首頁內容關於


郝信華 iPAS AI應用規劃師 學習筆記
Top 5

AWS Shield 是一種 **受管的分散式阻斷服務(DDoS)保護服務**,用來保護在 AWS 上執行的應用程式免受 DDoS 攻擊,避免網站或服務因大量惡意流量而停機或延遲。它提供即時偵測和自動緩解功能,讓使用者無需聯絡 AWS 支援即可享有防護。
主要版本與功能
- **AWS Shie
Amazon S3 Intelligent-Tiering(智慧分層存儲)是一種可自動根據數據的使用頻率,將資料自動移動到最具成本效益的存儲層的儲存類別,幫助用戶在維持高性能的同時降低成本。
主要特點:
• 自動監控每個物件的存取狀況。
• 根據存取頻率,自動將資料在「頻繁存取層」和「不頻
Amazon SageMaker Experiments 是 AWS 提供的一個專門用於機器學習模型實驗管理的工具,它可以幫助用戶系統性地追蹤、組織和分析機器學習訓練過程中的參數、指標、程式碼版本、資料集及輸出結果,提高模型開發的可重現性和協作效率。
主要功能與特點包括:
• 實驗(Exper
Shapley值是合作博弈論中的一個重要概念,由Lloyd Shapley於1953年提出,用來公平分配合作中各參與者所帶來的貢獻。在機器學習領域,Shapley值被用來說明每個特徵對模型預測結果的貢獻。
具體來說:
• 將所有特徵視為合作遊戲中的「玩家」。
• 將模型的預測結果視為「報酬
AWS HealthScribe 是 Amazon Web Services(AWS)推出的一項符合 HIPAA 規範的生成式 AI 服務,專為醫療保健軟體供應商設計,幫助自動化生成臨床文件。它通過語音識別和生成式人工智能,自動轉錄患者與臨床醫生的對話,生成詳細且易於審閱的臨床筆記,從而大幅減輕醫生
基於人類反饋的強化學習(Reinforcement Learning from Human Feedback,簡稱RLHF)是一種機器學習技術,它結合了強化學習與人類提供的反饋,用以優化機器學習模型的行為,使其結果更符合人類目標、期望和偏好。其基本流程是先根據人類的回饋訓練一個「獎勵模型」,這個獎勵
BLEU(Bilingual Evaluation Understudy) 是一種用於評估機器翻譯及自然語言生成模型產出的文本品質的自動化評分指標。它主要用來評估機器生成的翻譯結果與人類專家翻譯結果的相似度,以數值化方式衡量翻譯的準確度和流暢性。
BLEU 的關鍵原理與特點:
• n-gram
Amazon SageMaker endpoints 是您將機器學習模型部署到可用於即時推論(real-time inference)的服務位置。透過 SageMaker endpoints,您可以將已訓練好的模型部署成一個穩定可用的 API 接口,用戶或應用程式可以透過這個接口傳送資料請求並即時獲
AWS Kiro 是亞馬遜 AWS 於 2025 年推出的一款專為 AI Agent(AI代理)設計的整合開發環境(Agentic IDE)。它不僅是一個程式碼撰寫工具,更深入介入軟體開發流程,特別強調以「規格驅動開發」(spec-driven development)的方法來提升開發效率和品質。
Data Lineage(資料血緣) 是指追蹤和記錄資料從來源到消費的整個流轉過程,包括資料的起源(來源)、經過的轉換、傳遞路徑以及最終的用途。它讓企業或使用者能夠清楚了解資料的流向、每個環節的處理細節,以及誰訪問和修改了資料,對於資料治理、合規審計、故障排查和品質管理非常關鍵。
在 AWS 生態
AWS Shield 是一種 **受管的分散式阻斷服務(DDoS)保護服務**,用來保護在 AWS 上執行的應用程式免受 DDoS 攻擊,避免網站或服務因大量惡意流量而停機或延遲。它提供即時偵測和自動緩解功能,讓使用者無需聯絡 AWS 支援即可享有防護。
主要版本與功能
- **AWS Shie
Amazon S3 Intelligent-Tiering(智慧分層存儲)是一種可自動根據數據的使用頻率,將資料自動移動到最具成本效益的存儲層的儲存類別,幫助用戶在維持高性能的同時降低成本。
主要特點:
• 自動監控每個物件的存取狀況。
• 根據存取頻率,自動將資料在「頻繁存取層」和「不頻
Amazon SageMaker Experiments 是 AWS 提供的一個專門用於機器學習模型實驗管理的工具,它可以幫助用戶系統性地追蹤、組織和分析機器學習訓練過程中的參數、指標、程式碼版本、資料集及輸出結果,提高模型開發的可重現性和協作效率。
主要功能與特點包括:
• 實驗(Exper
Shapley值是合作博弈論中的一個重要概念,由Lloyd Shapley於1953年提出,用來公平分配合作中各參與者所帶來的貢獻。在機器學習領域,Shapley值被用來說明每個特徵對模型預測結果的貢獻。
具體來說:
• 將所有特徵視為合作遊戲中的「玩家」。
• 將模型的預測結果視為「報酬
AWS HealthScribe 是 Amazon Web Services(AWS)推出的一項符合 HIPAA 規範的生成式 AI 服務,專為醫療保健軟體供應商設計,幫助自動化生成臨床文件。它通過語音識別和生成式人工智能,自動轉錄患者與臨床醫生的對話,生成詳細且易於審閱的臨床筆記,從而大幅減輕醫生
基於人類反饋的強化學習(Reinforcement Learning from Human Feedback,簡稱RLHF)是一種機器學習技術,它結合了強化學習與人類提供的反饋,用以優化機器學習模型的行為,使其結果更符合人類目標、期望和偏好。其基本流程是先根據人類的回饋訓練一個「獎勵模型」,這個獎勵
BLEU(Bilingual Evaluation Understudy) 是一種用於評估機器翻譯及自然語言生成模型產出的文本品質的自動化評分指標。它主要用來評估機器生成的翻譯結果與人類專家翻譯結果的相似度,以數值化方式衡量翻譯的準確度和流暢性。
BLEU 的關鍵原理與特點:
• n-gram
Amazon SageMaker endpoints 是您將機器學習模型部署到可用於即時推論(real-time inference)的服務位置。透過 SageMaker endpoints,您可以將已訓練好的模型部署成一個穩定可用的 API 接口,用戶或應用程式可以透過這個接口傳送資料請求並即時獲
AWS Kiro 是亞馬遜 AWS 於 2025 年推出的一款專為 AI Agent(AI代理)設計的整合開發環境(Agentic IDE)。它不僅是一個程式碼撰寫工具,更深入介入軟體開發流程,特別強調以「規格驅動開發」(spec-driven development)的方法來提升開發效率和品質。
Data Lineage(資料血緣) 是指追蹤和記錄資料從來源到消費的整個流轉過程,包括資料的起源(來源)、經過的轉換、傳遞路徑以及最終的用途。它讓企業或使用者能夠清楚了解資料的流向、每個環節的處理細節,以及誰訪問和修改了資料,對於資料治理、合規審計、故障排查和品質管理非常關鍵。
在 AWS 生態

ELMo 和 BERT 提供的嵌入與傳統的靜態詞嵌入(如 Word2Vec)的主要區別在於它們是否為上下文相關 (contextual)。
靜態詞嵌入 (Static Embeddings)
代表模型: Word2Vec、GloVe、FastText
主要特點:
單一詞彙,單一向量: 每個詞
ELMo(Embeddings from Language Models)是一種在自然語言處理(NLP)中使用的深度學習詞嵌入模型,於2018年由Allen Institute for AI及華盛頓大學提出。與傳統靜態詞向量(如Word2Vec、GloVe)不同,ELMo產生的是**「上下文相關的詞
困惑度(Perplexity,簡稱PPL)是自然語言處理(NLP)及大型語言模型中常用來衡量模型預測能力的指標。
它的意義在於衡量模型在對一句話或一組語料作預測時的「困惑程度」或「不確定性」:
困惑度越低,表示模型對文本的預測能力越強,能較準確地猜出下一個字詞。 困惑度越高,代表模型在預測時感到
One-Hot Encoding (獨熱編碼)
核心定義
One-Hot Encoding 是一種將類別型資料 (Categorical Data)
轉換為機器學習模型能夠理解的數值格式的過程。它將每個類別都轉換成一個新的二元(0 或
1)特徵欄位。
它的核心思想是:在
聊天機器人(Chatbot)是一種基於程式的軟體應用程式或智慧代理,旨在模擬人類的對話,讓用戶能夠透過文字、語音或其他形式的互動來進行交流。聊天機器人的目標是理解使用者的輸入,並根據預定的規則、知識庫或機器學習模型提供相應的回應或完成特定的任務。
