去年ChatGPT的發布,帶動了大型語言模型(Large Language Models, LLM)的風潮,這幾周更是進入了白熱化階段,除了有科技巨頭發布的GPT-4V、Gemini、Claude和Grok,開源模型更是百花齊放,包括了Llama 2、Mixtral 8x7B、Phi-2等等。所以今天我列了幾個我看過的經典LLM論文,這邊我會以時間順序列出,並概述每一篇的特點,那廢話不多說我們就開始吧!
1. Transformer
- 論文名稱:Attention is all you need
- 發布時間:2017/06/12
- 發布單位:Google、多倫多大學
- 簡單摘要:所有LLM的始祖,邁向NLP新時代的基礎架構
- 閱讀重點:self-attetion、positional encoding、per-layer complexity、sequential operations
- 中文摘要:傳統的序列轉換模型使用複雜的循環或卷積神經網絡,包括編碼器和解碼器。表現最好的模型會透過注意力機制連接編碼器和解碼器。而我們提出了一種新的簡單網絡結構,Transformer,完全基於注意力機制,不再使用循環和卷積。我們在兩個機器翻譯任務上進行實驗,發現這些模型在品質上的表現優越,並且更容易進行平行運算,訓練所需時間明顯減少。我們的模型在WMT 2014年英德翻譯任務上達到了28.4 BLEU,比現有最佳結果(包括整體模型)提高了超過2 BLEU。在WMT 2014年英法翻譯任務中,我們的模型在八個GPU上訓練3.5天後,取得了新的單模型最佳BLEU分數41.8,訓練成本僅為文獻中最佳模型的一小部分。我們展示了無論是在大量或有限的訓練數據下,Transformer在其他任務中的泛化能力,成功應用於英語組成句分析。
- 論文連結:https://arxiv.org/pdf/1706.03762.pdf
2. GPT-1
- 論文名稱:Improving language understanding by generative pre-training
- 發布時間:2018/06/11
- 發布單位:OpenAI
- 簡單摘要:autoregreesive Transformer始祖
- 閱讀重點:multi-layer Transformer decoder、autoregressive model
- 中文摘要:自然語言理解涵蓋眾多不同的任務,如文本蘊涵、問答、語義相似度評估和文件分類。儘管有豐富的未標記文本資料,但用於這些特定任務的標記數據稀缺,使得訓練有判別式的模型難以表現良好。我們證明通過對未標記文本的語言模型進行生成式預訓練,再對每個特定任務進行判別式微調,可以在這些任務上取得巨大進步。與以往方法不同,我們在微調期間利用任務感知的輸入轉換,實現有效的轉移,同時最大限度地減少對模型架構的更改。我們展示了我們方法在自然語言理解的眾多基準測試上的有效性。我們通用的任務無關模型在12個研究的任務中,有9個顯著優於專門為每個任務設計的判別式訓練模型表現。例如,在常識推理(Stories Cloze Test)上,我們實現了8.9%的改善,在問答(RACE)上為5.7%,在文本蘊涵(MultiNLI)上為1.5%。
- 論文連結:https://cdn.openai.com/research-covers/language-unsupervised/language_understanding_paper.pdf
3. Model Card
- 論文名稱:Model Cards for Model Reporting
- 發布時間:2018/10/05
- 發布單位:Google、多倫多大學
- 簡單摘要:要發布模型時,我該寫什麼東西。
- 閱讀重點:Model Card的範例。
- 中文摘要:機器學習模型被廣泛應用於執行各種重要任務,如法律、醫療、教育和就業等領域。為了展示機器學習模型的預期使用情境,並減少其在不適合的情況下使用,我們建議釋出的模型應附上描述其性能特性的文件。在這篇論文中,我們提出了一個框架,稱為「模型卡」,以促進透明的模型報告。模型卡是附加在已訓練好機器學習模型的簡短文件,提供了在各種條件下的基準評估,比如跨不同文化、人口統計或表型群體和交叉群體的評估結果。模型卡還會公開模型預期使用的情境、性能評估程序的詳細訊息。雖然我們主要關注的機器學習模型,應用於電腦視覺和自然語言處理領域,但這個框架可以用於記錄任何已訓練的機器學習模型。為了確立這一概念,我們為兩個監督式模型提供了模型卡範例:一個是用於在圖像中檢測微笑表情的模型,另一個是用於檢測文字中有害評論的模型。我們提議模型卡是向負責任機器學習和相關人工智慧技術的民主化邁出一步,增加了對人工智慧技術表現的透明度。我們希望這項工作能鼓勵釋出訓練好的機器學習模型的人們,附上類似詳細的評估數字和其他相關文件。
- 論文連結:https://arxiv.org/pdf/1810.03993.pdf
4. BERT
