
前言
接續上一篇: Stable Diffusion -- 訓練LoRA(三) ,我們開始用準備好的訓練素材圖跟規範圖來烘焙我們的LoRA。
訓練
我們開始使用另一個Colab頁面來執行真正的訓練步驟:https://colab.research.google.com/github/hollowstrawberry/kohya-colab/blob/main/Lora_Trainer.ipynb
這個版本的Colab訓練頁面多了一些與規範圖相關的功能,在執行訓練前,我們要來指定素材圖與規範圖擺放的目錄。
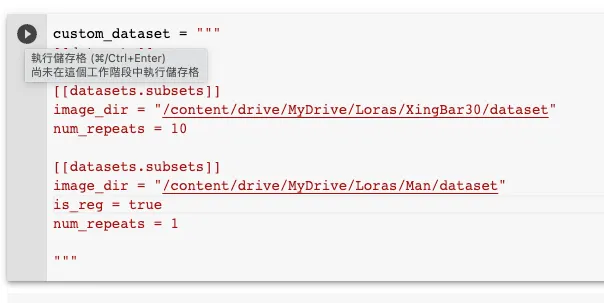
先往下捲動到Extras區,找到Multiple folders in dataset這個區塊,將裡面的數值改成這樣:
custom_dataset = """
[[datasets]]
[[datasets.subsets]]
image_dir = "/content/drive/MyDrive/Loras/{專案目錄名}/dataset"
num_repeats = 10
[[datasets.subsets]]
image_dir = "/content/drive/MyDrive/Loras/{規範圖目錄名}/dataset"
is_reg = true
num_repeats = 1
"""
在這裡,專案目錄名就是你擺放的素材圖的地方,以我為例,就是XingBar30。
接著的num_repeats是每個素材圖會被訓練的次數,通常是總圖數乘上本數值要等於300到400。因為我的素材總共有30張,所以我選擇10這個數字,這樣每回合就會被訓練300次。
而規範圖目錄名則是你放置規範圖的目錄,在本例中我將男性圖片的規範圖放在Man這個目錄底下。
要注意的是,is_reg = true一定要放在規範圖這一小節的地方,否則訓練程式會認不出來,這樣訓練出來的LoRA會完全做不出你要的角色。
通通設定完之後就可以執行這個小節的程式。
這格執行完之後,我們就可以開始在Setup小節填入其他資料了。
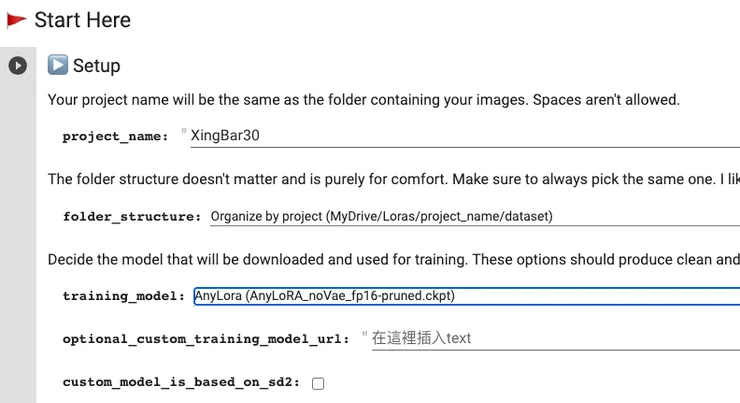
project_name這邊填入專案目錄名,例如XingBar30。
training_model目前有三個選項,如果是動漫傾向的角色,可以用Anime這個模型,否則用AnyLoRA就好。以我個人三種都試過的經驗,影響似乎不大。
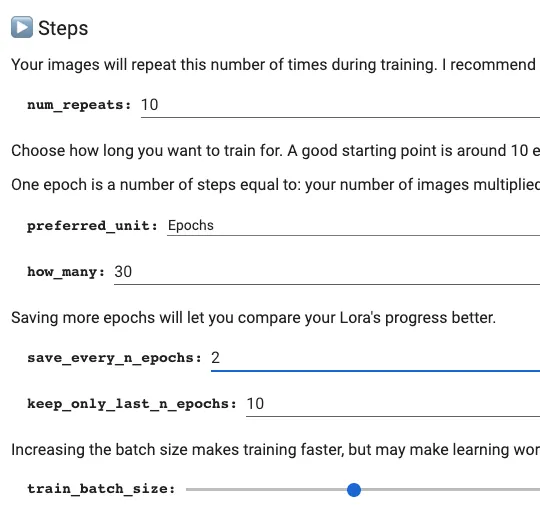
在Step步驟,我只有改變how_many到20或30回合。這樣可以得到品質更好的成果。
總訓練步數的計算方法是:
素材圖張數 X 每張訓練次數 X 總回合數。
以我的例子就是 30 X 10 X 30 = 9000。
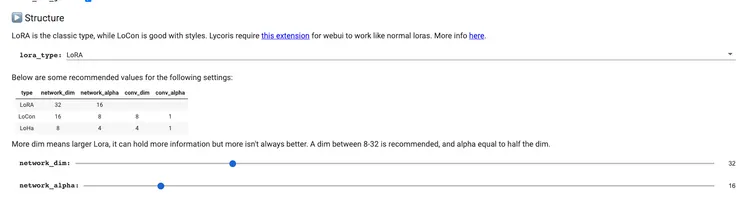
最後是AI訓練參數,這邊作者有特別提到不同類型的模型需要不同的參數,我們訓練的LoRA的推薦參數是:
network_dim: 32
network_alpha: 16
其他則保持原樣。
一切都設定好之後,就可以按下執行,開始訓練LoRA了!