聊天機器人的主要目標:
模擬人類對話:使用者感覺
問答系統(Question Answering,QA)是自然語言處理(NLP)領域的一個重要,指的是一種能夠接收以自然語言提出的問題,並從給定的知識來源(例如文本集合、知識圖譜、資料庫等)中自動查找並提供準確答案的用戶系統。問答系統的目標是讓電腦能夠像與人交流一樣,直接提出問題並獲得簡潔明了的答案,
翻譯(Machine Translation,MT)是自然語言處理(NLP)的一個核心領域,是指利用電腦程式將文字或機器語言從一種自然自動翻譯產生另一種自然語言的過程。其目標是打破語言障礙,實現跨語言的訊息交流。
機器翻譯的目標:
自動化翻譯過程:用電腦取代人工翻譯,提高效率和速度。
保持語意
識別和提取文字資料中表達的情緒、或觀點。目標通常是判斷文本是表達正面(正面)、負面(負面)還是中性(中性)的情緒。
情緒分析的目標:
判斷文本的情感傾向:確定作者或說話者對特定主題、產品、服務、事件或個人的態度是正面的、負面的還是中立的。
提升情緒強度:除了情緒之外,還可以分析情緒的強度,例如
詞向量(Word Embedding),也稱詞嵌入,是自然語言處理(NLP)中非常重要的詞彙表示方法。將詞彙表中的每一個詞彙映射到一個低維、實數向量空間中,使得語意上的詞彙相似在這個向量空間中的位置也互相接近。
詞的重要性:
將符號表示轉換為數值表示:傳統的詞彙表示方法(例如one-hot編碼)
條件隨機場(Conditional Random Field,CRF)是一種判別的式機率模型,常用於序列標籤(Sequence Labeling)和格式化預測(Structured Prediction)任務中。它可以用於預測序列中每個元素的標籤,同時考慮到相鄰元素之間的依賴關係。
核心概念:
ELMo 和 BERT 提供的嵌入與傳統的靜態詞嵌入(如 Word2Vec)的主要區別在於它們是否為上下文相關 (contextual)。
靜態詞嵌入 (Static Embeddings)
代表模型: Word2Vec、GloVe、FastText
主要特點:
單一詞彙,單一向量: 每個詞
ELMo(Embeddings from Language Models)是一種在自然語言處理(NLP)中使用的深度學習詞嵌入模型,於2018年由Allen Institute for AI及華盛頓大學提出。與傳統靜態詞向量(如Word2Vec、GloVe)不同,ELMo產生的是**「上下文相關的詞
困惑度(Perplexity,簡稱PPL)是自然語言處理(NLP)及大型語言模型中常用來衡量模型預測能力的指標。
它的意義在於衡量模型在對一句話或一組語料作預測時的「困惑程度」或「不確定性」:
困惑度越低,表示模型對文本的預測能力越強,能較準確地猜出下一個字詞。 困惑度越高,代表模型在預測時感到
One-Hot Encoding (獨熱編碼)
核心定義
One-Hot Encoding 是一種將類別型資料 (Categorical Data)
轉換為機器學習模型能夠理解的數值格式的過程。它將每個類別都轉換成一個新的二元(0 或
1)特徵欄位。
它的核心思想是:在
聊天機器人(Chatbot)是一種基於程式的軟體應用程式或智慧代理,旨在模擬人類的對話,讓用戶能夠透過文字、語音或其他形式的互動來進行交流。聊天機器人的目標是理解使用者的輸入,並根據預定的規則、知識庫或機器學習模型提供相應的回應或完成特定的任務。
聊天機器人的主要目標:
模擬人類對話:使用者感覺
問答系統(Question Answering,QA)是自然語言處理(NLP)領域的一個重要,指的是一種能夠接收以自然語言提出的問題,並從給定的知識來源(例如文本集合、知識圖譜、資料庫等)中自動查找並提供準確答案的用戶系統。問答系統的目標是讓電腦能夠像與人交流一樣,直接提出問題並獲得簡潔明了的答案,
翻譯(Machine Translation,MT)是自然語言處理(NLP)的一個核心領域,是指利用電腦程式將文字或機器語言從一種自然自動翻譯產生另一種自然語言的過程。其目標是打破語言障礙,實現跨語言的訊息交流。
機器翻譯的目標:
自動化翻譯過程:用電腦取代人工翻譯,提高效率和速度。
保持語意
識別和提取文字資料中表達的情緒、或觀點。目標通常是判斷文本是表達正面(正面)、負面(負面)還是中性(中性)的情緒。
情緒分析的目標:
判斷文本的情感傾向:確定作者或說話者對特定主題、產品、服務、事件或個人的態度是正面的、負面的還是中立的。
提升情緒強度:除了情緒之外,還可以分析情緒的強度,例如
詞向量(Word Embedding),也稱詞嵌入,是自然語言處理(NLP)中非常重要的詞彙表示方法。將詞彙表中的每一個詞彙映射到一個低維、實數向量空間中,使得語意上的詞彙相似在這個向量空間中的位置也互相接近。
詞的重要性:
將符號表示轉換為數值表示:傳統的詞彙表示方法(例如one-hot編碼)
條件隨機場(Conditional Random Field,CRF)是一種判別的式機率模型,常用於序列標籤(Sequence Labeling)和格式化預測(Structured Prediction)任務中。它可以用於預測序列中每個元素的標籤,同時考慮到相鄰元素之間的依賴關係。
核心概念:
Stereo Vision(立體視覺)是計算機視覺的一項技術,通過使用兩個或多個相機從不同視角拍攝同一場景,從二維圖像中計算出三維空間資訊。
原理
類似人類雙眼視覺,利用左右兩張略有視差的影像,計算對應點的位移(視差disparity)。 視差越大,物體越接近相機;視差越小,物體越遠。 透過攝影
Activation Function(激活函數)是神經網絡中的一個數學函數,其作用是將神經元的輸入信號轉換成輸出信號。激活函數決定了神經元是否「激活」並將訊號傳遞給下一層。
主要用途
引入非線性:激活函數將線性組合的輸入轉換為非線性輸出,使得神經網絡可以學習複雜的資料模式與非線性關係。 控制訊
Semantic Segmentation(語義分割)是計算機視覺領域中的一項技術,目的是將圖像中的每一個像素賦予特定的語義標籤,從而理解圖像中的不同物體或區域。
主要概念
對圖像每個像素分類,使其屬於預定義的類別(例如:人、車、道路、天空等)。 不區分同一類別的不同實例,只區分語義類別。 產生
Instance Segmentation(實例分割)是一種先進的計算機視覺技術,它不僅識別圖像中的物體,還精確區分並標註每個物體的像素級邊界。
主要特點
每個物體獨立分割:對圖像中同一類的多個物體進行區分,分別賦予不同的實例ID,與傳統的物體檢測(bounding box)或語義分割(sema
Histogram of Oriented Gradients(HOG,方向梯度直方圖)是一種在計算機視覺和影像處理中常用於物體偵測和辨識的特徵描述方法。
主要原理
HOG通過計算圖像中局部區域的梯度方向(edge orientations)分佈,來描述物體的形狀與結構。具體步驟包括:
計算梯

Gaussian Filtering(高斯濾波)是一種常用的影像平滑技術,廣泛應用於影像處理及計算機視覺中。它通過對影像進行高斯函數形狀的卷積運算,使得每個像素的新值由其周圍像素根據高斯權重加權平均計算而得。
主要特點:
平滑降噪:有效去除影像中的高頻噪聲,讓影像看起來更柔和、噪點減少。 權重分
Histogram Equalization(直方圖均衡化)是一種常見的影像處理技術,用於改善影像對比度。它的原理是通過調整影像中像素的灰度分佈,使圖像的直方圖更均勻分佈,進而增加影像細節和對比度。
具體來說,直方圖均衡化將像素值重新映射,使得整張影像的亮度分布跨越全灰度範圍,原本集中在狹窄亮度區
Image Enhancement(影像增強)是指對數位影像進行處理與調整,以改善其視覺品質或突出特定特徵,使影像更適合顯示或後續分析。增強的目的是讓影像更清晰、對比度更佳、細節更豐富,便於觀察或機器分析。
常見的影像增強技術包括:
對比度調整(Contrast Adjustment):改善明暗
CNN 中的感受野 (Receptive Field) 是指在卷積神經網路的某一層中,每個神經元(或像素)的輸出受到前一層哪些區域的輸入所影響。換句話說,它是指輸入圖像上的一個特定區域,這個區域的資訊最終會傳遞到當前層的某個特定神經元。
可以將感受野想像成一個「視野」。對於某一層的某個神經元來說,
角點偵測演算法 (Corner Detection Algorithms) 是電腦視覺中用於識別圖像中「角點」的技術。角點是指圖像中在兩個或多個方向上具有顯著強度變化的像素點,可以理解為圖像中局部區域的交叉點、尖銳的轉角或紋理的終止點。
為什麼角點偵測很重要?