- 論文名稱:BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
- 發布時間:2018/10/11
- 發布單位:Google
- 簡單摘要:autoencoding Transformer始祖,邁向NLP fine-tuning時代
- 閱讀重點:multi-layer bidirectional Transformer encoder、autoencoding model、masked token和next sentence predicition。
- 中文摘要:我們提出了一個名為BERT(從Transformer中得到的雙向編碼器表徵)的新語言表徵模型。與最近的語言表徵模型不同,BERT目標是從未標記文本中預訓練深度雙向表徵,同時在所有網路層上聯合考慮左右兩側的文本內容。因此預訓練的BERT模型只需進行一個額外的輸出層微調,就可以創建出各種任務的最新模型,例如問答和語言推理,而無需大幅修改特定任務的架構。BERT概念簡單且實驗證明其效果非常好。它在包括GLUE得分提升至80.5%(絕對改善了7.7個百分點)、MultiNLI準確度提升至86.7%(絕對改善了4.6個百分點)、SQuAD v1.1問答測試F1提升至93.2(絕對改善了1.5個百分點)和SQuAD v2.0測試F1提升至83.1(絕對改善了5.1個百分點)等11項自然語言處理任務中取得了新的最佳結果。
- 論文連結:https://arxiv.org/pdf/1810.04805.pdf
5. Transformer-XL
- 論文名稱:Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
- 發布時間:2019/01/09
- 發布單位:Google、卡內基麥隆大學
- 簡單摘要:讓Transformer可以吃更長的句子
- 閱讀重點:context fragmentation、segment-level recurrence mechanism、relative position embedding
- 中文摘要:Transformer模型在學習長期依賴性方面具有潛力,但在語言模型的情境下受到固定長度上下文的限制。我們提出了一種新穎的架構Transformer-XL,能夠在不干擾時間連貫性的情況下實現超越固定長度的依賴性。它包括一個分段層級的循環機制和一種新穎的位置編碼方法。我們的方法不僅能捕捉更長期的依賴性,還解決了上下文碎片化的問題。在結果中,Transformer-XL學習的依賴性比RNNs長80%,比原本的Transformer長450%,並在短序列和長序列上都表現更好,且評估過程中比基本的Transformer快了1800倍以上。特別值得注意的是,我們在bpc/perplexity上將enwiki8改進到了0.99,text8改進到了1.08,WikiText-103改進到了18.3,One Billion Word改進到了21.8,Penn Treebank改進到了54.5(無需微調)。當僅在WikiText-103上進行訓練時,Transformer-XL能夠生成具有數千個標記的合理連貫的新文章。
- 論文連結:https://arxiv.org/pdf/1901.02860.pdf
6. Adapter
- 論文名稱:Parameter-Efficient Transfer Learning for NLP
- 發布時間:2019/02/02
- 發布單位:Google、亞捷隆大學
- 簡單摘要:每多一個任務就要fine-tune一次好浪費,弄個小adapter吧
- 閱讀重點:bottleneck adapter module、adapter大小、parameter/performance trade-off
- 中文摘要:對於自然語言處理,微調大型預訓練模型是一種有效的遷移式學習方式。然而在有許多下游任務的情況下,微調是一件參數效率低的事情,因為每個任務都需要一個全新的模型。作為替代方案,我們提出了使用適配器模組進行遷移式學習。適配器模組使模型更加簡潔且易擴展;它們每個任務只添加了少量可訓練參數,新任務可以添加而無需重新處理先前的任務。原始網絡的參數保持固定,實現了高度的參數共享。為了展示適配器的效果,我們將最近提出的BERT Transformer模型應用到包括GLUE基準測試在內的26個不同的文本分類任務上。適配器取得了接近最佳表現的結果,而每個任務只添加了極少的參數。在GLUE測試中,我們的表現接近全面微調的水平,每個任務只增加了3.6%的參數,相比之下,全面微調則需要訓練100%的參數。
- 論文連結:https://arxiv.org/pdf/1902.00751.pdf
7. GPT-2
- 論文名稱:Language models are unsupervised multitask learners
- 發布時間:2019/02/24
- 發布單位:OpenAI
- 簡單摘要:不想fine-tune,我想要一個通用模型所有任務直接zero-shot