在執行紀錄裡面,請一定要確認Multiple folders in dataset裡面的設定有正確執行,你可以看到類似這樣的紀錄跑出來:

以我個人的經驗,Colab的GPU一個小時可以跑大約6000步,所以一個9000步的LoRA訓練可以在一個半小時之內跑完。
由於我時常使用Colab來跑這些東西,所以索性買了Colab的點數,通常訓練LoRA的時候,一個小時消耗2個點數,也就是說10美金的Colab點數100點,可以讓我們訓練50小時,算是蠻實惠的。
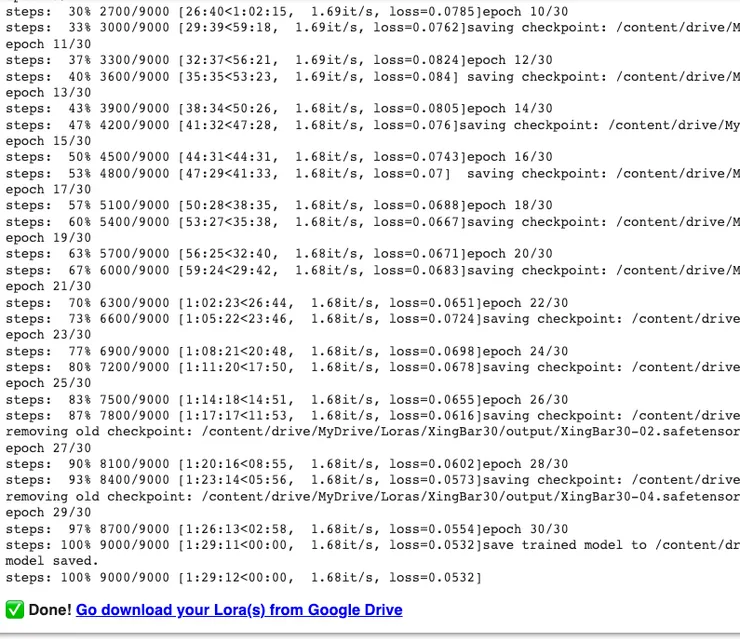
訓練出來的LoRA檔案,就在雲端硬碟的output目錄下,點下Done連結會自動打開該目錄,讓你可以下載。
常見錯誤
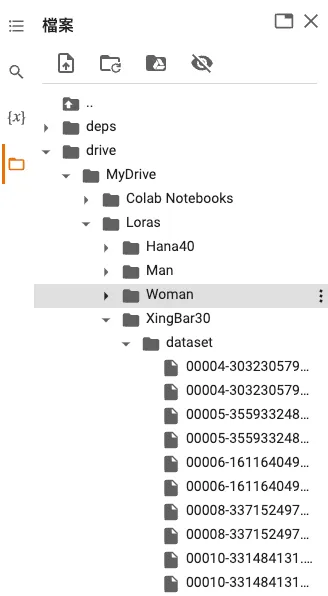
訓練最常出錯的地方,是沒有把素材圖跟規範圖放到正確的目錄下,使得程式找不到圖而停止。要是程式很快就停止了,請在Colab左側的欄位上點開檔案目錄,查看自己的檔案結構是不是類似這樣:
驗證
LoRA訓練完成之後,下載下來到/models/Lora/目錄,重開Automatic1111,在Lora標籤下按下Refresh,應該就能看到自己訓練的LoRA了。
要驗證自己的LoRA有沒有用,最簡單的就是用較低的權重直接產生一張圖,比較一下自己的素材圖,如果不像的話,試著調高權重到0.7再試試,如果還是不像,那就是訓練失敗了。

當確認LoRA有成功之後,接下來就要來比較同一角色不同版本的LoRA的成效,通常我們會使用X/Y/Z plot來做全面的比對。X/Y/Z plot的詳細用法請參考:
Stable Diffusion進階 -- X/Y/Z plot
我最常用:
X軸:各種動作
Y軸:幾個常用的模型
Z軸:兩個不同版本的LoRA使用同樣的權重
比較不同的版本LoRA,來確定新版本更合你意。

確認了新版本LoRA表現更佳之後,就可以繼續用X/Y/Z plot來深入探究在各種模型上,最好的權重是多少,每個模型最適合的權重都有些不一樣,品質好的LoRA可以在高權重時,在不同模型上依舊產生特徵一樣的角色,而且同時不摧毀原模型的畫質。

在這邊,如果各種驗證步驟都沒有出什麼大問題,恭喜你,你已經烘焙好一個高品質,穩定的角色LoRA了!
結語
訓練LoRA是很吃耐心跟細心的,很多時候,就是素材圖或規範圖的圖樣不一致,或者素材的文字檔忘了刪除某些提示詞,於是角色特徵沒有正確融入這個LoRA,一切就要從頭再訓練。但是當你正確產生了第一個高品質LoRA之後,依照同樣的步驟,就能一遍又一遍將你夢想中的角色製作出來,用在任何模型上!這種成就感是非常讓人滿足的。

祝大家算圖愉快!
LoRA目錄:


