角點在圖像分析中扮演著重要的角色,
Stereo Vision(立體視覺)是計算機視覺的一項技術,通過使用兩個或多個相機從不同視角拍攝同一場景,從二維圖像中計算出三維空間資訊。
原理
類似人類雙眼視覺,利用左右兩張略有視差的影像,計算對應點的位移(視差disparity)。 視差越大,物體越接近相機;視差越小,物體越遠。 透過攝影
Activation Function(激活函數)是神經網絡中的一個數學函數,其作用是將神經元的輸入信號轉換成輸出信號。激活函數決定了神經元是否「激活」並將訊號傳遞給下一層。
主要用途
引入非線性:激活函數將線性組合的輸入轉換為非線性輸出,使得神經網絡可以學習複雜的資料模式與非線性關係。 控制訊
Semantic Segmentation(語義分割)是計算機視覺領域中的一項技術,目的是將圖像中的每一個像素賦予特定的語義標籤,從而理解圖像中的不同物體或區域。
主要概念
對圖像每個像素分類,使其屬於預定義的類別(例如:人、車、道路、天空等)。 不區分同一類別的不同實例,只區分語義類別。 產生
Instance Segmentation(實例分割)是一種先進的計算機視覺技術,它不僅識別圖像中的物體,還精確區分並標註每個物體的像素級邊界。
主要特點
每個物體獨立分割:對圖像中同一類的多個物體進行區分,分別賦予不同的實例ID,與傳統的物體檢測(bounding box)或語義分割(sema
Histogram of Oriented Gradients(HOG,方向梯度直方圖)是一種在計算機視覺和影像處理中常用於物體偵測和辨識的特徵描述方法。
主要原理
HOG通過計算圖像中局部區域的梯度方向(edge orientations)分佈,來描述物體的形狀與結構。具體步驟包括:
計算梯
Gaussian Filtering(高斯濾波)是一種常用的影像平滑技術,廣泛應用於影像處理及計算機視覺中。它通過對影像進行高斯函數形狀的卷積運算,使得每個像素的新值由其周圍像素根據高斯權重加權平均計算而得。
主要特點:
平滑降噪:有效去除影像中的高頻噪聲,讓影像看起來更柔和、噪點減少。 權重分
Histogram Equalization(直方圖均衡化)是一種常見的影像處理技術,用於改善影像對比度。它的原理是通過調整影像中像素的灰度分佈,使圖像的直方圖更均勻分佈,進而增加影像細節和對比度。
具體來說,直方圖均衡化將像素值重新映射,使得整張影像的亮度分布跨越全灰度範圍,原本集中在狹窄亮度區
Image Enhancement(影像增強)是指對數位影像進行處理與調整,以改善其視覺品質或突出特定特徵,使影像更適合顯示或後續分析。增強的目的是讓影像更清晰、對比度更佳、細節更豐富,便於觀察或機器分析。
常見的影像增強技術包括:
對比度調整(Contrast Adjustment):改善明暗
CNN 中的感受野 (Receptive Field) 是指在卷積神經網路的某一層中,每個神經元(或像素)的輸出受到前一層哪些區域的輸入所影響。換句話說,它是指輸入圖像上的一個特定區域,這個區域的資訊最終會傳遞到當前層的某個特定神經元。
可以將感受野想像成一個「視野」。對於某一層的某個神經元來說,
角點偵測演算法 (Corner Detection Algorithms) 是電腦視覺中用於識別圖像中「角點」的技術。角點是指圖像中在兩個或多個方向上具有顯著強度變化的像素點,可以理解為圖像中局部區域的交叉點、尖銳的轉角或紋理的終止點。
為什麼角點偵測很重要?
角點在圖像分析中扮演著重要的角色,
推論統計 (Inferential Statistics) 是統計學的一個分支,它使用從樣本數據中獲得的信息來對更大的群體(或總體)做出推斷、預測或結論。與描述統計不同,推論統計的目標不僅僅是總結和描述數據,而是利用樣本來推斷總體的特性。
推論統計的核心思想:
由於在許多實際情況下,無法收集到整
敘述統計 (Descriptive Statistics) 是統計學的一個分支,旨在以簡潔的方式總結和描述數據集的特徵。它主要關注收集、組織、呈現和分析數據,但不涉及對總體進行推斷或預測。敘述統計的主要目標是提供數據的清晰概覽,使其更容易理解和解釋。
敘述統計通常包括以下幾種主要的度量和方法:
推論統計 (Inferential Statistics) 是統計學的一個分支,它使用從樣本數據中獲得的信息來對更大的群體(或總體)做出推斷、預測或結論。與描述統計不同,推論統計的目標不僅僅是總結和描述數據,而是利用樣本來推斷總體的特性。
推論統計的核心思想:
由於在許多實際情況下,無法收集到整
敘述統計 (Descriptive Statistics) 是統計學的一個分支,旨在以簡潔的方式總結和描述數據集的特徵。它主要關注收集、組織、呈現和分析數據,但不涉及對總體進行推斷或預測。敘述統計的主要目標是提供數據的清晰概覽,使其更容易理解和解釋。
敘述統計通常包括以下幾種主要的度量和方法:
Reinforcement Learning from Human Feedback(RLHF)是訓練大型語言模型(如 ChatGPT)的一種方法,通過人類反饋引導模型更好地理解和回應。其流程主要包含三個階段:
RLHF 流程步驟
1. 預訓練語言模型(Pretraining)
使用大規模文本
Cross Attention 是 Transformer 模型中的一種注意力機制,主要用於讓模型能夠同時處理來自兩個不同來源的序列信息。它常見於編碼器-解碼器架構中,解碼器透過 cross attention「關注」編碼器輸出的所有位置,從而有效地融合與利用輸入序列信息生成相應輸出。
Cross
LoRA(Low-Rank Adaptation)是一種高效的微調技術,設計用於快速適應大型預訓練模型(如GPT、BERT、T5)以完成特定任務,同時大幅減少需要調整的參數數量。它通過在模型的權重矩陣中引入低秩(low-rank)分解,僅學習少量可訓練參數,避免完整微調帶來的龐大計算和記憶體消耗。
Textual Inversion 是一種用於個性化文字到圖像生成模型(如 Stable Diffusion)的技術。它允許用戶通過少量示例圖片(通常3-5張),讓模型學會一個新的「詞彙」或「概念」,這個詞彙對應於用戶提供的特定對象、風格或人物。
主要原理:
• 傳統的文字到圖像模型使用預訓練
Emergent Abilities(突現能力)指的是在大型人工智慧模型(特別是大型語言模型)中,隨著模型規模、資料量和計算能力的增加,模型突然顯現出未被明確設計或訓練的全新技能或行為。這些能力不是模型明確被編程或預訓練的,而是隨著系統的複雜度提升自發出現,帶有某種不可預測性。
主要特點:
•
FID(Fréchet Inception Distance)是一種用來評估生成式模型(如GAN或擴散模型)所產生圖像品質的指標。其核心目標是比較生成圖像與真實圖像的分布差異,以量化生成圖像的真實性和多樣性。
FID 的工作原理
• 使用預訓練的 Inception-v3 網路提取生成圖像和真
Positional Encoding 是深度學習中 Transformer 模型用來表示序列中各個元素(例如詞語)位置的技術。由於 Transformer 自身的自注意力機制(self-attention)在處理序列時會把輸入視為一個集合,缺乏對元素順序的內建感知,因此需要注入位置信息讓模型能理解
AI alignment(人工智慧對齊)是一個研究領域,目標是確保人工智慧系統的行為和結果符合人類的意圖、價值觀和目標。換句話說,就是讓 AI 的行動方向與人類設計者或使用者真正想要達成的目標保持一致,避免 AI 產生不符合預期甚至危害性的行為。
為什麼 AI alignment 重要?
•
Instruction fine-tuning 是指對預訓練模型(例如 Stable Diffusion)進行微調,使模型能更好地理解並執行用戶的「指令」(instruction),即根據特定的描述或操作說明來生成對應的結果。
具體解釋:
• 傳統微調會針對特定任務或數據進行調整,但指令微調則
Stable Diffusion 是一個基於潛在擴散模型(Latent Diffusion Model, LDM)的文字到影像的生成模型,它能從文字描述自動生成高品質、高解析度的圖像。這個模型由 CompVis 團隊與 Stability AI 等合作開發,並基於 LAION 大型開源圖像語言對齊數
Reinforcement Learning from Human Feedback(RLHF)是訓練大型語言模型(如 ChatGPT)的一種方法,通過人類反饋引導模型更好地理解和回應。其流程主要包含三個階段:
RLHF 流程步驟
1. 預訓練語言模型(Pretraining)
使用大規模文本
Cross Attention 是 Transformer 模型中的一種注意力機制,主要用於讓模型能夠同時處理來自兩個不同來源的序列信息。它常見於編碼器-解碼器架構中,解碼器透過 cross attention「關注」編碼器輸出的所有位置,從而有效地融合與利用輸入序列信息生成相應輸出。
Cross
LoRA(Low-Rank Adaptation)是一種高效的微調技術,設計用於快速適應大型預訓練模型(如GPT、BERT、T5)以完成特定任務,同時大幅減少需要調整的參數數量。它通過在模型的權重矩陣中引入低秩(low-rank)分解,僅學習少量可訓練參數,避免完整微調帶來的龐大計算和記憶體消耗。
Textual Inversion 是一種用於個性化文字到圖像生成模型(如 Stable Diffusion)的技術。它允許用戶通過少量示例圖片(通常3-5張),讓模型學會一個新的「詞彙」或「概念」,這個詞彙對應於用戶提供的特定對象、風格或人物。
主要原理:
• 傳統的文字到圖像模型使用預訓練
Emergent Abilities(突現能力)指的是在大型人工智慧模型(特別是大型語言模型)中,隨著模型規模、資料量和計算能力的增加,模型突然顯現出未被明確設計或訓練的全新技能或行為。這些能力不是模型明確被編程或預訓練的,而是隨著系統的複雜度提升自發出現,帶有某種不可預測性。
主要特點:
•
FID(Fréchet Inception Distance)是一種用來評估生成式模型(如GAN或擴散模型)所產生圖像品質的指標。其核心目標是比較生成圖像與真實圖像的分布差異,以量化生成圖像的真實性和多樣性。
FID 的工作原理
• 使用預訓練的 Inception-v3 網路提取生成圖像和真
Positional Encoding 是深度學習中 Transformer 模型用來表示序列中各個元素(例如詞語)位置的技術。由於 Transformer 自身的自注意力機制(self-attention)在處理序列時會把輸入視為一個集合,缺乏對元素順序的內建感知,因此需要注入位置信息讓模型能理解
AI alignment(人工智慧對齊)是一個研究領域,目標是確保人工智慧系統的行為和結果符合人類的意圖、價值觀和目標。換句話說,就是讓 AI 的行動方向與人類設計者或使用者真正想要達成的目標保持一致,避免 AI 產生不符合預期甚至危害性的行為。
為什麼 AI alignment 重要?
