- 簡介
本文詳細評比了四個AI圖像模型:DALL·E 3、Google Imagen2、Stable Diffusion與Midjourney。透過比較這些平台在十個不同領域的影像生成效能,文章揭示了各平台的優缺點。結合對每個類別的深入分析,本文為讀者提供了選擇最適合其需求的平台的關鍵資訊。評估基於OpenGPT.com上OpenDraw服務,採用了DALL·E 3、Google Imagen2、Stable Diffusion以及Dreambooth V4 (即Midjourney)的預設配置進行。

- AI圖像模型介紹
DALL-E 3是 OpenAI 最先進的文字轉圖像模型。該模型根據稱為Prompt的自然語言輸入生成圖像。
Google Imagen2是由 Google 開發的 AI 文字轉圖像擴散模型,其特點是高質量、逼真的輸出和與您的提示更強的一致性。
Stable Diffusion是一款先進的生成式人工智能(generative AI)模型,旨在基於文本和圖像提示的輸入創建獨特的逼真圖像。
Midjourney是由獨立研究實驗室 Midjourney, Inc. 開發和運營的生成式人工智能程序和服務。
- 分類評估AI圖像模型
在評估AI圖像模型時,選擇不同的類別生成圖像,來測試其性能的綜合能力非常重要。不同的類別可以揭示細節渲染、色彩處理、主題理解和藝術詮釋的優點和缺點。同時,類別的選擇必須足夠廣泛,以突破這些工具的界限,確保評估的全面性。
基於以上描述,此次評估選擇了10 個類別:
人物肖像(Human Portraits):人物肖像可以評估AI渲染真實人物特徵和表情的能力。這是對AI在人體構造和肖像細節的基本測試和評估。
動物(Animals):動物具有複雜的紋理和形態,可以評估AI在不同生態系統中準確表現皮毛、鱗片和運動的能力。
水果(Fruits):水果具有不同的形狀、紋理和顏色,可以評估AI捕捉複雜的細節和光線透過物體的半透明渲染能力。
景觀(Landscapes):景觀可以評估AI對視角、自然光,以及眾多元素混合的處理能力。
水下場景(Underwater Scenes):評估AI 处理复杂环境的能力包括對於光线相互作用、水的流动性以及水下场景中生命形态的多样性的處理能力,。
城市景觀(Urban Scenes and Cityscapes):評估AI處理直線、幾何形狀和人工照明等場景的能力。
車輛:車輛尤其是運動中的車輛,有助於評估AI對動態照明、反射以及驅動車輛速度和動感的機械細節的處理能力。
歷史時刻:再現歷史時刻可以評估AI對上下文的理解能力,以及處理特定歷史時期的細節和文理的能力。
科技與設備:未來科技可以評估通過AI對未來的設想,進行產品和用戶交互設計的能力。
抽象概念:抽象圖像可以評估AI的創造力及其超越字面意義的能力,以及對情感或想法的想像能力。
- 深入評估AI模型在多個類別中生成的圖像
本人將分析AI模型在不同類別中生成的圖像,用來分析每個平台的優勢和細微差別。
(由於篇幅有限,本文將只截取人物肖像(Human Portraits)的分析,其他類別請進入原文查看:https://blog.opengpt.com/2024/02/04/comparative-analysis-of-ai-image-generation-models-dall%c2%b7e-3-google-imagen2-stable-diffusion-and-midjourney)
1. 人物肖像(Human Portraits)
[Prompt] A digital portrait of a young girl with freckles, holding a daisy, her hair gently blowing in the breeze, against a soft, pastel-colored background.
使用DALL-E 3、Google Imagen2、Stable Diffusion和Midjourney等AI模型產生人像肖像,可以評估這些模型在模仿人類表情,情緒複雜性和微妙性的能力。另外我們與生俱來對人臉的熟悉度。該任務評估了AI複製肖像的複雜細節、紋理和文化降低差異的能力。此外,該任務也評估了AI的倫理和偏好。產生人像肖像可以對AI技術精確度、文化敏感度、數位創造力和倫理等進行多方面評估。
生成的圖像如下所示(請滑動瀏覽所有四幅圖像):

DALL.E 3
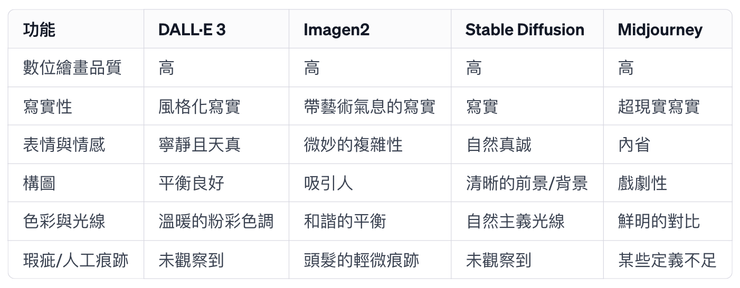
數位繪畫品質:高。該圖像展示了一種精緻且平滑的繪畫風格。
寫實性:這幅肖像具有風格化的寫實感,特別注重細節,尤其是雀斑和眼睛。
表情與情感:表情寧靜且吸引人,帶有一種天真的感覺。
構圖:平衡良好,空間和背景元素的使用恰到好處,不會分散對主題的注意。
色彩與光線:使用柔和的粉彩色調提供了一種溫暖、邀請的氛圍。
瑕疵/人工痕跡:沒有明顯的瑕疵。

