前言
因之前業務上的介接踩到json開頭有Bom表標記符號的坑,想到之前也有遇到檔案內ASCII/Unicode/UTF-8編碼間轉換的坑,因此決定要來搞清楚這些編碼的前世今生與編碼原理了。畢竟字符編碼就是電腦技術中傳遞訊息的基石
行前複習
電腦能辨認的只有資訊就是2進位位元,位元(bit): 0 / 1兩種狀態
位元組(byte) : 8位元(bit)
1 byte = 8 bit
各編碼的誕生
ASCII
全名是 American Standard Code for Information Interchange,譯成中文為美國資訊交換標準程式碼。當初的設計只用來滿足英語系國家因此只有用7位元(128種字元)來記錄每個字元的編碼,包含A-Z,a-z,0-9與一些保留字元與符號
白話文:美國為英語系國家編出一本收錄128字元的編碼字典
EASCII
如上述因ASCII編碼範圍只考慮到英語系國家導致沒有辦法滿足歐洲或拉丁語系國家使用的字元,因此再把ASCII擴編成8位元(256種字元)來擴充許多符號與希臘或拉丁符號使用
白話文:非英語系國家在ASCII的基礎上擴充屬於自己的語系字元(在128 => 255這段範圍中新增,因0-127一樣是繼承ASCII中的字元)
ASCII 的衍生問題
統一前的一Byte各表:
如上所介紹在非英語系國家中都會在編碼字典中(128 => 255這段範圍中新增自己語系字元)就會發生在法文語系中第150字元的符號在法文是某個字,在同一個第150字元的符號卻是希伯來文是另一個字,造成一Byte各表的狀況。
- 生活中的案例
email或是某個檔案的內容可能發送方跟接收方使用不同語系,因此在讀檔案時用錯誤的編碼方式轉換就會出現亂碼等等
Unicode
為了解決以上所述一Byte各表的問題,需要一部收錄全部語系字元的編碼表(16進位制紀錄的字典),讓每個字元所代表的位元組都是獨一無二的。
於是Unicode就誕生了(簡稱萬國碼/國際碼),一部收錄全世界各字元符號的編碼對照表(字典)
Unicode的衍生問題
統一後的一Byte各表:
由於Unicode只記錄每個字元所對照的16進位值,但因電腦只看得懂0和1,所以我們需要將Unicode轉換為0和1的二元碼才能在電腦上運行。
當時沒有建立一套標準來表達所對照出來的16進位值要用甚麼方式表達成2進位制,因此就出現了以下幾個問題
- 如何區別Unicode 和ASCII如果一個字元的16進位值轉成2進位制時是3個Byte,電腦怎麼知道這3個Byte的值是表達成一個字元 還是 3個1 Byte的字元?
- 避免資料儲存的資源浪費如果表達的Byte要用固定長度表示,
例:要固定用4Byte長度表示所以字元,但字母A只需要用1個Byte表示即可卻要多印左補3個Byte都是0來符合4個Byte長度的表示式這會造成儲存上的資源浪費
Unicode的轉換
Unicode定義了幾種轉換方式,也就是我們常聽到的Unicode Transformation Format(UTF)!
UTF-8
UTF-8是一個可變長度的編碼,使用1到4個位元組(Byte)來表達一個字元,並能與ASCII相容。因為它可以判斷要以多少位元組來表示字元,所以UTF-8成為全世界最廣泛被使用的編碼方式。
以下為UTF-8的表達規則
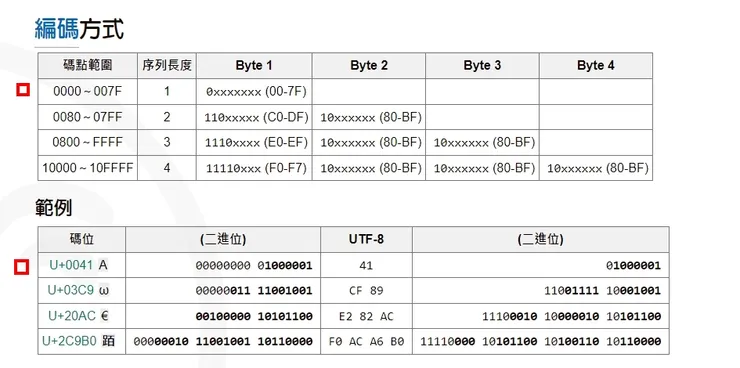
1. 對於單字節(只需1Byte表達)的符號,位元組的第一位設為0,後面7位元為這個符號的Unicode碼。
因此對於英文字母,UTF-8 編碼和ASCII 碼是相同的。
例:下圖中序列一的表示法(紅框部分),字母x表示可用編碼的位元
2. 對於n位元組的符號(n > 1),第一個位元組的前n位都設為1,第n + 1位元設為0,後面位元組的前兩位一律設為10。剩下x的位置,都是這個符號的Unicode碼可以填入的位置,填入的方向是從最後一個Byte位置開始由 右 => 左填入x,若還有x則 左補0填滿。
例:下圖中序列2-4的表示法(紅框部分),字母x表示可放入該編碼的位元位置
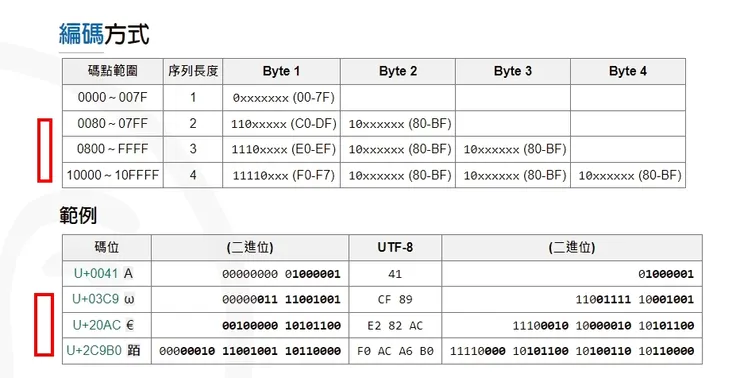
根據上面的範例來解讀就是:
1. 若第1個Byte開頭是0的話代表這個字元是1個Byte就可以表達的。
2. 若第1個Byte開頭是1的話就看有N個1就代表這個字元需要用N個Byte來表達
其他實作方式
包括UTF-16(字元以兩個位元組或四個位元組表示)和UTF-32(字元用四個位元組表示),在此就不多做介紹。
結語
以上是近期對轉碼相關歷史緣由的統整,如有遇到相同疑問的讀者希望這篇對你有幫助,共勉之
參考資料
2.3 電腦與人的溝通 - ASCII code, Unicode
