•
Instruction fine-tuning 是指對預訓練模型(例如 Stable Diffusion)進行微調,使模型能更好地理解並執行用戶的「指令」(instruction),即根據特定的描述或操作說明來生成對應的結果。
具體解釋:
• 傳統微調會針對特定任務或數據進行調整,但指令微調則
Stable Diffusion 是一個基於潛在擴散模型(Latent Diffusion Model, LDM)的文字到影像的生成模型,它能從文字描述自動生成高品質、高解析度的圖像。這個模型由 CompVis 團隊與 Stability AI 等合作開發,並基於 LAION 大型開源圖像語言對齊數
Disentanglement(解耦表示學習)是在機器學習領域中,指學習一種資料表示,使得資料中的不同變異因素能被分離成彼此獨立且有意義的不同元素。
簡單來說,Disentanglement目標是將複雜高維資料如影像、語言等,拆解成多個獨立的解釋性組成部分,例如在影像中分離出物體的顏色、形狀、位置
Single Stream 神經網絡架構指的是利用單一數據流(stream)對輸入數據進行特徵提取和處理的神經網絡結構。與多流(multi-stream)或雙流(two-stream)網絡相比,單流網絡不會分開處理數據的不同模態或不同特徵子集,而是通過統一的網絡結構完成所有信息的學習。
Singl
Multi Stream 神經網絡架構是指同時利用多條信息流(streams)對輸入數據的不同特徵或子空間進行獨立處理,然後再將這些多路特徵融合起來,以提升模型的表達能力和任務性能。
Multi Stream 神經網絡的主要特點:
• 多條分支並行處理:每條流(stream)可以專注於數據的某
Two Stream 預設指的是一種神經網絡架構,通常在視頻分析、動作識別和人臉識別等領域中廣泛應用。其核心思想是將輸入的信息分成兩條流(stream)獨立處理,然後融合它們的特徵以獲得更全面的理解。
Two Stream 神經網絡架構主要特點:
• 空間流(Spatial Stream):處
Representation Learning(表徵學習)是機器學習中的一種技術,目標是自動學習和提取原始數據的有效特徵(表示),使得後續的機器學習任務如分類、回歸、更高層次的推理等能更好地進行。它擺脫了傳統手工特徵設計的限制,讓模型能通過數據自主發掘有用的表示。
核心理念:
• 自動從原始數
Driver Monitoring System(駕駛員監控系統,簡稱 DMS)是一種車輛安全技術,用於實時監控駕駛員的行為和生理狀態,以識別疲勞、分心或其他注意力不集中情況,並及時發出警告或介入,從而提高行車安全。
主要功能:
• 監測駕駛員的眼動、視線方向、眨眼頻率和頭部位置,判斷疲勞或分
Fréchet Inception Distance(FID)是一種用於評估生成模型(特別是生成對抗網絡GAN)生成圖像質量和多樣性的指標。它通過比較生成圖像和真實圖像在深度特徵空間(通常使用Inception v3模型的中間層激活)中的分佈差異,衡量兩者之間的相似度。
FID 的特點與優勢:
Inception Score(IS)是一種用於評估生成式模型(特別是生成對抗網絡GAN)生成圖像質量和多樣性的指標。它利用一個預訓練的Inception v3圖像分類模型,對生成的圖像進行分類,評估圖像是否清晰且內容多樣。
Inception Score 的評估原理:
1. 圖像質量:對單張
Disentangled Representation Learning(解耦表示學習)是機器學習領域的一種表示學習方法,其目標是將數據中的潛在生成因子分離成彼此獨立且具備語義解釋性的子表示。換言之,它試圖把複雜、高維的數據表示,拆解成多個獨立並且意義明確的因子,便於模型理解與操作。
解耦表示學習
Unimodal 指的是系統或模型僅使用單一類型的數據模態來進行處理和分析。例如,只使用文字、只使用圖像,或只使用音頻等單一模態。
Unimodal 的特點:
• 單一數據來源:系統只處理一種類型的輸入數據,如僅圖像或僅文字。
• 結構相對簡單:由於處理單一模態,模型架構和訓練相對簡單。
Disentanglement(解耦表示學習)是在機器學習領域中,指學習一種資料表示,使得資料中的不同變異因素能被分離成彼此獨立且有意義的不同元素。
簡單來說,Disentanglement目標是將複雜高維資料如影像、語言等,拆解成多個獨立的解釋性組成部分,例如在影像中分離出物體的顏色、形狀、位置
Single Stream 神經網絡架構指的是利用單一數據流(stream)對輸入數據進行特徵提取和處理的神經網絡結構。與多流(multi-stream)或雙流(two-stream)網絡相比,單流網絡不會分開處理數據的不同模態或不同特徵子集,而是通過統一的網絡結構完成所有信息的學習。
Singl
Multi Stream 神經網絡架構是指同時利用多條信息流(streams)對輸入數據的不同特徵或子空間進行獨立處理,然後再將這些多路特徵融合起來,以提升模型的表達能力和任務性能。
Multi Stream 神經網絡的主要特點:
• 多條分支並行處理:每條流(stream)可以專注於數據的某
Two Stream 預設指的是一種神經網絡架構,通常在視頻分析、動作識別和人臉識別等領域中廣泛應用。其核心思想是將輸入的信息分成兩條流(stream)獨立處理,然後融合它們的特徵以獲得更全面的理解。
Two Stream 神經網絡架構主要特點:
• 空間流(Spatial Stream):處
Representation Learning(表徵學習)是機器學習中的一種技術,目標是自動學習和提取原始數據的有效特徵(表示),使得後續的機器學習任務如分類、回歸、更高層次的推理等能更好地進行。它擺脫了傳統手工特徵設計的限制,讓模型能通過數據自主發掘有用的表示。
核心理念:
• 自動從原始數
Driver Monitoring System(駕駛員監控系統,簡稱 DMS)是一種車輛安全技術,用於實時監控駕駛員的行為和生理狀態,以識別疲勞、分心或其他注意力不集中情況,並及時發出警告或介入,從而提高行車安全。
主要功能:
• 監測駕駛員的眼動、視線方向、眨眼頻率和頭部位置,判斷疲勞或分
Fréchet Inception Distance(FID)是一種用於評估生成模型(特別是生成對抗網絡GAN)生成圖像質量和多樣性的指標。它通過比較生成圖像和真實圖像在深度特徵空間(通常使用Inception v3模型的中間層激活)中的分佈差異,衡量兩者之間的相似度。
FID 的特點與優勢:
Inception Score(IS)是一種用於評估生成式模型(特別是生成對抗網絡GAN)生成圖像質量和多樣性的指標。它利用一個預訓練的Inception v3圖像分類模型,對生成的圖像進行分類,評估圖像是否清晰且內容多樣。
Inception Score 的評估原理:
1. 圖像質量:對單張
Disentangled Representation Learning(解耦表示學習)是機器學習領域的一種表示學習方法,其目標是將數據中的潛在生成因子分離成彼此獨立且具備語義解釋性的子表示。換言之,它試圖把複雜、高維的數據表示,拆解成多個獨立並且意義明確的因子,便於模型理解與操作。
解耦表示學習
Unimodal 指的是系統或模型僅使用單一類型的數據模態來進行處理和分析。例如,只使用文字、只使用圖像,或只使用音頻等單一模態。
Unimodal 的特點:
• 單一數據來源:系統只處理一種類型的輸入數據,如僅圖像或僅文字。
• 結構相對簡單:由於處理單一模態,模型架構和訓練相對簡單。
AI Act(人工智慧法案)是歐洲聯盟(EU)於2024年8月1日生效的AI監管法規,是全球首個針對人工智慧系統的全面法律框架,旨在確保AI技術的安全性、透明度與合法合規使用。
AI Act 主要內容與特色:
• 風險分級管理:根據AI系統對健康、安全和基本權利的潛在風險,分類為四類——不可接
CCPA(California Consumer Privacy Act)是美國加州於2018年通過並於2020年1月1日生效的消費者隱私保護法案,旨在增強加州居民對其個人資料的控制權,提升數據透明度和隱私保護。
CCPA核心內容:
• 適用範圍:針對年營收超過2500萬美元、處理5萬名以上加
HIPAA(Health Insurance Portability and Accountability Act)即「健康保險可攜性和責任法案」,是美國於1996年通過的聯邦法律,旨在保障醫療資訊的隱私與安全,並促進醫療保險的可攜性和效率。
HIPAA的核心內容:
• 保護個人健康資訊(PH
AI Maturity Model(人工智慧成熟度模型)是一種戰略框架,用於評估和指導組織在AI技術的採用、整合和影響力方面的發展階段。它幫助企業了解自身在AI應用上的現狀,並規劃從試驗性項目到全面轉型的成長路徑。
AI Maturity Model的核心組成要素:
• 數據準備度:數據的質量
Lean Startup(精實創業)是一種結合精實生產理念與創業實踐的方法論,由矽谷創業家埃里克·里斯(Eric Ries)在2011年提出。它旨在幫助創業團隊在高度不確定的環境中快速開發產品,通過持續的實驗和學習,最大限度減少資源浪費,提高創業成功率。
Lean Startup 的核心原則:
淨推薦值(Net Promoter Score,簡稱NPS)是一種衡量顧客忠誠度和推薦意願的指標。企業用它來了解客戶對品牌、產品或服務的滿意度,並預測未來的顧客行為。
NPS 定義:
