簡單的說法語言模型就是自然語言中的詞語機率分佈模型,語言模型可以確定哪個詞語出現的可能性更大,或者通過若干上文語境詞來預測下一個最可能出現的詞語。
中文白話說的例子,用nGram來看,如果透過結巴或中研院等工具"斷詞"後的結果,可以想像兩句話(個別獨立的兩句話,從"我"開始,看後面接龍的機率: 我今天(明天)中午(晚上)想吃燒酒雞(我 今天 中午 想 吃 燒酒雞)或(我 明天 晚上 想 吃 燒酒雞) 出現的機率<=假設上面這兩句作為例子的斷詞完的結果,那麼如果用Unigram來看(單詞-單詞間的關係),他會是:
{
"我": 0.25,
"今天": 0.20,
"明天": 0.15,
"中午": 0.10,
"晚上": 0.15,
"想": 0.05,
"吃": 0.03,
"燒酒雞": 0.07,
}
個別的單詞與單詞間的關係長相會是像上面的描述,而如果"不要"斷詞的話,因為中文不像英文天然的有空格當作字與字的分隔,所以你可以想像他可能會是:
{
"我": 0.35,
"今": 0.05,
"明": 0.04,
"天": 0.10,
"中": 0.06,
"午": 0.05,
"晚": 0.05,
"上": 0.05,
"想": 0.05,
"吃": 0.05,
"燒": 0.05,
"酒": 0.04,
"雞": 0.06,
}
或是(假設故意用標點符號冒充像英文的空格):
{
"我今天中午想吃燒酒雞": 0.5,
"我明天晚上想吃燒酒雞": 0.5,
"還是你有別的想法": 0.25,
"我們討論看看再決定好不好": 0.25,
}
透過這樣的說明,大家應該可以有個粗淺的認識。
然後在接龍之後有個重要的東西是字詞向量獨立語意模式Word Embedding,他很在意獨立語意個別的關係,將個別的字詞投影到空間上,形成一個詞與詞可以進行運算的維度空間模式。(跟接龍有一點點不大一樣),詳情可以參考這邊:https://zh.wikipedia.org/zh-tw/%E8%AF%8D%E5%B5%8C%E5%85%A5
比較有影響的實作參考:
Word2vec是自然語言處理(NLP)中的一項技術,用於取得單字的向量表示。這些向量根據周圍的單字捕獲有關單字意義的資訊。 word2vec 演算法透過對大型語料庫中的文字進行建模來估計這些表示。經過訓練,這樣的模型可以偵測同義詞或為部分句子建議附加單字。 Word2vec 由Tomáš Mikolov和 Google 的同事開發,於 2013 年發布。
Word2vec 將單字表示為高維數字向量,用於捕捉單字之間的關係。特別是,出現在相似上下文中的單字被映射到透過餘弦相似度測量的附近的向量。這顯示了單字之間的語義相似程度,例如walk和ran的向量很接近,but和然而以及Berlin和German 的向量也很接近。
FastText 是一個開源、免費、輕量級的函式庫,可讓使用者學習文字表示和文字分類器。它適用於標準的通用硬體。隨後可以縮小模型的尺寸,甚至可以適應行動裝置。
英文向量:
https://fasttext.cc/docs/en/english-vectors.html
多國語言向量:
https://fasttext.cc/docs/en/crawl-vectors.html
GloVe 是一種用於獲取單字向量表示的無監督學習演算法。訓練是對來自語料庫的聚合的全局詞-詞共現統計數據進行的,所得的表示展示了詞向量空間的有趣的線性子結構。
中文資源參考:
英文資源參考:
GloVe: Global Vectors for Word Representation (stanford.edu)
接著我們就來看看近年影像最大的Transformers,他發展出來的重要應用參考點:
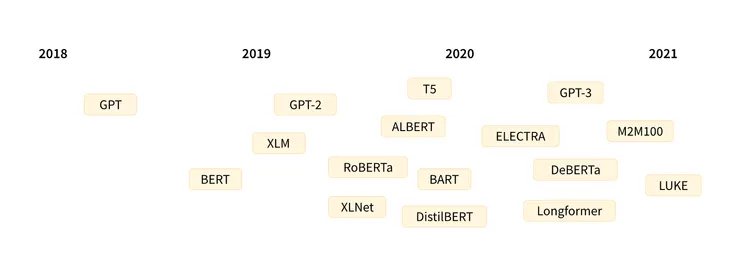
Transformer 架構於2017 年 6 月推出。隨後推出了幾個有影響力的模型,包括:
- 2018年6月:GPT,第一個預先訓練的Transformer模型,用於對各種NLP任務進行微調,並獲得了state-of-the-art的結果
- 2018 年 10 月:BERT,另一個大型預訓練模型,旨在產生更好的句子摘要(下一章將詳細介紹!)
