先前文章介紹完GPU算力估算(如何評估GPU能提供多少AI算力?)與AI應用類型(幾種常見的AI應用類型),本文接著分享如何估算AI訓練所需算力。

算力需求估算公式
最常用來估算AI模型所需訓練算力的基本公式:訓練 FLOPs ≈ 6 × N × D
- N = 模型參數數(parameter count)。
- D = 訓練的 token 數。
- FLOPs = 結果是需要多少「浮點運算」(FLOPs)。
e.g., 訓練一個 100B 模型、用 500B tokens → 約需要 3e24 FLOPs。
訓練FLOPs估算值「6」
訓練 FLOPs 估算為什麼用6?6是基於 Transformer 架構計算成本的「經驗係數」,代表平均每個參數參與一個 token 訓練所需的運算次數,這個值會隨模型架構在5~7之間略變,但 6 是合理且保守的抓法,是共通採用的簡化估算係數。
為什麼要簡化公式?因為實際 FLOPs 要考慮眾多因素,像是層數、MLP隱藏維度、Activation function計算量、Embedding / Norm / Residual 等結構、Forward / Backward 計算次數、Hidden size、Batch size & Pipeline優化等等。
透過一個萬用的簡化公式,快速估出FLOPs來衡量訓練成本、訓練時間、比較不同規模的數據集/AI模型所需要的算力需求。
有了基本公式,就能探討不同AI應用模型的算力需求。
參數parameter
模型參數數量(通常用 M 或 B 表示)是指這個 AI 模型「有多少可以學習的知識容量」,可以把它想成模型的「腦容量」或「記憶體」。
當我們提供訓練資料(tokens)給模型學習時,模型會根據這些資料去調整每一個參數的值,進而學會判斷、預測或生成文字的能力。
與常數6相同,模型參數數量也有經驗法則:
理想情況下:Token 數 ≈ 參數數的 20~30 倍。
因此,假如公式中,Token數量已知,就能根據上述法則推估參數數量。反過來說,要是只知道參數,同理能推出Token數。
為什麼要這樣配比?如果模型太大、資料太少→容易過度擬合(overfit);如果模型太小、資料太多 → 學不出東西(underfit)。理論上模型參數 ≈ token 數的 1/20 到 1/30 是訓練效果的甜蜜點。
自己在實務使用,會採以「保守原則」,估算參數會抓20倍下去當分母,讓參數大一點,讓訓練FLOPs數值較大,在保守原則下得出訓練時間,基本上就是評估最差狀況。
等到具體實施時,較容易出現「倒吃甘蔗」的情形,也比較不會遭到業主的挑戰與質疑。
文字AI訓練FLOPs
為方便理解,就以簡單的文字文件估算所需算力FLOPs,像是MS Office辦公室軟體與pdf檔案。
Token 數如何得知?一個英文單字,簡單估算法可以用音節方式計算,一個音節 ≈ 0.5個Token,一個中文字1個Token。
接著看是要用一頁大約多少單字、共幾頁、共幾份檔案,抑或是以檔案大小回推頁數,都能得出總Token數。
如果對於檔案大小沒有概念的話,可以參考維基百科純文字檔共110GB(副檔名為.Zim),基本上一般企業應該很難超越維基百科。如果是圖文並茂版本,把整個維基百科打包則落在25TB左右。(延伸閱讀:Mirroring Wikimedia project XML dumps)
得出Token總數,就能得出參數總數,進而得出訓練FLOPs,最後除以GPU供應之算力FLOPs,就能得出訓練時間。
圖像算力需求
公式與文字不一樣,圖像涉及輸入圖像大小、訓練圖像數量、Batch Size、訓練 Epoch 數:
訓練總 FLOPs≈單張圖像FLOPs×3×總圖像數×訓練輪數 (epoch)。
關鍵在於「圖像本身」,模型結構與圖像輸入大小有關,高解析度圖像非常吃資源(如 2480×2480),通常會resize或patch-based模型訓練策略,因此公式就會變成:
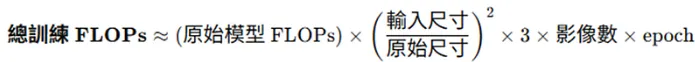
圖像從預處理開始就需要用到算力,如上述resize、patch-based模型就是預處理的一環。由於每張圖像都需要經歷預處理的環節,公式上才會以「單張圖像FLOPs」作為開頭。