NPS 反映顧客向朋友或同事推薦企業的可能性,通常透過問卷調查一個問題:「您有多大可能會推薦我們的公司/產品給朋
SMART原則是一種目標設定方法,幫助個人或團隊設定明確、具體且可實現的目標,以提高達成目標的成功率。SMART是五個英文單詞首字母的縮寫,代表五大關鍵要素:
SMART五大要素:
• S - Specific(具體、明確)
目標需清楚且具體,避免含糊不清,讓執行者知道明確想要達成的內容。
黑盒子問題是指在人工智慧(尤其是深度學習等複雜模型)領域,模型的內部運作機制不透明,外部使用者或開發者無法明確理解模型如何從輸入映射到輸出決策的問題。
黑盒子問題的定義:
• 黑盒子(Black Box)形容模型內部像一個封閉系統,只能看到輸入和輸出,但無法直接解釋或觀察其內部運算過程。
風險矩陣(Risk Matrix)定義與概念:
風險矩陣是一種常見的風險評估工具,用來量化和可視化風險,通過將風險的「發生可能性」與「影響嚴重程度」兩個維度構建一個矩陣,將風險分級為高、中、低等不同風險等級,便於識別和管理。
風險矩陣的核心要素:
• 發生可能性(Likelihood):某風
淨現值(Net Present Value,簡稱 NPV)是一項投資評估指標,用於計算投資項目在未來各期預期現金流的折現值總和減去初始投資成本後的淨值,反映投資案的經濟效益。
簡單說明:
• 將未來每一期的現金流折現回現在,以反映錢的時間價值。
• 折現後的現金流總和減去初始投入,若NPV
AI Act(人工智慧法案)是歐洲聯盟(EU)於2024年8月1日生效的AI監管法規,是全球首個針對人工智慧系統的全面法律框架,旨在確保AI技術的安全性、透明度與合法合規使用。
AI Act 主要內容與特色:
• 風險分級管理:根據AI系統對健康、安全和基本權利的潛在風險,分類為四類——不可接
CCPA(California Consumer Privacy Act)是美國加州於2018年通過並於2020年1月1日生效的消費者隱私保護法案,旨在增強加州居民對其個人資料的控制權,提升數據透明度和隱私保護。
CCPA核心內容:
• 適用範圍:針對年營收超過2500萬美元、處理5萬名以上加
HIPAA(Health Insurance Portability and Accountability Act)即「健康保險可攜性和責任法案」,是美國於1996年通過的聯邦法律,旨在保障醫療資訊的隱私與安全,並促進醫療保險的可攜性和效率。
HIPAA的核心內容:
• 保護個人健康資訊(PH
AI Maturity Model(人工智慧成熟度模型)是一種戰略框架,用於評估和指導組織在AI技術的採用、整合和影響力方面的發展階段。它幫助企業了解自身在AI應用上的現狀,並規劃從試驗性項目到全面轉型的成長路徑。
AI Maturity Model的核心組成要素:
• 數據準備度:數據的質量
Lean Startup(精實創業)是一種結合精實生產理念與創業實踐的方法論,由矽谷創業家埃里克·里斯(Eric Ries)在2011年提出。它旨在幫助創業團隊在高度不確定的環境中快速開發產品,通過持續的實驗和學習,最大限度減少資源浪費,提高創業成功率。
Lean Startup 的核心原則:
淨推薦值(Net Promoter Score,簡稱NPS)是一種衡量顧客忠誠度和推薦意願的指標。企業用它來了解客戶對品牌、產品或服務的滿意度,並預測未來的顧客行為。
NPS 定義:
NPS 反映顧客向朋友或同事推薦企業的可能性,通常透過問卷調查一個問題:「您有多大可能會推薦我們的公司/產品給朋
SMART原則是一種目標設定方法,幫助個人或團隊設定明確、具體且可實現的目標,以提高達成目標的成功率。SMART是五個英文單詞首字母的縮寫,代表五大關鍵要素:
SMART五大要素:
• S - Specific(具體、明確)
目標需清楚且具體,避免含糊不清,讓執行者知道明確想要達成的內容。
黑盒子問題是指在人工智慧(尤其是深度學習等複雜模型)領域,模型的內部運作機制不透明,外部使用者或開發者無法明確理解模型如何從輸入映射到輸出決策的問題。
黑盒子問題的定義:
• 黑盒子(Black Box)形容模型內部像一個封閉系統,只能看到輸入和輸出,但無法直接解釋或觀察其內部運算過程。
風險矩陣(Risk Matrix)定義與概念:
風險矩陣是一種常見的風險評估工具,用來量化和可視化風險,通過將風險的「發生可能性」與「影響嚴重程度」兩個維度構建一個矩陣,將風險分級為高、中、低等不同風險等級,便於識別和管理。
風險矩陣的核心要素:
• 發生可能性(Likelihood):某風
淨現值(Net Present Value,簡稱 NPV)是一項投資評估指標,用於計算投資項目在未來各期預期現金流的折現值總和減去初始投資成本後的淨值,反映投資案的經濟效益。
簡單說明:
• 將未來每一期的現金流折現回現在,以反映錢的時間價值。
• 折現後的現金流總和減去初始投入,若NPV

PoC(Proof of Concept,概念驗證)與MVP(Minimum Viable Product,最小可行產品)是產品開發中的兩個關鍵階段,雖然有相似名稱但目的和應用不同。
PoC(概念驗證)
• 目標是驗證一個想法或技術的技術可行性。
• 主要用於確認核心功能或技術是否能實現,
Opex(Operating Expenditure,營運支出)是企業日常營運中持續發生的費用,用於支持企業的日常運作和維持業務運轉。
Opex 的定義與特點:
• Opex是短期且經常性的支出,如員工薪資、租金、水電費、辦公用品和維護費用。
• 與資本支出(Capex)不同,Opex直接
Capex(Capital Expenditure,資本支出)是企業用來購買、升級及維護長期資產的資金支出,這些資產通常包括土地、建築、機械設備、技術設備及軟體等,並在多個會計期間內產生經濟效益。
Capex 定義與特點:
• Capex為企業投資在固定資產上的支出,用於擴大經營規模或改善運營
Google TPU(Tensor Processing Unit)是谷歌設計的專用應用積體電路(ASIC),專門用於加速機器學習和深度學習工作負載,特別是使用TensorFlow框架的神經網絡運算。
TPU的定義與特點:
• TPU是為處理大量矩陣運算而設計的加速器,特別適用於神經網絡中大量
A/B測試是一種以數據驅動決策的實驗方法,通過同時向用戶展示兩個(或多個)版本的產品或內容(A版與B版),收集並比較用戶反應,以判斷哪個版本的效果更佳。
A/B測試的定義與原理:
• 將受眾隨機分成兩組,一組暴露於控制版(通常為現行版本,稱為A組),另一組暴露於變更版本(稱為B組)。
•

Big Bang、Phased Rollout 和 Canary Release 是三種常見的軟體部署策略,各自有不同的風險和應用場景:
1. Big Bang Deployment(大爆炸部署)
• 將所有的新功能、更新或變更一次性全部部署到生產環境。
• 優點:部署快速,適合小型或非關
Kanban是一種起源於日本豐田生產系統的敏捷軟體開發方法論,強調通過視覺化工作流程、限制在制品(Work In Progress, WIP)數量以及持續改進來優化生產和交付效率。
Kanban的定義:
• Kanban是一種以看板(Kanban Board)為核心工具的工作流程管理方法,讓團
Scrum是一種敏捷軟體開發框架,由Jeff Sutherland和Ken Schwaber於1990年代提出,設計用於幫助團隊在快速變動的環境中高效協作、迭代交付可用產品。
Scrum框架的定義:
• Scrum是一種輕量級框架,通過短週期的迭代(稱為Sprint),讓團隊持續交付價值。
敏捷開發(Agile Development)是一種軟體開發方法論,強調靈活性、快速回應變化與持續交付價值。它起源於2001年由一群軟體開發者提出的《敏捷軟體開發宣言》,核心目標是通過迭代開發和持續反饋,確保軟體能快速滿足客戶需求並持續改進。
敏捷開發的定義與特點:
• 將開發過程分解為一系列
瀑布模型(Waterfall Model)是一種傳統的軟體開發生命週期(SDLC)方法,於1970年由溫斯頓·W·羅伊斯(Winston W. Royce)提出。它將軟體開發過程劃分成嚴格的、線性排列的階段,開發過程如同瀑布一般由上而下依序進行,階段間不重疊,每個階段完成後才進入下一階段。
瀑布模
PoC(Proof of Concept,概念驗證)與MVP(Minimum Viable Product,最小可行產品)是產品開發中的兩個關鍵階段,雖然有相似名稱但目的和應用不同。
PoC(概念驗證)
• 目標是驗證一個想法或技術的技術可行性。
• 主要用於確認核心功能或技術是否能實現,
Opex(Operating Expenditure,營運支出)是企業日常營運中持續發生的費用,用於支持企業的日常運作和維持業務運轉。
Opex 的定義與特點:
• Opex是短期且經常性的支出,如員工薪資、租金、水電費、辦公用品和維護費用。
• 與資本支出(Capex)不同,Opex直接
Capex(Capital Expenditure,資本支出)是企業用來購買、升級及維護長期資產的資金支出,這些資產通常包括土地、建築、機械設備、技術設備及軟體等,並在多個會計期間內產生經濟效益。
Capex 定義與特點:
• Capex為企業投資在固定資產上的支出,用於擴大經營規模或改善運營
Google TPU(Tensor Processing Unit)是谷歌設計的專用應用積體電路(ASIC),專門用於加速機器學習和深度學習工作負載,特別是使用TensorFlow框架的神經網絡運算。
