長短期記憶(英語:Long Short-Term Memory,LSTM)是一種時間循環神經網路(RNN),論文首次發表於1997年。
LSTM(長短期記憶)是一種特定類型的遞歸神經網絡(RNN),在許多需要處理時間序列數據或順序數據的應用中非常有用。
以下是一些常見的 LSTM 應用:
- 語音識別:LSTM 可以用於將語音信號轉換為文本。例如,語音助手和語音轉文字服務都使用 LSTM 網絡來處理語音數據。
- 語言建模和文本生成:LSTM 可以預測文本序列中的下一個單詞或字符,用於自動生成文本,如編寫文章、生成對話和寫詩等。
- 機器翻譯:LSTM 在翻譯系統中廣泛使用,例如 Google 翻譯,它能夠將一種語言的句子翻譯成另一種語言。
- 情感分析:LSTM 用於從文本中檢測情感,如分析社交媒體帖子、評論和客戶反饋中的情感。
- 時間序列預測:LSTM 可以用於預測時間序列數據中的未來值,例如股票價格、天氣預測和銷售數據預測。
- 醫療診斷:LSTM 用於分析患者的醫療數據,以檢測和預測疾病的發展。
- 音樂生成:LSTM 可以學習音樂的結構並生成新音樂,例如自動作曲。
- 手寫識別:LSTM 用於識別手寫文字,例如手寫數據的數字化輸入。
典型的長短期記憶(LSTM)單元模型

LSTM Cell 的結構和運作
LSTM Cell 主要由三個門(gate)組成:遺忘門(Forget Gate),輸入門(Input Gate)和輸出門(Output Gate)。這些門控制信息在記憶細胞中的流動。以下是每個門的詳細說明:- 遺忘門(Forget Gate):
- 計算公式:
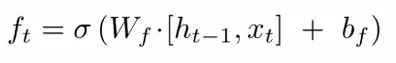
- 功能:決定需要忘記多少先前的記憶。通過 sigmoid 函數 σ,輸出一個0到1之間的數值,0表示完全忘記,1表示完全保留。
- 輸入門(Input Gate):
- 計算公式:
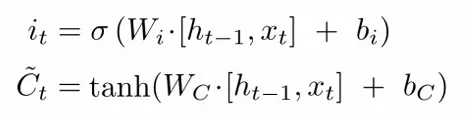
- 功能:決定將多少新的信息存入記憶細胞。輸入門的 sigmoid 函數輸出 iti_tit,以及候選記憶細胞的 tanh 函數輸出 ~Ct。
- 輸出門(Output Gate):
- 計算公式:
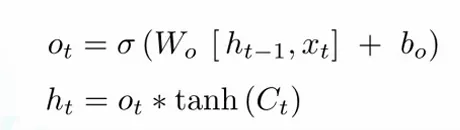
- 功能:決定從記憶細胞輸出多少信息作為當前的隱藏狀態 ht。通過 sigmoid 函數計算 Ot,再經過 tanh 函數處理當前的記憶細胞狀態 Ct。
LSTM Cell 運作步驟
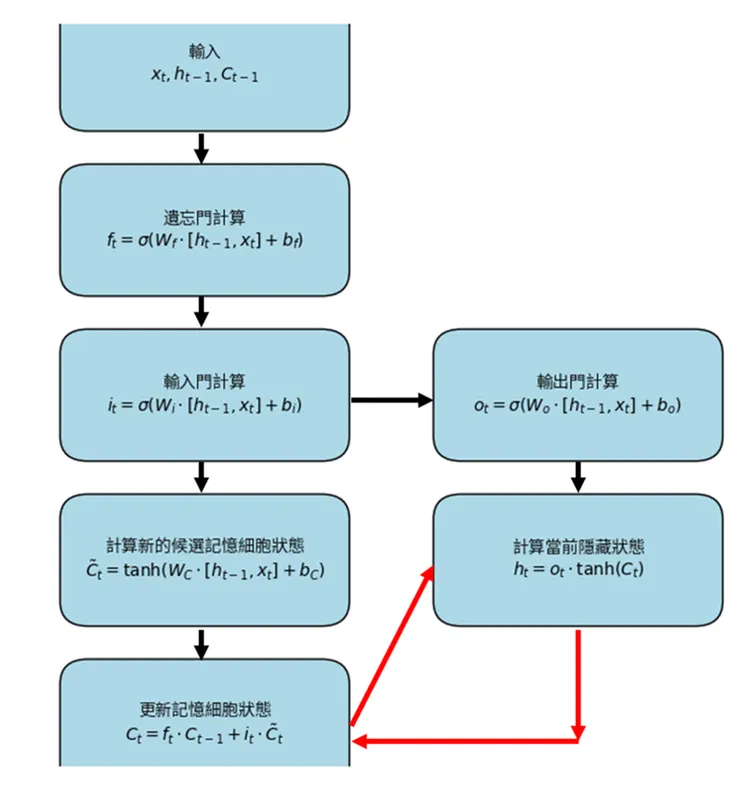
紅色箭頭主要表達了記憶細胞狀態和隱藏狀態之間的交互過程,展示了記憶細胞狀態 Ct 如何被計算並進一步影響隱藏狀態 ht。這些步驟是LSTM Cell核心的記憶和輸出機制。
LSTM Cell 的優勢
LSTM Cell 的設計使其能夠有效地處理長期依賴問題,記住長時間跨度內的信息,同時在每一時間步中根據需要添加或刪除信息。這使得 LSTM 在處理時間序列數據和自然語言處理任務(如語音識別、語言翻譯等)中非常有用。
總結來說,圖片中展示的模型是一個 LSTM Cell,主要由遺忘門、輸入門和輸出門組成,這些門共同作用,控制信息在記憶細胞中的流動和更新。


