Google Imagen2
數位繪畫品質:高。同時展示了高水平的細節和平滑的數位繪畫風格。
寫實性:這幅肖像傾向於寫實,並帶有藝術氣息,特別是在頭髮和皮膚質感上。
表情與情感:目光直接,表情有微妙的複雜性。
構圖:構圖吸引,人物在畫面中的位置得宜。
色彩與光線:色彩搭配和諧,溫暖與涼爽之間的平衡做得很好。
瑕疵/人工痕跡:頭髮周圍有些微的人工痕跡,但不過分分散注意力。

Stable Diffusion
數位繪畫品質:品質令人印象深刻,明顯專注於紋理和細節。
寫實性:這幅肖像提供了一個逼真的表現,頭髮和雀斑的細節非常生動。
表情與情感:表情自然真誠,捕捉到了一瞬間的寧靜。
構圖:良好的構圖,前景和背景有清晰的區分。色彩與光線:光線自然,很好的突顯了人物的特徵。
瑕疵/人工痕跡:沒有明顯的人工痕跡,顯示出一幅非常自然的數位繪畫。

Midjourney
數位繪畫品質:圖像品質高,具有獨特的藝術風格,看似繪畫與攝影的結合。
寫實性:這裡的寫實性帶有一種超現實感,特別是頭髮流動的誇張表現。
表情與情感:表情稍微內斂和反思。
構圖:構圖戲劇性,以花朵和頭髮圍繞主體。
色彩與光線:色彩使用鮮明,對比強烈,吸引了對主體的注意。
瑕疵/人工痕跡:像是頭髮中纏繞的花朵等一些區域略顯定義不清。
以下是相關比較的概覽表格
在人像肖像方面,不同的AI图像模型提供了多樣化選擇以滿足使用者需求和偏好。 DALL·E 3以其強大風格化能力和對細節的豐富捕捉而被強烈推薦,非常適合那些尋求創造性和獨特風格化肖像的用戶。 Google Imagen2則推薦給那些想在寫實主義和藝術風格之間找到平衡的用戶,提供了一種既真實又帶有藝術感的圖像創作方式。 Midjourney專注於提供戲劇性和超現實的肖像,適合追求獨特視覺效果和創意表達的創作者。而Stable Diffusion因其在寫實和自然真實表現上的強烈推薦,為那些尋求高度真實感和細節表現的用戶提供了理想選擇。這些建議是基於各平台的技術特點和擅長的風格領域,使用者可以根據自己的創作目的和風格偏好選擇最合適的工具,從而在人像肖像創作上實現更精準和個性化的表達。
下表展示了不同AI圖像模型在人像肖像推薦方面的特點:

這個表格概括了每個平台在人像肖像創作方面的優勢和推薦用途,幫助使用者根據自己的需求和偏好選擇合適的平台。
其他九個類別的圖像和分析請參見原文:https://blog.opengpt.com/2024/02/04/comparative-analysis-of-ai-image-generation-models-dall%c2%b7e-3-google-imagen2-stable-diffusion-and-midjourney/
- 整體分析與比較
每個平台都在特定領域顯示了其獨特的優勢。 DALL.E 3擅長打造觸動人心的圖像,展現了其獨特的藝術魅力;Google Imagen2則以其細膩的清晰度和逼真度印證了技術精粹;Midjourney成為創作風格化及充滿氛圍的藝術作品的首選,展現了其對風格的精準把握;而Stable Diffusion則在現實與想像之間找到了完美的平衡點。本文綜合分析比較了這四種AI模型,在考慮它們在各個類別中的整體表現的同時,也著重了它們的主要優勢與差異。

通過這次分析可以看到这些AI模型各有優劣,並沒有哪一個佔據絕對領先地位。每个AI模型都具有自己擅長的创造视野和风格,例如DALL.E 3富有灵魂和想象力的触感、Google Imagen2无与伦比的精确性和现实主义、Midjourney的叙事和解释风格,以及Stable Diffusion中的现实主义与创造力的和谐融合。對AI模型的选择最终取决于設定的艺术目标,創造者可以根據自己的需求选择最匹配的AI模型工具。
免責聲明
本文所展示的視覺內容均由DALL.E 3、Google Imagen2、Stable Diffusion和Midjourney等人工智慧平台生成,並透過OpenGPT.com上的OpenDraw提供。所有影像均按照各平台的預設設定生成,未經任何後製或人工編輯,以確保評估的公正性和客觀性。
文章中的見解和評估僅基於上述AI工具所產生的視覺成果。這些評估可能未能全面反映每個平台的全部功能或其設計初衷。讀者應當了解,AI生成藝術的本質具有高度的不確定性,不同的內容生成實例可能會產生差異化的結果。
藝術及其賞析本質上具有主觀性,一個AI平台的特定優勢可能更符合某些人的偏好或特定項目的需求。因此,儘管本文所進行的比較分析相當詳盡,但並非全面,也不能被視為最終裁決。
隨著科技的發展和個人偏好及專案需求的變化,這些因素共同決定了選擇哪個藝術創作平台更加合適。我們鼓勵讀者進行個人嘗試和研究,以便對這些高級AI藝術生成工具的有效性和適宜性做出明智的選擇,從而更好地服務於他們獨特的創作需求。





