TPU的定義與特點:
• TPU是為處理大量矩陣運算而設計的加速器,特別適用於神經網絡中大量
A/B測試是一種以數據驅動決策的實驗方法,通過同時向用戶展示兩個(或多個)版本的產品或內容(A版與B版),收集並比較用戶反應,以判斷哪個版本的效果更佳。
A/B測試的定義與原理:
• 將受眾隨機分成兩組,一組暴露於控制版(通常為現行版本,稱為A組),另一組暴露於變更版本(稱為B組)。
•
Big Bang、Phased Rollout 和 Canary Release 是三種常見的軟體部署策略,各自有不同的風險和應用場景:
1. Big Bang Deployment(大爆炸部署)
• 將所有的新功能、更新或變更一次性全部部署到生產環境。
• 優點:部署快速,適合小型或非關
Kanban是一種起源於日本豐田生產系統的敏捷軟體開發方法論,強調通過視覺化工作流程、限制在制品(Work In Progress, WIP)數量以及持續改進來優化生產和交付效率。
Kanban的定義:
• Kanban是一種以看板(Kanban Board)為核心工具的工作流程管理方法,讓團
Scrum是一種敏捷軟體開發框架,由Jeff Sutherland和Ken Schwaber於1990年代提出,設計用於幫助團隊在快速變動的環境中高效協作、迭代交付可用產品。
Scrum框架的定義:
• Scrum是一種輕量級框架,通過短週期的迭代(稱為Sprint),讓團隊持續交付價值。
敏捷開發(Agile Development)是一種軟體開發方法論,強調靈活性、快速回應變化與持續交付價值。它起源於2001年由一群軟體開發者提出的《敏捷軟體開發宣言》,核心目標是通過迭代開發和持續反饋,確保軟體能快速滿足客戶需求並持續改進。
敏捷開發的定義與特點:
• 將開發過程分解為一系列
瀑布模型(Waterfall Model)是一種傳統的軟體開發生命週期(SDLC)方法,於1970年由溫斯頓·W·羅伊斯(Winston W. Royce)提出。它將軟體開發過程劃分成嚴格的、線性排列的階段,開發過程如同瀑布一般由上而下依序進行,階段間不重疊,每個階段完成後才進入下一階段。
瀑布模
聲譽風險(Reputation Risk)指的是由於企業或產品受到負面事件、信息曝光或用戶質疑,導致品牌信譽受損,影響其市場地位、客戶信任及營收的風險。在機器學習與人工智慧(AI)領域,聲譽風險特別關注AI系統可能帶來的負面影響,包括誤判、偏見、隱私泄露或生成不當內容,進而損害企業形象。
聲譽風險
數據重建攻擊(Data Reconstruction Attack)是一種針對機器學習模型的隱私攻擊,攻擊者試圖從模型的輸出或梯度資訊中反推原始訓練數據,重新構建敏感的數據樣本。
數據重建攻擊的定義與原理:
• 攻擊者通過攔截或獲得模型訓練過程中暴露的數據(如梯度、參數更新等),利用數學優化和
「成員推斷攻擊」(Membership Inference Attack)是一種針對機器學習模型的隱私攻擊技術。攻擊者目標是判斷某個特定數據樣本是否包含在模型的訓練數據中,從而推斷出用戶的敏感信息。
成員推斷攻擊的原理與工作方式:
• 攻擊者利用觀察模型輸出的差異,尤其是對訓練數據和未見過數據
演算法焦慮泛指因應對各類演算法系統(如社交媒體推薦、內容排序、流量指標等)的不確定性與影響,所產生的心理焦慮和壓力感。這種現象在數位時代普遍存在,尤其影響內容創作者、用戶及企業。
演算法焦慮的定義與主要成因:
• 定義:使用者因為過度關注演算法如何決定內容曝光、排名,導致自我價值與成功感受與演
藍隊演練(Blue Team Exercise)是指組織內部的資安防禦團隊進行的安全演練,目的是在遭受攻擊時迅速偵測、應對並防護,減少損害。與紅隊(攻擊方)模擬攻擊系統不同,藍隊聚焦於系統防禦、事件響應、漏洞修補及資安監控,是資安防護的重要環節。
藍隊演練的主要內容包括:
• 安全事件監控與日
紅隊演練(Red Team Exercise)是一種模擬真實攻擊者行為的安全測試方法,藉由主動對系統、應用或AI模型進行全面性的攻擊和挑戰,來評估系統的脆弱性與防禦能力,進而提升整體安全防護水平。
紅隊演練的主要特點與流程:
• 目標:模擬敵對攻擊者環境,發掘系統漏洞、弱點及安全風險。
•
HITL(Human-in-the-Loop)指的是機器學習或人工智慧系統中,人類能夠在系統設計、訓練、判斷或決策過程中介入的機制或流程。此方法結合人類專業知識與機器學習算法,以提高模型的準確度、可靠性和倫理性。
HITL的工作原理與特點:
• 人類參與數據標注、模型訓練數據清理、模型校正和實
Adversarial Attack(對抗性攻擊)是在機器學習中,攻擊者故意設計微小但精心修改的輸入(稱為對抗樣本),使模型產生錯誤判斷或錯誤預測的一種攻擊手法。這些微小的改動對人類觀察者來說幾乎無異,但能有效迷惑AI模型。
Adversarial Attack的定義和工作原理
• 攻擊者透過
評估人工智慧(AI)模型的公平性指標主要用來衡量模型在不同人口群體或個體之間是否表現出平等對待,避免偏見和歧視。這些指標可分為群體公平性指標、個體公平性指標,以及基於過程和結果的公平性指標。
主要公平性指標類型:
1. 群體公平性指標
• 統計均等性(Demographic Parity)
安全開發生命週期(Secure Software Development Life Cycle, SSDLC)是一種在軟體開發的各個階段(需求、設計、開發、測試、部署和維運)中主動整合安全和隱私考量的流程,目的是在軟體生命週期的每個階段降低安全風險與漏洞,提高軟體安全性與可靠性。
主要階段與內容
聲譽風險(Reputation Risk)指的是由於企業或產品受到負面事件、信息曝光或用戶質疑,導致品牌信譽受損,影響其市場地位、客戶信任及營收的風險。在機器學習與人工智慧(AI)領域,聲譽風險特別關注AI系統可能帶來的負面影響,包括誤判、偏見、隱私泄露或生成不當內容,進而損害企業形象。
聲譽風險
數據重建攻擊(Data Reconstruction Attack)是一種針對機器學習模型的隱私攻擊,攻擊者試圖從模型的輸出或梯度資訊中反推原始訓練數據,重新構建敏感的數據樣本。
數據重建攻擊的定義與原理:
• 攻擊者通過攔截或獲得模型訓練過程中暴露的數據(如梯度、參數更新等),利用數學優化和
「成員推斷攻擊」(Membership Inference Attack)是一種針對機器學習模型的隱私攻擊技術。攻擊者目標是判斷某個特定數據樣本是否包含在模型的訓練數據中,從而推斷出用戶的敏感信息。
成員推斷攻擊的原理與工作方式:
• 攻擊者利用觀察模型輸出的差異,尤其是對訓練數據和未見過數據
演算法焦慮泛指因應對各類演算法系統(如社交媒體推薦、內容排序、流量指標等)的不確定性與影響,所產生的心理焦慮和壓力感。這種現象在數位時代普遍存在,尤其影響內容創作者、用戶及企業。
演算法焦慮的定義與主要成因:
• 定義:使用者因為過度關注演算法如何決定內容曝光、排名,導致自我價值與成功感受與演
藍隊演練(Blue Team Exercise)是指組織內部的資安防禦團隊進行的安全演練,目的是在遭受攻擊時迅速偵測、應對並防護,減少損害。與紅隊(攻擊方)模擬攻擊系統不同,藍隊聚焦於系統防禦、事件響應、漏洞修補及資安監控,是資安防護的重要環節。
藍隊演練的主要內容包括:
• 安全事件監控與日
紅隊演練(Red Team Exercise)是一種模擬真實攻擊者行為的安全測試方法,藉由主動對系統、應用或AI模型進行全面性的攻擊和挑戰,來評估系統的脆弱性與防禦能力,進而提升整體安全防護水平。
紅隊演練的主要特點與流程:
• 目標:模擬敵對攻擊者環境,發掘系統漏洞、弱點及安全風險。
•
HITL(Human-in-the-Loop)指的是機器學習或人工智慧系統中,人類能夠在系統設計、訓練、判斷或決策過程中介入的機制或流程。此方法結合人類專業知識與機器學習算法,以提高模型的準確度、可靠性和倫理性。
HITL的工作原理與特點:
• 人類參與數據標注、模型訓練數據清理、模型校正和實
Adversarial Attack(對抗性攻擊)是在機器學習中,攻擊者故意設計微小但精心修改的輸入(稱為對抗樣本),使模型產生錯誤判斷或錯誤預測的一種攻擊手法。這些微小的改動對人類觀察者來說幾乎無異,但能有效迷惑AI模型。
Adversarial Attack的定義和工作原理
• 攻擊者透過
評估人工智慧(AI)模型的公平性指標主要用來衡量模型在不同人口群體或個體之間是否表現出平等對待,避免偏見和歧視。這些指標可分為群體公平性指標、個體公平性指標,以及基於過程和結果的公平性指標。
主要公平性指標類型:
1. 群體公平性指標
• 統計均等性(Demographic Parity)
安全開發生命週期(Secure Software Development Life Cycle, SSDLC)是一種在軟體開發的各個階段(需求、設計、開發、測試、部署和維運)中主動整合安全和隱私考量的流程,目的是在軟體生命週期的每個階段降低安全風險與漏洞,提高軟體安全性與可靠性。
主要階段與內容
決定係數(Coefficient of Determination),通常以 R^2 表示,是衡量迴歸模型擬合效果的一個統計指標。它代表模型解釋的目標變量變異的比例,用於評估模型對數據的解釋能力。
R^2 = 1 表示模型完美擬合數據(預測值完全等於真實值);
R^2 表示模型表現等同於只用平均
