如果將人類解決問題的步驟想像成一棵樹,每一個節點代表一個解決方案,讓 LLM 去選擇並探索節點直到找出合適的答案為止
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
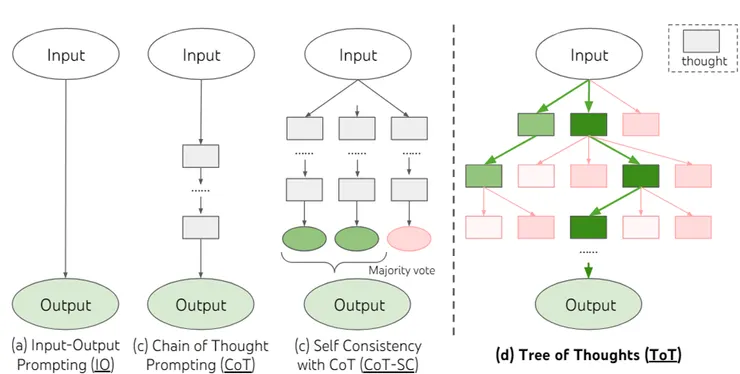
Prompts 回顧比較
每個矩形代表一個思想(連貫的語言序列),為解決問題的中間步驟。
- Input-Output(IO)
輸入問題 x 直接轉換為輸出 y
- Chain-of-thought(CoT)
為了解決輸入 x 與輸出 y 之間映射 non-trivial 的狀況,所以加入一系列想法(步驟 來進行橋接。
- Self-consistency with Cot(Cot - SC)
為了確保模型的輸出一致性,進行多次的採樣,然後將出現最多的做為最終的輸出 y (問答類型會有限制)。
Prompts 回顧
發展原由
解決問題的過程會涉及重複使用現有資訊來進行探索,直到最終找到解決問題的方法,將人類解決問題的步驟想像成一棵樹,每一個節點代表一個解決方案,而選用哪個分支則交由啟發式方法決定。
- 現行語言模型解決問題的缺點
- Locally:多半僅能探索由上而下的單一分支。
- Globally:無法考慮不同 Type (類型 / 型態)或是 lookahead(未來可能出現) or backtracking(已經發生過)的事件進行回顧和檢討。
- 使 LLM 有意識地解決問題
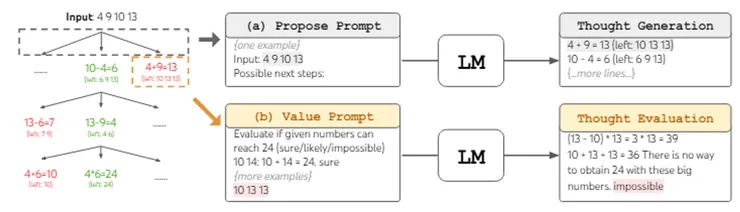
Thought decomposition(思想分解)
相比 CoT 不進行提示分解而直接採樣,ToT 利用問題屬性來分解中間的思想步驟。
- Thought generator(思想產生器)
- Value prompt:當思考空間豐富(每個想法都是一個段落)並且獨立同分佈時,樣本帶來多樣性。
- Propose thoughts:當思考空間受限制(每個想法只是一個單字或一行)時,這種方法效果會更好,因此在同一上下文中提出不同的想法可以避免重複。
- State evaluator(狀態評估器)
搜尋演算法的啟發式方法來確定要繼續探索哪些狀態以及按什麼順序進行,使用 LLM 來有意的推理 ( deliberately reason ) 啟發式方法可以比程式規則更靈活,且比學習模型更有效。
- Value each state independently:使用前瞻(lookahead)模擬來快速檢查(5 + 5 + 14 = 24),並生成轉換後的分類(肯定 / 可能 / 不可能)。
- Vote across states:當問題很難直接評估時,比較不同的部分並投票選出最有希望的解決方案。將「探索哪個狀態」作為多選 QA,並使用 LM 樣本對其進行投票。
Thought decomposition (思想分解)




















