網路安全的世界,正在進入一個由 AI 主導的新戰場。根據最新統計,2025 年全球由 AI 驅動的網路安全事件已激增 47%,這不再是未來式,而是現在進行式。從自動生成釣魚郵件到開發客製化勒索軟體,AI 正讓網路犯罪的規模、速度與複雜度,提升到前所未有的層級。
當攻擊方已經用上最新的武器,防守方自然不能墨守成規。過去一年,我們看到許多利用 AI 進行攻擊的案例,但現在,科技巨頭也開始反擊。AI 安全與研究公司 Anthropic 最近發表了一項研究,展示他們如何訓練自家模型 Claude,使其成為一名「AI 網路防禦者」。Building AI for cyber defenders

AI 攻擊百花齊放:我們面臨什麼樣的威脅?
在深入探討 Anthropic 的防禦策略之前,我們必須先理解當前 AI 攻擊的嚴峻情勢。攻擊者利用 AI 的能力,已經遠超乎多數人的想像。這些新型態的攻擊模式,不僅讓傳統的防禦機制疲於奔命,也大幅降低了發動大規模攻擊的門檻。
自動化與規模化的攻擊手法
過去需要一個團隊耗費數週策劃的攻擊,現在可能由一個 AI 模型在幾小時內完成。近期網路攻擊事件樣態指出,網路犯罪集團正利用大型語言模型快速產出針對特定目標的勒索軟體和釣魚郵件,導致雲端入侵事件暴增。一個名為「Prompt Lock」的勒索軟體,能讓惡意軟體在感染裝置後,即時與 AI 模型連線,根據受害者的系統環境「即時調整」攻擊策略,讓每一次的入侵都更具破壞性。
以假亂真的深度偽造詐騙
AI 生成的深度偽造(Deepfake)影音,也成為了社交工程攻擊的利器。北韓的駭客組織已經被發現利用 AI 偽造高階主管的聲音與影像,在視訊會議中誘騙員工安裝惡意軟體或轉移資金。香港曾發生一起金額高達 2500 萬美元的詐騙案,就是利用了 AI 偽造的聲音。這種攻擊的可怕之處在於,它直接繞過技術防線,攻擊人性中最脆弱的信任環節。
將 AI 工具變成內鬼
更為隱蔽的攻擊,是直接「污染」企業內部使用的 AI 助理。攻擊者可以透過在郵件或文件中植入惡意指令,當 Microsoft Copilot 這類的 AI 助理處理這些資料時,就可能在無意間觸發指令,導致資料外洩或執行未經授權的動作。這類名為「困惑代理人」(Confused Deputy)的攻擊,等於是將企業重金部署的 AI 工具,變成了從內部搞破壞的特洛伊木馬。
這些真實上演的案例,都顯示 AI 正在賦予攻擊者更強大的力量,防禦方若不跟上,過去建立的數位堡壘將不堪一擊。這正是 Anthropic 研究的起點。
Anthropic 的解法:訓練 AI 成為網路安全分析師
面對日益嚴峻的 AI 攻擊威脅,Anthropic 提出了一個直接的應對方案:與其被動防守,不如主動出擊,訓練 AI 成為防禦體系的核心。他們的研究重點,就是將旗下的 Claude 模型,打造成一個能夠主動發現、分析並修復安全漏洞的 AI 網路安全專家。
從「通用助理」到「專業打手」
Anthropic 指出,像 Claude 這樣的大型語言模型,其網路安全能力最初只是一種「湧現能力」(emergent abilities)。也就是說,隨著模型規模擴大,它自然而然學會了一些安全相關的技能,但這並非刻意訓練的結果。然而,意識到 AI 在網路安全領域的急迫性後,Anthropic 決定投入專門的資源,強化 Claude 在幾個關鍵防禦任務上的表現:
- 程式碼漏洞挖掘:訓練 AI 自動審查程式碼,找出潛在的安全弱點。
- 漏洞修補:不僅要找出問題,更要能提出具體的修復方案。
- 模擬環境測試:在模擬的系統環境中,測試 AI 發現與應對威脅的能力。
值得注意的是,Anthropic 強調他們刻意避免增強那些明顯有利於「攻擊方」的能力,例如進階的漏洞利用或惡意軟體撰寫。他們的目標是讓 AI 成為開發階段就能預防問題、部署後能即時修復問題的可靠夥伴。
用實戰評測證明能力
為了驗證訓練成果,Anthropic 讓最新版的 Claude Sonnet 4.5 參與了多項業界標準的網路安全評測,並取得了驚人的成績。
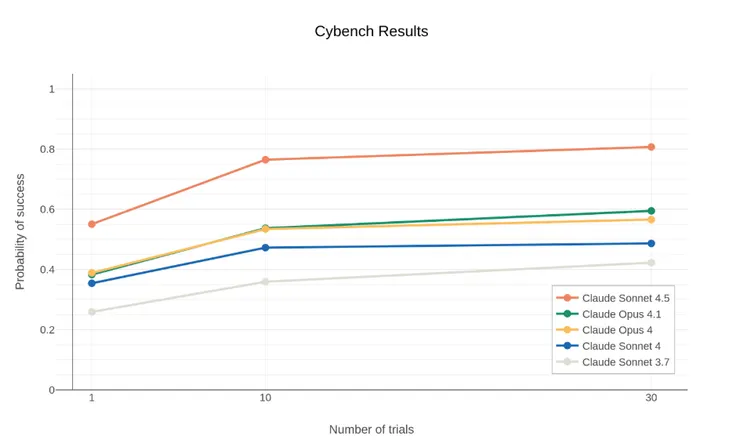
在一項名為 Cybench 的評測中(其挑戰題目來自真實的駭客搶旗競賽 Capture-the-Flag, CTF),Claude Sonnet 4.5 的表現不僅超越了前代模型,甚至比僅僅兩個月前發布的頂級模型 Opus 4.1 更強大。在其中一項挑戰中,Claude 只花了 38 分鐘,就完成了分析網路流量、解壓縮惡意軟體並解密的複雜任務,而這項任務預計需要一位人類專家至少一小時才能完成。當給予 10 次嘗試機會時,Claude Sonnet 4.5 在 Cybench 上的成功率高達 76.5%,這個數字在短短六個月內翻了一倍。
在另一項名為 CyberGym 的評測中,AI 需要在真實的開源軟體專案中找出已知的漏洞,甚至挖掘全新的未知漏洞。結果顯示,在給予 30 次嘗試機會後,Claude Sonnet 4.5 成功在 66.7% 的專案中重現已知漏洞,更在超過 33% 的專案中發現了前所未見的新漏洞。這證明了 AI 不僅能學習已知的攻擊模式,更有潛力發現人類尚未察覺的零日漏洞。
這些數據清晰地表明,透過專門的訓練,AI 在網路防禦任務上的能力正在快速提升,已經從理論上的可能性,轉變為實務上的即戰力。
TN科技筆記的洞察
- 個人認為最值得關注的是「防禦規模化」的可能性。長久以來,網路攻防一直處於不對等的狀態:攻擊方可以利用自動化工具,以極低的成本發動大規模、廣泛的攻擊;而防禦方則高度依賴有限的人力,逐一應對、修補。Anthropic 的研究顯示,AI 有潛力徹底改變這個局面。當 AI 防禦者能夠 24 小時不間斷地自動審查數百萬行程式碼、分析極大量的系統 log、甚至自動生成修補程式時,防禦方終於有機會在「規模」上與攻擊方抗衡。這不僅是效率的提升,更是防禦思維的根本轉變。
- 然而 Anthropic 雖然強調其研究專注於防禦,但我們無法忽視一個事實:一個能高效找出漏洞的 AI,本身就是一把雙面刃。攻擊者必然也會嘗試利用相同或更先進的 AI 技術來開發更隱蔽、更複雜的攻擊手法。這將導致攻防雙方的技術迭代速度越來越快,未來可能出現 AI 自動攻擊系統與 AI 自動防禦系統在網路上進行電影般毫秒級的對抗,屆時,人類的反應速度將遠遠跟不上。此外,「AI 的可信度」也是一大問題。我們能在多大程度上信任 AI 做出的判斷?如果 AI 誤判,將一個正常的系統行為標記為攻擊,並自動採取阻斷措施,可能會造成比駭客攻擊更嚴重的營運中斷。因此,如何建立有效的人機協作(Human-in-the-loop)機制,確保 AI 的決策受到監督與控制,將是這項技術能否成功落地的關鍵。
支持TN科技筆記,與科技共同前行
我是TN科技筆記,如果喜歡這篇文章,歡迎留言、點選愛心、轉發給我支持鼓勵~~~也歡迎每個月請我喝杯咖啡,鼓勵我撰寫更多科技文章,一起跟著科技浪潮前進!!>>>>> 請我喝一杯咖啡
在此也感謝每個月持續請我喝杯咖啡的讀者們,讓我更加有動力為各位帶來科技新知!
以下是我的 threads 也歡迎追蹤、回覆、轉發喔!
>>>>> TN科技筆記(TechNotes)





