Target Encoding(目標編碼)是一種用於機器學習中處理類別變數的編碼技術,特別適合高基數(高種數量)類別特徵。它通過將類別值替換成該類別在目標變量上的統計值(通常是目標的均值),使模型能夠有效利用類別與目標之間的關聯信息。
Target Encoding原理
對於分類或回歸問題,計算
Ordinal Encoding(序數編碼)是一種將**有序類別型變數**(ordinal categorical variables)轉換為數值型變數的編碼方法。它依據類別之間的固有順序,將每個類別分配一個整數,以保留類別間的大小或等級關係,常用於機器學習的數據預處理階段。
Ordinal En
支持向量機(SVM)的核技巧(Kernel Trick)是一種用來解決非線性分類問題的有效方法。它的核心思想是將原本不可線性分離的數據,透過一個非線性映射函數,投射到高維度的特徵空間中,使數據在高維空間可線性分割,然後再在該空間中運用線性支持向量機進行分類。
核技巧優點
能有效解決高維非線性
分層抽樣(Stratified Sampling)是一種統計抽樣方法,將總體按特定特徵或規則劃分為若干個同質的子群組(稱為層),然後對每個層內獨立進行隨機抽樣。這種方法結合了分組與隨機抽樣的優點,提高了樣本的代表性和估計的精度。
分層抽樣的原理與步驟
劃分層次:根據變量(如年齡、性別、地區)將
robots.txt協議是一種網站用來指示網路爬蟲(如搜尋引擎機器人)哪些頁面可以爬取、哪些禁止訪問的標準協議。它通過在網站根目錄放置一個名為「robots.txt」的純文字文件,控制爬蟲的爬取行為,幫助網站控制流量和保護私有內容,同時優化搜尋引擎的爬取效率。
robots.txt的主要功能
限
PR曲線(Precision-Recall Curve,精確率-召回率曲線)是一種用來評估分類模型性能,特別是二分類任務中,通過不同分類閾值下的精確率(Precision)與召回率(Recall)的變化關係繪製而成的曲線。
PR曲線定義:
橫軸(X軸)是召回率(Recall),表示模型在所有實際
線性回歸的基本假設是指在建立線性回歸模型時對數據和誤差項提出的前提條件,這些假設保證了模型的合理性和統計推論的有效性。主要有以下幾個核心假設:
1. 線性關係
應變數(Y)和自變數(X)之間存在線性關係,即模型形式可表達為
2. 誤差項期望為零
誤差項的期望值為零,表示誤差沒有系統性的偏差
對數轉換(Logarithmic Transformation)是將數據中的每個值轉換為其對數值的過程,常用於數據分析和機器學習中,以改善數據分佈、降低偏態,並使數據更接近常態分布。
對數轉換的主要目的
減少偏態(Skewness):將右偏分佈的數據拉近對稱,有利於統計模型的假設;
縮小數據範
缺失值模式是指數據中缺失值的產生和存在的機制,理解不同模式有助於選擇合適的缺失值處理方法。數據科學和機器學習中,缺失值主要分為三種類型:
1. 完全隨機缺失(MCAR, Missing Completely At Random)
缺失值的產生完全隨機,與數據中任何其他變量的值無關。
換句話說,
決定係數(Coefficient of Determination),通常以 R^2 表示,是衡量迴歸模型擬合效果的一個統計指標。它代表模型解釋的目標變量變異的比例,用於評估模型對數據的解釋能力。
R^2 = 1 表示模型完美擬合數據(預測值完全等於真實值);
R^2 表示模型表現等同於只用平均
Target Encoding(目標編碼)是一種用於機器學習中處理類別變數的編碼技術,特別適合高基數(高種數量)類別特徵。它通過將類別值替換成該類別在目標變量上的統計值(通常是目標的均值),使模型能夠有效利用類別與目標之間的關聯信息。
Target Encoding原理
對於分類或回歸問題,計算
Ordinal Encoding(序數編碼)是一種將**有序類別型變數**(ordinal categorical variables)轉換為數值型變數的編碼方法。它依據類別之間的固有順序,將每個類別分配一個整數,以保留類別間的大小或等級關係,常用於機器學習的數據預處理階段。
Ordinal En
支持向量機(SVM)的核技巧(Kernel Trick)是一種用來解決非線性分類問題的有效方法。它的核心思想是將原本不可線性分離的數據,透過一個非線性映射函數,投射到高維度的特徵空間中,使數據在高維空間可線性分割,然後再在該空間中運用線性支持向量機進行分類。
核技巧優點
能有效解決高維非線性
分層抽樣(Stratified Sampling)是一種統計抽樣方法,將總體按特定特徵或規則劃分為若干個同質的子群組(稱為層),然後對每個層內獨立進行隨機抽樣。這種方法結合了分組與隨機抽樣的優點,提高了樣本的代表性和估計的精度。
分層抽樣的原理與步驟
劃分層次:根據變量(如年齡、性別、地區)將
robots.txt協議是一種網站用來指示網路爬蟲(如搜尋引擎機器人)哪些頁面可以爬取、哪些禁止訪問的標準協議。它通過在網站根目錄放置一個名為「robots.txt」的純文字文件,控制爬蟲的爬取行為,幫助網站控制流量和保護私有內容,同時優化搜尋引擎的爬取效率。
robots.txt的主要功能
限
PR曲線(Precision-Recall Curve,精確率-召回率曲線)是一種用來評估分類模型性能,特別是二分類任務中,通過不同分類閾值下的精確率(Precision)與召回率(Recall)的變化關係繪製而成的曲線。
PR曲線定義:
橫軸(X軸)是召回率(Recall),表示模型在所有實際
線性回歸的基本假設是指在建立線性回歸模型時對數據和誤差項提出的前提條件,這些假設保證了模型的合理性和統計推論的有效性。主要有以下幾個核心假設:
1. 線性關係
應變數(Y)和自變數(X)之間存在線性關係,即模型形式可表達為
2. 誤差項期望為零
誤差項的期望值為零,表示誤差沒有系統性的偏差
對數轉換(Logarithmic Transformation)是將數據中的每個值轉換為其對數值的過程,常用於數據分析和機器學習中,以改善數據分佈、降低偏態,並使數據更接近常態分布。
對數轉換的主要目的
減少偏態(Skewness):將右偏分佈的數據拉近對稱,有利於統計模型的假設;
縮小數據範
缺失值模式是指數據中缺失值的產生和存在的機制,理解不同模式有助於選擇合適的缺失值處理方法。數據科學和機器學習中,缺失值主要分為三種類型:
1. 完全隨機缺失(MCAR, Missing Completely At Random)
缺失值的產生完全隨機,與數據中任何其他變量的值無關。
換句話說,

Terraform 與 AWS CloudFormation 都是「基礎設施即程式碼」(IaC)工具,可用於自動化雲端資源部署,但在應用範圍、語法、彈性等方面有明顯差異:
適用場景
Terraform:跨平台/多雲部署、現有資源匯入與自訂模組、團隊合作及複製混合雲架構。
CloudFormat
分散式文件系統是一種將文件資料分散儲存到多台電腦(伺服器或節點)上的技術,常見代表如 HDFS(Hadoop Distributed File System)。這類系統特點如下:
HDFS 原理與架構
文件分割與分散存儲:大檔案會被分割為多個資料區塊(Block),每個區塊分散儲存於不同伺服器,

Jaeger與Zipkin都是主流的分布式追蹤工具,用來可視化及分析微服務架構中跨服務的請求路徑與效能瓶頸。
工具簡介
Jaeger由Uber開發,目前是CNCF畢業專案,支援高可擴展性、大量資料及多種儲存後端(如Elasticsearch、Cassandra),適合大中型、Kubernetes
滲透測試(Penetration Testing,簡稱 Pen Test)是資安領域的一種安全測試方法,由具有授權的專業人員模擬黑客攻擊,試圖發現並利用系統、網路或應用程式中的漏洞,評估其安全防護的強弱與風險。
主要目的
積極發掘系統弱點與潛在安全風險
測試企業防禦機制在真實攻擊模型下的效能
Circuit Breaking(斷路器模式)是一種分散式系統和微服務架構中常用的設計模式,目的在於提升系統韌性和容錯能力。它類似電路中的斷路器原理,當檢測到下游服務連續失敗或故障時,會「斷開」請求連接,防止系統持續發送請求給失效的服務,避免故障蔓延造成系統崩潰或資源耗盡。
Circuit Bre
模型量化(Model Quantization)是機器學習中將模型的權重和/或激活值從高精度浮點數(如32位浮點)轉換為低精度格式(如8位整數)的技術,目的是減少模型的存儲空間和運算成本,從而提升推論速度並降低功耗,同時盡可能保持模型的準確度。
主要量化技術
後訓練量化(Post-Trainin
ELK Stack 通常指由三個核心元件組成的日誌與搜尋分析平台:Elasticsearch、Logstash、Kibana(後來常連同 Beats 一起稱為 Elastic Stack)。它用於集中化收集、儲存、搜尋與可視化各系統與應用的日誌與事件資料,支援可觀察性、SIEM、安全分析與商業分析等
RESTful API 是一種遵循 REST(表述性狀態轉移)架構風格設計的網路服務介面,強調以資源為中心、使用標準 HTTP 方法、無狀態通訊與一致介面,讓用戶端與伺服端鬆耦合、可擴展且易於維護。
核心約束
客戶端-伺服端分離:前後端職責分離,可獨立演進,只需遵守約定的資源契約與格式。
無狀
SOA(Service-Oriented Architecture,面向服務架構)是一種以「服務」為邏輯單位來設計與構建分散式系統的軟體架構風格。核心思想是將可重用的業務能力封裝為鬆耦合、可組合、透過標準介面存取的服務,促進跨系統整合、敏捷開發與治理。
