近日(2024/2月中) OpenAI 的 SORA引起大家廣泛的討論與注意,其底層架構來自於DiT (Diffusion Transformer),但其實這個領域的競爭對手還不少,這次要介紹的這篇,使用Mask-LM的生成方式,可以達到最頂尖的FID/FVD分數,兼顧生成品質與生成速度,讓我們一起來看看Google與卡內基美濃大學Yu同學 (原中國北京大學高材生)團隊針對影片生成領域提出了那些SoTA見解。
生成影片技術的本質就是一種資料壓縮,把影片中的每時每刻,每張瞬間的圖片,經由模型映射成如同文字那樣的Token向量,之後就能用LM語言模型相關的技術,把類似的影片藉由Token的組合,經過反向生成 or Decode出來。神經網路能夠用很廉價的方式抽取黑格爾小邏輯裡面所提到的本質,這本質往往具有空間不變性,時間不變性,概念不變性,可以在不同的觸發條件下,像積木一樣,重新做各種排列組合以組成萬物。讓我們抱著期待的心情,看看MAGVIT架構能為我們帶來哪些驚喜應用潛能與突破。

把影片的片段映射成一維向量的Tokens,後續可以用類似生成文字查字典的方式來生成影像片段。
MAGVIT令人震驚的突破:
許多人很納悶,為何傳統編解碼生成方式會不敵擴散迭代模型,MAGVIT用一系列架構設計,與後續的改良,得到能夠打敗所有擴散模型的生成結果,證明了先前的Tokenizer的Encoder Model理解影像的程度不到位,導致生成結果無法與擴散模型匹敵,於是,論文作者設計了獨特的Mask-LM流程,在改善生成結果的同時,還能多用途使用。
如下圖所示,可以做Frame Prediction (FP),Frame Interpolation (FI,生成動畫或是遊戲補幀);Central Outpainting (OPC) / Vertical Outpainting (OPV), Horizontal Outpainting (OPH), Dynamic Outpainting (OPD)可以用於相機防手震,影片後製;Central Inpainting (IPC), Dynamic In painting (IPD) 可以用於影片後製;Class-conditional Generation (CG), Class conditional Frame Prediction (CFP),可以根據分鏡圖/文字Prompt來生成各種新的動畫。