至於為什麼要乘以3?因為訓練中:
- 前向傳播 FLOPs = 1 倍;
- 反向傳播 FLOPs ≈ 2 倍;
- 總共 ≈ 3 倍前向 FLOPs。
訓練 Epoch 數則意味著全部資料會根據Batch Size隨機抽樣訓練幾次。
當關鍵的單圖FLOPs算出來,後續不論是假設圖片總數還是圖檔總容量,總訓練FLOPs自然迎刃而解。
音訊算力需求
語音模型實際輸入的是音訊,而非文字,token對應是音訊 frame的 embedding token,平均每秒大約50–75 token(視音訊特徵處理方式而定)。
音訊的訓練實際上需要考量時長、語言、音訊取樣率Sampling rate、音檔格式,根據不同音訊輸入來源以及終端AI應用,有不同的預處理與模型架構影響訓練FLOPs。
不過我們可以透過取得關鍵數據「每秒Token數」,並透過通用公式:
訓練 FLOPs ≈ 6 × N × D
根據訓練的音檔時長或檔案大小,得出總Token術後,接著回推參數總數,進而得出訓練FLOPs,最後除以GPU供應之算力FLOPs,得出訓練時間。
影像算力需求
影像需要考量檔案大小、時長、解析度、格式、幀率(FPS)、影像數量等等。
影像要用來做AI訓練,計算方式跟圖像相似,將每秒影像變成圖片後做訓練。假設每秒處理幀數 (FPS)為30,那麼一秒鐘就有30張圖像,後續就接著比照「單張圖像FLOPs」做處理。
只是影像根據需求,需要應用不同的AI模型,才能達到動態追蹤,因此在單張圖像FLOPs的計算上,需要把不同AI模型的應用納入:
每秒所需FLOPs=張數 × 模型結構 × 圖片大小
以人流分析影像為例,我們可以簡單切出需要AI模型的幾個區塊:影像預處理、特徵分析、物件偵測、密度估計、目標追蹤。
根據上述五大區塊,就是我們從輸入影像後,需要透過上述五大AI模型區塊進行訓練,上述五項有各自的AI模型,組合起來就是所謂的模型結構,最終得到「人流分析影像」的AI應用。
將模型結構所需每秒FLOPs得出,再根據總訓練資料集的總時長或影像檔案大小納入計算,得出訓練FLOPs,後續照本宣科與GPU算力相除,就能得出訓練時間。
CAD工程圖算力需求
更複雜尚未碰到,目前難度最高的就停留在工程圖CAD上。CAD不是純文字、也不是純圖片,而是結構化的技術資料格式,屬於矢量圖。
要將CAD檔案餵給AI模型做訓練,需要考量CAD內容的結構化資料,以及採用的AI模型結構而定。
單一張CAD所需要的算力多寡,根據CAD圖的解析度、物件數量、尺寸、圖層數量等資訊決定。一張 300MB~2GB 的 CAD 檔轉成圖片時,可能會是超大解析度圖(如 8000×8000 px),會非常佔Token。
假設訓練一個 AI 模型來從結構化 CAD (.dwg) 檔案中偵測接點並自動連線,可以拆分成CAD預處理、CAD 結構解析、接點偵測、點與點之間的路徑預測四大區塊,根據上述四項採用相對應的AI模型。
CAD圖檔最後以圖面形式餵進AI模型結構中做訓練,因此就能回到「單張圖像FLOPs」,然後將訓練用CAD檔案數量或檔案大小帶出來,就能得到所需算力,最後除以GPU算力就能得到訓練時間。
總結:以終為始,慢慢推算FLOPs
計算AI所需算力需求的重點在於「以終為始」。最終輸出的「使用目的」,決定起始輸入的「資料類型」,過程中需要搭建哪些「AI模型結構」,決定了需要多少算力FLOPs。
正因為終端應用族繁不及備載,難一言以蔽之,只能用通則與簡單的範例說明,希望讀者多少能看懂筆者想表達的意思。
至於複數不同AI混合應用的算力估算,自己在實務上先是拆解不同類型,各自試算完FLOPs後簡單加總。不確定這樣估算是否正確,有待專家指教。
最重要的,在計算完算力供需後,自己是會採「保守原則」估算:算力需求取最大值,算力供應取最小值。倘若試算的訓練時數業主能接受的話,後續實際出來的成效只要不比預期差,基本上就不會受太多質疑與挑戰。
當然,自己非本科出生,對於AI也只是剛入門,關於本篇計算AI算力FLOPs的概念框架,若有敘述不周或內容錯誤,還請各路高人補充與指正。