核心理念
服務是自治的、明確定義契約的業務
什麼是 XAI 工具
XAI 工具協助解釋與審視模型的輸出與行為,包括特徵重要度、局部決策依據、對抗與偏見偵測、資料與概念漂移、以及端到端監控與稽核。它們可分為「訓練後解釋」與「可解釋模型」兩大類,並延伸到MLOps監控與治理。
常見方法族群
全域解釋:特徵重要度、全域部分依賴關係(PDP/
Terraform 與 AWS CloudFormation 都是「基礎設施即程式碼」(IaC)工具,可用於自動化雲端資源部署,但在應用範圍、語法、彈性等方面有明顯差異:
適用場景
Terraform:跨平台/多雲部署、現有資源匯入與自訂模組、團隊合作及複製混合雲架構。
CloudFormat
分散式文件系統是一種將文件資料分散儲存到多台電腦(伺服器或節點)上的技術,常見代表如 HDFS(Hadoop Distributed File System)。這類系統特點如下:
HDFS 原理與架構
文件分割與分散存儲:大檔案會被分割為多個資料區塊(Block),每個區塊分散儲存於不同伺服器,
Jaeger與Zipkin都是主流的分布式追蹤工具,用來可視化及分析微服務架構中跨服務的請求路徑與效能瓶頸。
工具簡介
Jaeger由Uber開發,目前是CNCF畢業專案,支援高可擴展性、大量資料及多種儲存後端(如Elasticsearch、Cassandra),適合大中型、Kubernetes
滲透測試(Penetration Testing,簡稱 Pen Test)是資安領域的一種安全測試方法,由具有授權的專業人員模擬黑客攻擊,試圖發現並利用系統、網路或應用程式中的漏洞,評估其安全防護的強弱與風險。
主要目的
積極發掘系統弱點與潛在安全風險
測試企業防禦機制在真實攻擊模型下的效能
Circuit Breaking(斷路器模式)是一種分散式系統和微服務架構中常用的設計模式,目的在於提升系統韌性和容錯能力。它類似電路中的斷路器原理,當檢測到下游服務連續失敗或故障時,會「斷開」請求連接,防止系統持續發送請求給失效的服務,避免故障蔓延造成系統崩潰或資源耗盡。
Circuit Bre
模型量化(Model Quantization)是機器學習中將模型的權重和/或激活值從高精度浮點數(如32位浮點)轉換為低精度格式(如8位整數)的技術,目的是減少模型的存儲空間和運算成本,從而提升推論速度並降低功耗,同時盡可能保持模型的準確度。
主要量化技術
後訓練量化(Post-Trainin
ELK Stack 通常指由三個核心元件組成的日誌與搜尋分析平台:Elasticsearch、Logstash、Kibana(後來常連同 Beats 一起稱為 Elastic Stack)。它用於集中化收集、儲存、搜尋與可視化各系統與應用的日誌與事件資料,支援可觀察性、SIEM、安全分析與商業分析等
RESTful API 是一種遵循 REST(表述性狀態轉移)架構風格設計的網路服務介面,強調以資源為中心、使用標準 HTTP 方法、無狀態通訊與一致介面,讓用戶端與伺服端鬆耦合、可擴展且易於維護。
核心約束
客戶端-伺服端分離:前後端職責分離,可獨立演進,只需遵守約定的資源契約與格式。
無狀
SOA(Service-Oriented Architecture,面向服務架構)是一種以「服務」為邏輯單位來設計與構建分散式系統的軟體架構風格。核心思想是將可重用的業務能力封裝為鬆耦合、可組合、透過標準介面存取的服務,促進跨系統整合、敏捷開發與治理。
核心理念
服務是自治的、明確定義契約的業務
什麼是 XAI 工具
XAI 工具協助解釋與審視模型的輸出與行為,包括特徵重要度、局部決策依據、對抗與偏見偵測、資料與概念漂移、以及端到端監控與稽核。它們可分為「訓練後解釋」與「可解釋模型」兩大類,並延伸到MLOps監控與治理。
常見方法族群
全域解釋:特徵重要度、全域部分依賴關係(PDP/


A. Virtual Private Gateway (VGW) —— 「單一 VPC 的專用私有門口」
它是什麼:位於 AWS 側的 VPN 集中器,專門用於建立與本地辦公室/資料中心的私有連接。
使用時機:簡單的 Site-to-Site VPN:當你只需要將 「一個」 特定 VPC 與公司
AWS 安全最佳實務主要來自 AWS Well-Architected Framework 的安全支柱,強調保護資料、系統和資產,同時滿足業務需求。
身份與存取管理
實施最小權限原則,使用 IAM 角色而非長期存取金鑰,並強制多因素認證 (MFA),尤其是根帳戶。
定期輪換存取金鑰,每 3

Each organization’s cloud journey is unique. To succeed in your transformation, you’ll need to envision your desired target state, understand your clo

商業視角:策略與成果 Business perspective: strategy and outcomes
從商業角度來看,重點在於確保您的雲端投資能夠加速實現您的數位轉型目標和業務成果。它包含下圖所示的八項能力。常見的利害關係人包括執行長 (CEO)、財務長 (CFO)、首席營運長 (CO
卓越營運有五項設計原則:
將操作視為程式碼:在雲端,您可以將用於應用程式程式碼的相同工程規範套用到整個環境。您可以將整個工作負載(應用程式、基礎架構)定義為程式碼,並使用程式碼進行更新。您可以將操作流程實作為程式碼,並透過回應事件來觸發它們,從而實現流程的自動化執行。透過將操作視為程式碼,您可以減
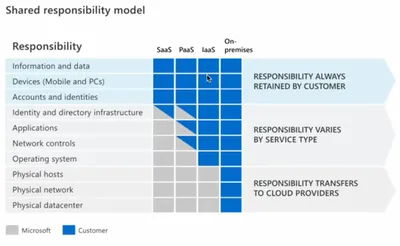

Stateful 和 Stateless 是 AWS VPC 安全控制的核心差異,對應 Security Group(狀態性)和 Network ACL(無狀態性),決定流量回應是否自動允許。
運作機制
Stateful 機制追蹤連線狀態(如 TCP SYN/ACK),允許進流量後自動放行回應

AWS managed IAM policy 和 custom(customer managed)IAM policy 都是「managed policy」,差異在於誰維護、可否調整與授權精細度。
基本定義
AWS managed policy:由 AWS 官方建立與維護的通用權限策略,例如
AWS 的全球基礎設施(Global Infrastructure)是圍繞著**區域(Regions)和可用區域(Availability Zones, AZs)**構建的。這是 AWS 考試和架構設計中最基礎也最重要的概念。
截至 2025 年,AWS 全球基礎設施主要包含以下幾個核心組件:
A. Virtual Private Gateway (VGW) —— 「單一 VPC 的專用私有門口」
它是什麼:位於 AWS 側的 VPN 集中器,專門用於建立與本地辦公室/資料中心的私有連接。
使用時機:簡單的 Site-to-Site VPN:當你只需要將 「一個」 特定 VPC 與公司
AWS 安全最佳實務主要來自 AWS Well-Architected Framework 的安全支柱,強調保護資料、系統和資產,同時滿足業務需求。
身份與存取管理
實施最小權限原則,使用 IAM 角色而非長期存取金鑰,並強制多因素認證 (MFA),尤其是根帳戶。
定期輪換存取金鑰,每 3
Each organization’s cloud journey is unique. To succeed in your transformation, you’ll need to envision your desired target state, understand your clo
商業視角:策略與成果 Business perspective: strategy and outcomes
從商業角度來看,重點在於確保您的雲端投資能夠加速實現您的數位轉型目標和業務成果。它包含下圖所示的八項能力。常見的利害關係人包括執行長 (CEO)、財務長 (CFO)、首席營運長 (CO
卓越營運有五項設計原則:
將操作視為程式碼:在雲端,您可以將用於應用程式程式碼的相同工程規範套用到整個環境。您可以將整個工作負載(應用程式、基礎架構)定義為程式碼,並使用程式碼進行更新。您可以將操作流程實作為程式碼,並透過回應事件來觸發它們,從而實現流程的自動化執行。透過將操作視為程式碼,您可以減
Stateful 和 Stateless 是 AWS VPC 安全控制的核心差異,對應 Security Group(狀態性)和 Network ACL(無狀態性),決定流量回應是否自動允許。
運作機制
Stateful 機制追蹤連線狀態(如 TCP SYN/ACK),允許進流量後自動放行回應
AWS managed IAM policy 和 custom(customer managed)IAM policy 都是「managed policy」,差異在於誰維護、可否調整與授權精細度。
基本定義
AWS managed policy:由 AWS 官方建立與維護的通用權限策略,例如
AWS 的全球基礎設施(Global Infrastructure)是圍繞著**區域(Regions)和可用區域(Availability Zones, AZs)**構建的。這是 AWS 考試和架構設計中最基礎也最重要的概念。
截至 2025 年,AWS 全球基礎設施主要包含以下幾個核心組件:

