As discussed in our scaling laws article, KV Cache grows as the context of a conversation grows, and creates considerable memory constraints. Drastically decreasing the amount of KV Cache required per query decreases the amount of hardware needed per query, which decreases the cost. However we think DeepSeek is providing inference at cost to gain market share, and not actually making any money. Google Gemini Flash 2 Thinking remains cheaper, and Google is unlikely to be offering that at cost. MLA specifically caught the eyes of many leading US labs. MLA was released in DeepSeek V2, released in May 2024. DeepSeek has also enjoyed more efficiencies for inference workloads with the H20, due to higher memory bandwidth and capacity compared to the H100. They have also announced partnerships with Huawei but very little has been done with Ascend compute so far.
We believe the most interesting implications is specifically on margins, and what that means for the entire ecosystem. Below we have a view of the future pricing structure of the entire AI industry, and we detail why we think DeepSeek is subsidizing price, as well as why we see early signs that Jevons paradox is carrying the day. We comment on the implications on export controls, how the CCP might react with added DeepSeek domninance, and more.
多頭潛在註意力(MLA)
MLA是一項關鍵創新,它使DeepSeek的推理價格顯著降低。這是因為與標準注意力機制相比,MLA將每次查詢所需的KV快取量減少了約93.3%。 KV快取是transformer模型中的一種記憶體機制,用於儲存表示對話上下文的數據,減少不必要的計算。正如我們在擴展定律文章中討論的,KV快取隨著對話上下文的增長而增長,並造成相當大的記憶體限制。大幅減少每次查詢所需的KV快取量,降低了每次查詢所需的硬體量,從而降低了成本。然而,我們認為DeepSeek提供的推理價格是以成本價來獲得市場份額,這個價格實際上並沒有賺錢能力。谷歌的Gemini Flash 2 Thinking仍然更便宜,而Google也不太可能以成本價提供服務。 MLA特別引起了許多美國領先實驗室的關注。 MLA在2024年5月發布的DeepSeek V2中首次亮相。由於H20相比H100具有更高的記憶體頻寬和容量,DeepSeek在推理工作負載方面獲得了更多的效率提升。他們也宣布與華為建立合作關係,但到目前為止在昇騰計算方面的進展很少。
我們認為最有趣的影響特別是在利潤率方面,以及這對整個生態系統意味著什麼。以下我們對整個AI產業未來的價格結構進行了展望,並詳細說明了為什麼我們認為DeepSeek在補貼價格,以及為什麼我們看到傑文斯悖論正在發揮作用的早期跡象。我們也評論了對出口管制的影響,中方可能如何應對DeepSeek的主導地位增強等問題。