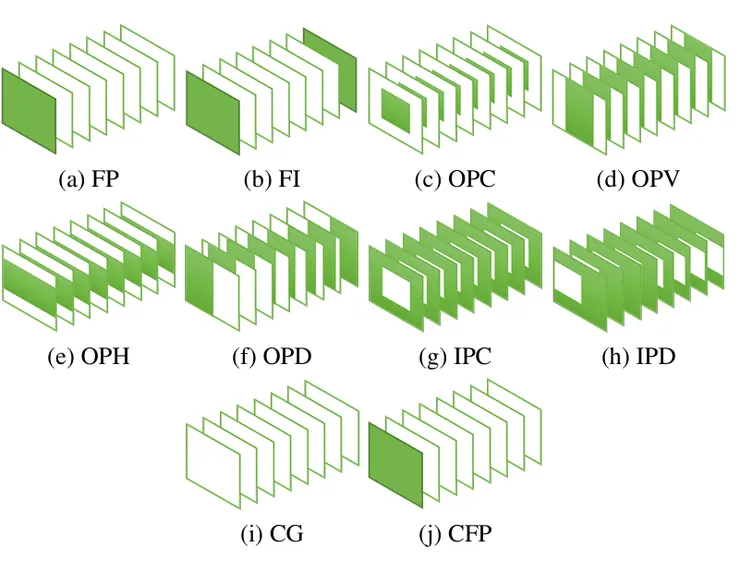
有了這些工具,一個影片工作者就能搞定原本需要一整個特效/動畫團隊才能做的事情,只要能好好的Leverage這些工具,要成立一人影業/電影/動畫公司,不再是遙不可及的夢想
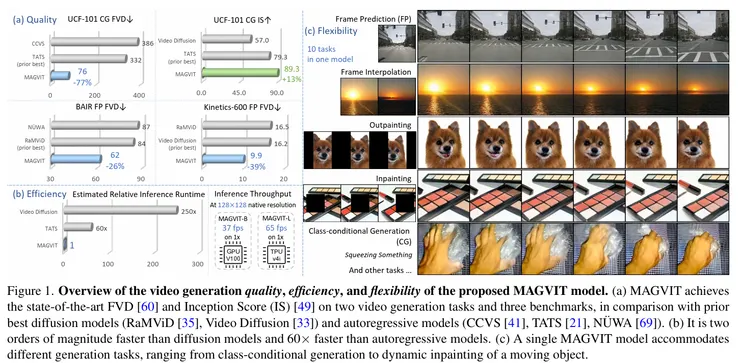
MAGVIT一推出便驚艷世人,兼具多種生成模式彈性與達成極高的生成效率,火爆整個AI生成圈。
MASK-LM首先會產生一組固定的MASK框架,根據想要生成的任務(初始條件)把輸入影像填入,然後經由COMMIT Masking的步驟,一步一步將原本遮罩中的影像逐漸生成,經過多次迭代,便能完成上述所有應用目標的作業。訓練的時候,會有Scheduler來逐漸放開Mask,這種過程會被Model利用Lmask (Objective loss)學起來,這樣一來在Inference的時候就能夠自動逐步地把影像生成出來,這種手法值得我們的學習。
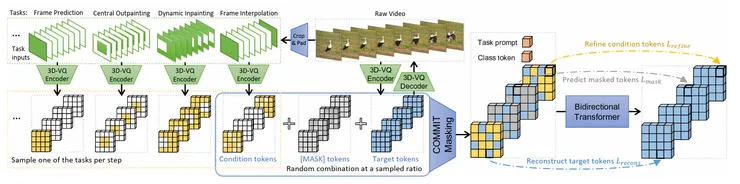
生成影像需要套用COnditional Masked Modeling by Interior Tokens (COMIT)演算法,如下所示,先針對輸入進行編碼產生z(Latent),根據S/S*的先驗決定Mask要被替換成Conditional Token / 維持Mask / 維持Tatget Token (輸出結果),要得到輸出結果,除了原有已經有的輸入Token以外,都要經過MASK -> Condictional Token -> Target Token的過程。temperature T參數在演算法裡面巧妙的控制Condictional Token的迭代次數,Temperature越高,能夠激發模型的創造能力,因為它會基於較多的假設來生成影像結果,總體來看,算法設計得十分巧妙。

COMMIT 算法 Pseudo-code 部分
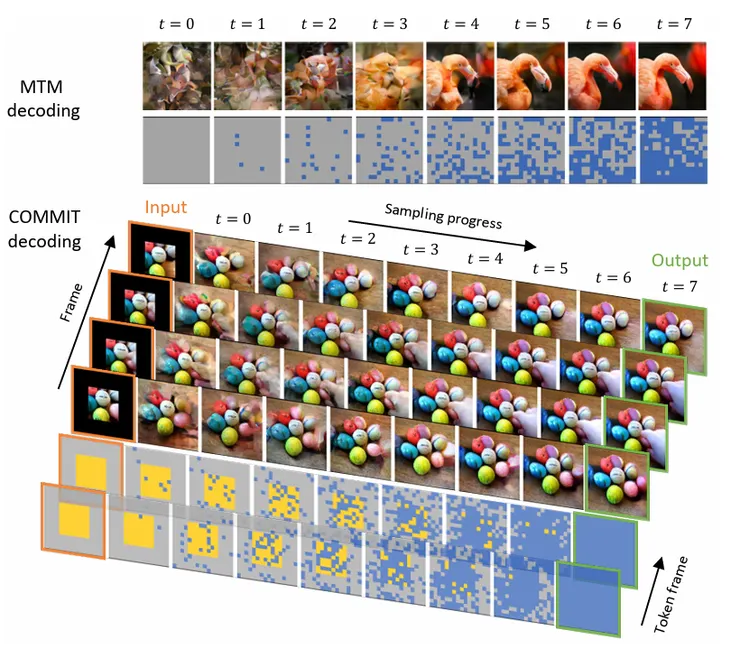
COMMIT 與傳統生成圖片 MTM生成方式比較
如下圖所示,這種生成Token的方式相對於完全的Auto-regression (AR-LM)方式,比較適合用在生成影片/圖片上面,圖片比文字多了一個維度,無論照哪一種Scan的方式逐步生成,都會導致大量的Auto-Regression損失,反之,藉由學習Mask解開與生成的方式,可以讓相對比較可信的Token先浮出檯面,然後讓其他區塊參考。重點是這整個生成過程,有經過Lmask和Lrefine & Lrecons 損失函數,共同發揮,進行調整過,整體影片生成的準確度註定會比AR-LM方式還要來得高。
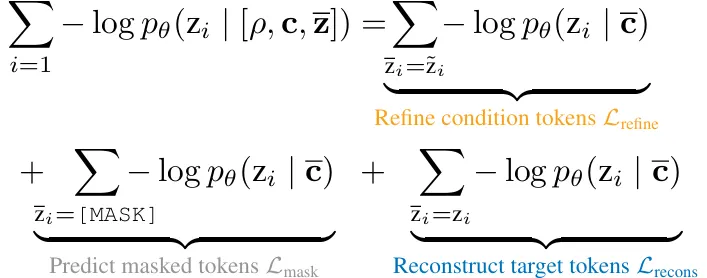
ImageNet 的 Pretrain,後續主要訓練針對三個Loss同時進行收斂,確保能夠學會如何解Mask推測逐步生成。
MAGVIT-V2改良部分:
- LFQ
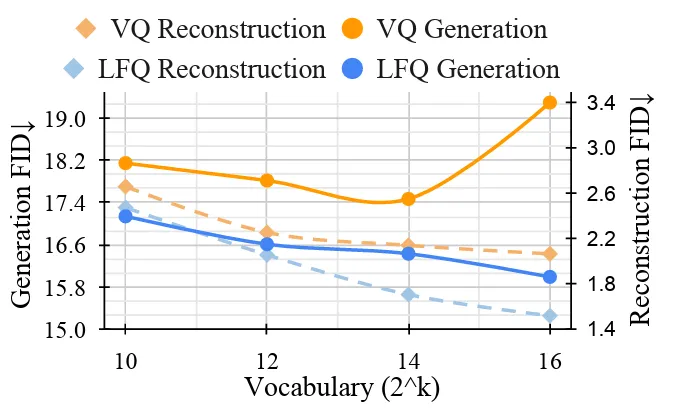
神奇的無查找量化(Look-up Free Quantization)方法,傳統的VQGAN增加詞彙量以後生成結果反而變差,本篇作者把這些詞彙從d維(d > 0) 降到0維,化成一個整數集合,利用公式的方式來產生Output Quantized Token的每一個維度,驚奇的發現這樣可以獲得大量增加詞彙量的好處,而且還無須查找(大範圍從中找出最貼近的詞彙)。而Token的量化表達也有助於減少Token容量,表達更加泛化,也能和普通文字Token (也是離散),混在一起使用,完成各種多模態應用在Token表達的大一統。
- Causal-3D CNN
作者用UCF101資料集訓練,實驗各種架構,發現Causal-3D CNN架構表現突出,Transformer對於不同3D Video Tokens之間的關係理解能力,沒有想像中得好。
- Change Downsamplers from average pooling into strided convolutions to leverage learned kernels
Down Sampling通常會先使用average or max pooling,來試驗效果(因為計算量 小),然後嘗試用strided convolutions,看看效果能否有提升。
