- 閱讀重點:multi-task pre-training、模型到底是達到generalization還是memorization
- 中文摘要:自然語言處理任務,如問答、機器翻譯、閱讀理解和摘要,通常使用特定任務的監督式學習來處理。我們展示了語言模型在沒有明確監督的情況下,學習名為WebText的數百萬網頁數據集。當語言模型在一個文檔加上一個問題的情境下,生成的答案在CoQA數據集上達到55的F1分數,與4個基準系統中的3個相匹配或超越,而不需要使用超過127,000個訓練範例。語言模型的容量對於zero-shot任務遷移的成功至關重要,增加容量能夠以對數線性方式提升跨任務的性能。我們最大的模型GPT-2是一個擁有15億參數的Transformer,在zero-shot設置下,在8個測試的語言模型數據集中有7個達到了最新的結果,但在WebText上仍然不夠充分。模型產生的樣本反映了這些改進,包含了連貫的文字段落。這些發現暗示了一條有前景的道路,即構建能夠從自然發生的範例中學習執行任務的語言處理系統。
- 論文連結:https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf
8. UniLM
- 論文名稱:Unified Language Model Pre-training for Natural Language Understanding and Generation
- 發布時間:2019/05/08
- 發布單位:Microsoft
- 簡單摘要:讓我們把NLU和NLG預訓練統一吧
- 閱讀重點:pretrain task設計、包括bidirectional encoding、unidirectional decoding、sequence-to-sequence。
- 中文摘要:這篇論文介紹了一個新的統一預訓練語言模型(UNILM),能夠進行自然語言理解和生成任務的微調。該模型通過三種語言模型任務進行預訓練:單向、雙向和序列到序列預測。這種統一建模是通過使用共享的Transformer網絡和特定的自注意力遮罩來控制預測所依賴的內容實現的。UNILM在GLUE基準測試中與BERT相比表現優異,在SQuAD 2.0和CoQA問答任務上也有出色表現。此外UNILM在五個自然語言生成數據集上取得了新的最佳結果,包括將CNN/DailyMail摘要的ROUGE-L提高到40.51(絕對改善2.04),Gigaword摘要的ROUGE-L提高到35.75(絕對改善0.86),CoQA生成式問答的F1分數提高到82.5(絕對改善37.1),SQuAD問題生成的BLEU-4提高到22.12(絕對改善3.75),以及DSTC7基於文件的對話回應生成的NIST-4提高到2.67(人類表現為2.65)。
- 論文連結:https://arxiv.org/pdf/1905.03197.pdf
9. ERNIE
- 論文名稱:ERNIE: Enhanced Language Representation with Informative Entities
- 發布時間:2019/05/17
- 發布單位:北京清華大學、華為
- 簡單摘要:把知識圖譜一起整合在BERT上
- 閱讀重點:Structured Knowledge Encoding、Heterogeneous Information Fusion、Knowledgeable Encoder
- 中文摘要:神經語言表徵模型,例如在大規模文本語料庫上預先訓練的BERT,能夠從純文本中捕捉豐富的語義模式,並進行微調以持續提升各種自然語言處理任務的性能。但是現有的預訓練語言模型很少考慮將知識圖譜(KGs)納入其中,而KGs可以提供豐富的結構化知識事實,有助於更好地理解語言。我們認為KGs中的訊息性實體可以增強語言表徵的外部知識。所以我們同時利用大規模文本語料庫和知識圖譜來訓練一個增強語言表示模型(ERNIE),它能同時充分利用詞彙、句法和知識訊息。實驗結果表明,ERNIE在各種知識驅動任務上取得了顯著的改善,同時在其他常見的自然語言處理任務上與最先進的模型BERT相當。
- 論文連結:https://arxiv.org/pdf/1905.07129.pdf
10. XLNet
- 論文名稱:XLNet: Generalized Autoregressive Pretraining for Language Understanding
- 發布時間:2019/06/19
- 發布單位:Google、卡內基麥隆大學
- 簡單摘要:autoregressive和autoencoding的好處我全都要
- 閱讀重點:permutation language modeling、content和query stream attention、partial prediction、怎麼套用Transformer-XL
- 中文摘要:利用模型雙向上下文建模的能力,像BERT這樣基於去噪自編碼的預訓練方法比基於自回歸語言建模的方法表現更好。但是BERT依靠對輸入進行遮罩處理,忽略了遮罩位置之間的依賴關係,存在預訓練和微調之間的差異。鑑於這些優點和缺點,我們提出了XLNet,這是一種通用的自回歸預訓練方法,(1)通過最大化分解順序所有排列的期望概率來實現學習雙向上下文,(2)使用自回歸的形式克服了BERT的限制。此外XLNet融合了Transformer-XL的思想,在預訓練中做了整合。實驗結果顯示,在可比較的實驗設置下,XLNet在20個任務上表現優於BERT,其中包括問答、自然語言推理、情感分析和文件排序等。
- 論文連結:https://arxiv.org/pdf/1906.08237.pdf
11. RoBERTa
- 論文名稱:RoBERTa: A Robustly Optimized BERT Pretraining Approach
- 發布時間:2019/07/26
- 發布單位:Facebook(Meta)、華盛頓大學
- 簡單摘要:我用了更多資源、更猛的方法訓練一個更猛的BERT
- 閱讀重點:dynamic masking、next sentence prediction重要嗎。
- 中文摘要:語言模型的預訓練帶來了顯著的性能提升,但仔細比較不同方法的成效是具有挑戰性的事情。訓練過程耗費計算資源,且通常會使用不同大小的私有數據集,另外正如我們所展示的,超參數的選擇對最終結果有著顯著的影響。所以我們進行了一項BERT預訓練的複現研究,仔細測量了許多關鍵超參數和訓練數據大小對結果的影響。我們發現BERT是訓練不足的,實際上其可以超越其之後發表的每個模型的表現。我們最佳的模型在GLUE、RACE和SQuAD上取得了最先進的結果。這些結果凸顯了先前被忽視的設計選擇的重要性,並提出了對最近論文改進來源的疑問。
- 論文連結:https://arxiv.org/pdf/1907.11692.pdf
12. ALBERT
- 論文名稱:ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
- 發布時間:2019/07/26
- 發布單位:Google、Toyota
- 簡單摘要:我把BERT參數減少,然後加上了一個酷酷的自監督式學習
- 閱讀重點:factorized embedding parameterization、cross-layer parameter sharing、inter-sentence coherence loss
- 中文摘要:在預訓練自然語言表徵時,增加模型大小通常會提升後續任務的表現。但是當模型進一步增加時,由於GPU/TPU記憶體限制和訓練時間變長,進一步的提升會變得更加困難。為了解決這些問題,我們提出了兩種參數減少的技術,以降低記憶體消耗並增加BERT的訓練速度。全面的實驗證據顯示,我們提出的方法使模型與原始BERT相比更具可擴展性。我們還使用了一種自監督損失函數,專注於模型句子間的一致性,並展示它能穩定地幫助具有多句輸入的後續任務。因此我們最佳的模型在GLUE、RACE和SQuAD基準測試上取得了新的最先進結果,同時與BERT-large相比具有更少的參數。
- 論文連結:https://arxiv.org/pdf/1909.11942.pdf
13. DistilBERT
- 論文名稱:DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
- 發布時間:2019/10/02
- 發布單位:Hugging Face
- 簡單摘要:利用知識蒸餾訓練更小的BERT。
- 閱讀重點:Teacher-Student的架構、distillation loss
- 中文摘要:隨著大規模預訓練模型在自然語言處理中變得更加普遍,將這些大模型應用在邊緣運算或有限計算資源的情況下仍然具有挑戰性。在這項工作中,我們提出了一種方法來預訓練一個較小的通用語言表徵模型,稱為DistilBERT,然後可以對其進行微調,使其在各種任務上表現的和大型模型一樣好。儘管大多數先前的工作都探討了使用蒸餾方法來構建特定任務模型,我們在預訓練階段利用知識蒸餾,並展示了可以將BERT模型的尺寸減少40%,同時保留了97%的語言理解能力並且速度提升了60%。為了利用大型模型在預訓練過程中學到的歸納偏差,我們引入了三重損失,結合了語言模型、蒸餾和餘弦距離損失,讓我們可以以更便宜的價格預訓練更小、更快、更輕的模型,並且在概念驗證實驗和在設備比較研究中展示了其在設備上計算的能力。
- 論文連結:https://arxiv.org/pdf/1910.01108.pdf
14. T5
- 論文名稱:Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
- 發布時間:2019/10/23
- 發布單位:Google
- 簡單摘要:把NLU和NLG全部都當成seq2seq任務來訓練吧
- 閱讀重點:input and output format、架構比較、預訓練任務目標、ensemble效果比較
- 中文摘要:遷移式學習在NLP中嶄露頭角,其指的是模型先在數據豐富的任務上進行預訓練,然後再微調用於後續任務,這種方式已成為一種強大的技術。遷移式學習的有效性催生了多種方法、理論和實踐。所以本文通過引入一個統一框架,將所有基於文本的語言問題轉換成文本到文本的格式,來探索NLP的遷移式學習技術。我們的系統性研究比較了數十種語言理解任務的預訓練目標、架構、無標註數據集、遷移式方法等因素。通過將我們探索的見解與規模和新的“巨大清理爬取語料庫”相結合,我們在許多涵蓋摘要、問答、文本分類等領域的基準測試中取得了最先進的結果。
- 論文連結:https://arxiv.org/pdf/1910.10683.pdf
15. BART
- 論文名稱:BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
- 發布時間:2019/10/29
- 發布單位:Facebook(Meta)
- 簡單摘要:把BERT(encoder)跟GPT(decoder)拼起來不香嗎
- 閱讀重點:模型架構、pre-training任務設計、machine translation額外的encoder
- 中文摘要:我們提出了BART,一種用於預訓練序列到序列模型的去噪自編碼器。BART的訓練方式是(1)利用任意的雜訊函數破壞文本,以及(2)學習模型來重建原始文本。其使用了標準的基於Transformer的神經機器翻譯架構,其概念可以視為將BERT(因為具有雙向編碼器)、GPT(具有從左到右的解碼器)和許多其他近期預訓練方案的泛化。我們評估了多種加入雜訊的方法,發現通過隨機重排原始句子的順序以及使用一種新的內填充方案(將文本片段替換為單個遮罩標記)可以獲得最佳性能。另外BART在進行文本生成的微調時特別有效,對於理解任務也表現得相當良好。在GLUE和SQuAD上與RoBERTa的性能相匹配,在一系列摘要對話、問答和摘要任務上實現了新的最先進結果,在僅目標語言預訓練的情況下,ROUGE可以高達6。BART相比於後向翻譯系統為機器翻譯帶來了1.1 BLEU的提升。最後我們還通過BART框架內復制其他預訓練方案的消融實驗,以更好地衡量哪些因素最影響最終任務的表現。
- 論文連結:https://arxiv.org/pdf/1910.13461.pdf
16. Reformer
- 論文名稱:Reformer: The Efficient Transformer
- 發布時間:2020/01/13
- 發布單位:Google
- 簡單摘要:讓Transformer運算更快、使用記憶體更有效
- 閱讀重點:locality sensitive hashing attention、reversible Transformer、chunking
- 中文摘要:大型Transformer模型在許多任務上常常取得最先進的成果,但訓練這些模型,尤其是在處理長序列時,可能的成本過高。所以我們引入了兩種提高Transformer效率的技術。首先我們將點積注意力機制替換為局部敏感哈希,將其複雜度從O(L²)降低到O(Llog L),其中L為序列長度。此外我們使用可逆的殘差層代替標準的殘差層,這使得在訓練過程中只需要存儲激勵值一次,而不是N次,其中N是層數。最終產生的模型,Reformer,在長序列上的效能與Transformer模型相當,同時具有更高的記憶體效率和更快的速度。
- 論文連結:https://arxiv.org/pdf/2001.04451.pdf
17. Scaling Laws
- 論文名稱:Scaling Laws for Neural Language Models
- 發布時間:2020/01/23
- 發布單位:OpenAI
- 簡單摘要:最早的LLM規模定律全面分析
- 閱讀重點:算力、資料、參數大小對模型性能影響、L(N, D) Equation、critical batch size、Early Stopping Step
- 中文摘要:我們研究了語言模型在交叉熵損失上的實證擴展規律。損失會隨著模型大小、數據集大小和用於訓練的計算量呈現冪律變化,某些趨勢跨度超過七個量級。其他如網絡寬度或深度等架構細節,在很大範圍內影響較小。另外我們提出簡單的方程式控制了過擬合與模型/數據集大小之間的依賴關係,以及訓練速度與模型大小之間的依賴關係。這些關係讓我們能夠確定固定計算預算的最佳分配方式,讓較大的模型能更有效地利用樣本。因此最有效的計算高效訓練方式涉及在相對較少的數據上訓練非常大的模型,在收斂之前明顯停止訓練。
- 論文連結:https://arxiv.org/pdf/2001.08361.pdf
18. Dense Passage Retrieval (DPR)
- 論文名稱:Dense Passage Retrieval for Open-Domain Question Answering
- 發布時間:2020/04/10