- 2019 年 2 月:GPT-2,GPT 的改進(和更大)版本,由於道德問題沒有立即公開發布
- 2019 年 10 月:DistilBERT,BERT 的精煉版,速度提高了 60%,記憶體減少了 40%,但仍保留了 BERT 97% 的效能
- 2019 年 10 月:BART和T5,兩個大型預訓練模型,使用與原始 Transformer 模型相同的架構(第一個這樣做的)
- 2020 年 5 月,GPT-3,GPT-2 的更大版本,能夠在各種任務上表現良好,無需微調(稱為零樣本學習)
這個清單遠非全面,只是為了強調一些不同類型的 Transformer 模型。概括地說,它們可以分為三類:
- 類似 GPT(也稱為自回歸Transformer 模型)
- 類別 BERT(也稱為自動編碼Transformer 模型)
- 類似 BART/T5(也稱為序列到序列Transformer 模型)
上述的所有 Transformer 模型(GPT、BERT、BART、T5 等)都已被訓練為語言模型。這意味著他們已經以自我監督的方式接受了大量原始文本的培訓。自監督學習是一種根據模型的輸入自動計算目標的訓練。這意味著不需要人類來標記數據!
一般常見的任務回到我們主題語言模型,這稱為因果語言建模,因為輸出取決於過去和現在的輸入,而不是未來的輸入。

另一個例子是MASK(遮罩)語言建模,其中模型預測句子中的遮罩詞。
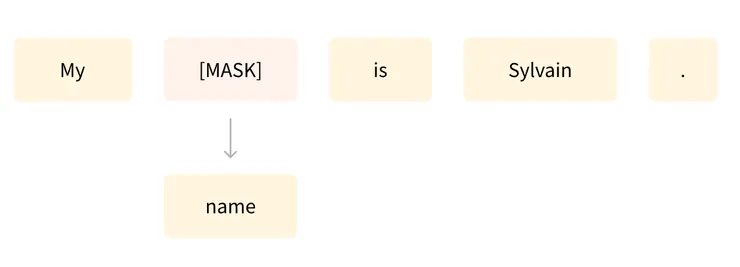
而我們實際上訓練這些模型時,需要龐大的資源,非一般人能及。所以我們會需要
做的經常是finetune模型來達到我們要的目的。微調是在模型預訓練後進行的訓練。要執行微調,您首先需要取得預先訓練的語言模型,然後使用特定於您的任務的資料集執行額外的訓練。微調模型的時間、數據、財務和環境成本較低。迭代不同的微調方案也更快、更容易,因為訓練比完整的預訓練限制更少。這個過程還將比從頭開始訓練獲得更好的結果(除非您有大量數據),這就是為什麼您應該始終嘗試利用預訓練模型(盡可能接近您的任務)並進行微調它。
Transformer模型主要由兩個區塊組成。
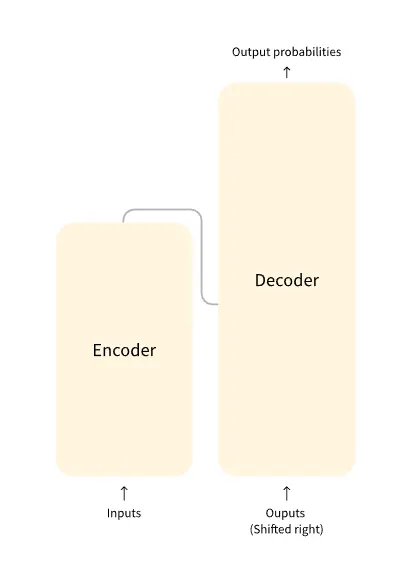
- 編碼器(左):編碼器接收輸入並建構其表示(其特徵)。這意味著模型經過優化以從輸入中獲取理解。
- 解碼器(右):解碼器使用編碼器的表示(特徵)以及其他輸入來產生目標序列。這意味著該模型針對生成輸出進行了最佳化。
因為要解決的問題不同,通常可以分類為:
- 僅編碼器模型:適用於需要理解輸入的任務,例如句子分類和命名實體識別。
- 僅解碼器模型:適用於文字產生等生成任務。
- 編碼器-解碼器模型或序列到序列模型:適用於需要輸入的生成任務,例如翻譯或摘要。
























