大家好,我是Hivan。
好久不见了,今天我们来讨论下如何让机器拥有声音。
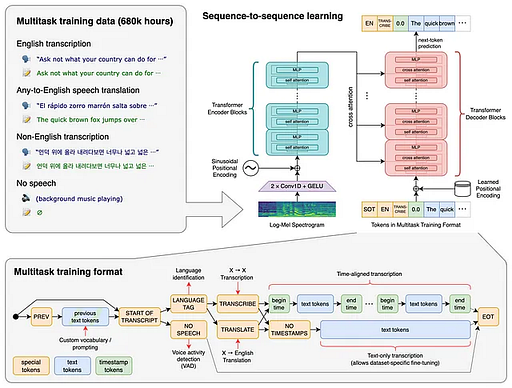
回顾一下我们上一讲的内容,我们已经成功使用Whisper模型使得AI能够理解我们说的话。这为我们带来了很多应用,例如让AI代替我们收听播客并总结内容。然而,这只是单向的交流模式。现在,让我们探索更深入的可能性,让AI不仅仅能够“听懂”我们的话,而且通过ChatGPT回答我们的问题,并将所有内容合成语音,用声音与我们进行双向交互。
这就是我们本次探索的主题:让AI说话。我们将学习如何使用云端API进行语音合成(Text-To-Speech),同时也会介绍开源模型,使您能够在本地CPU上实现这一功能,让数据安全问题不再是困扰。
让我们一起,给机器赋予声音吧!