- 發布單位:Facebook(Meta)、華盛頓大學、普林斯頓大學
- 簡單摘要:RAG的前身,弄個效率更高的檢索模型來對應開放式問題吧
- 閱讀重點:dual-encoder、dot-product similarity、positive and negative passages
- 中文摘要:開放領域的問答依賴於有效的段落檢索,以選擇候選文本,傳統的稀疏向量空間模型(如TF-IDF或BM25)是已被實踐的方法。在這項工作中,我們展示了檢索可以僅使用密集表徵來實現,透過一個簡單的雙編碼器框架,從少量問題和段落中學習嵌入。在廣泛的開放領域問答數據集上評估時,我們的密集檢索器在前20個段落檢索準確度方面表現優於Lucene-BM25系統,絕大部分提升9%-19%絕對值,並幫助我們的端到端問答系統在多個開放領域問答基準上建立了新的最先進水平。
- 論文連結:https://arxiv.org/pdf/2004.04906.pdf
19. Longformer
- 論文名稱:Longformer: The Long-Document Transformer
- 發布時間:2020/04/10
- 發布單位:Allen Institute
- 簡單摘要:讓self-attention從次方減到線性複雜度
- 閱讀重點:sliding window attention、dilated sliding window、global attention
- 中文摘要:Transformer-based模型由於其自注意力操作的特性,無法處理長序列,其計算複雜度隨著序列長度呈平方級數增長。為解決此限制,我們引入了Longformer,其注意力機制能夠線性地隨著序列長度增長,輕鬆處理包含數千個標註或更長的文件。Longformer的注意力機制可直接替換標準的自注意力機制,結合局部窗口注意力和面向任務的全局注意力。另外與以往長序列Transformer相比,我們在字符級語言模型方面評估了Longformer,在text8和enwik8上取得了最先進的成果。與大多數以往工作不同的是,我們還對Longformer進行了預訓練,並在多個下游任務上進行微調。我們的預訓練Longformer在長文檔任務上一貫優於RoBERTa,並在WikiHop和TriviaQA上設定了新的最先進成果。最後我們引入了Longformer-Encoder-Decoder(LED),這是Longformer的變體,用於支持長文檔的生成序列到序列任務,在arXiv摘要數據集上展示了其有效性。
- 論文連結:https://arxiv.org/pdf/2004.05150.pdf
20. Retrieval-Augmented Generation (RAG)
- 論文名稱:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- 發布時間:2020/05/22
- 發布單位:Facebook(Meta)、倫敦大學學院、紐約大學
- 簡單摘要:結合資料庫檢索,讓LLM變得更強、回答訊息更正確
- 閱讀重點:RAG-sequence和RAG-token model,retriever和generator架構
- 中文摘要:大型預訓練語言模型已證實在其參數中儲存事實知識,並在微調後在下游自然語言處理任務中取得了最先進的成果。然而它們訪問和精確操作知識的能力仍然有限,在知識密集型任務上,它們的表現落後於特定任務架構。此外為其決策提供出處訊息和更新其世界知識,仍是開放性的研究問題。雖然具有可微訪問機制的預訓練模型,能夠使用明確的非參數化記憶,但到目前為止,這些模型僅用於探討摘要性的下游任務。所以我們探索了一種用於檢索增強生成(RAG)的通用微調方法 — 這些模型結合了預訓練的參數化和非參數化記憶以進行語言生成。在RAG模型中,參數化記憶是一個預訓練的seq2seq模型,而非參數化記憶是維基百科的密集向量索引,其通過預訓練的神經檢索器進行訪問。另外我們比較了兩種RAG形式,一種在整個生成序列中條件於相同的檢索段落,另一種可以每個標註使用不同的段落。我們對一系列知識密集型自然語言處理任務進行了微調和評估,在三個開放領域的問答任務中取得了最先進的成果,優於參數化seq2seq模型和特定任務的檢索和提取架構。對於語言生成任務,我們發現RAG模型生成的語言更加具體、多樣且具有事實性,超過了最先進的僅參數化seq2seq基線。
- 論文連結:https://arxiv.org/pdf/2005.11401.pdf
21. GPT-3
- 論文名稱:Language Models are Few-Shot Learners
- 發布時間:2020/05/28
- 發布單位:OpenAI
- 簡單摘要:別再玩fine-tune了,in-context learning和錢錢才是王道
- 閱讀重點:limitations、不使用fine-tune原因、data contamination、in-context learning
- 中文摘要:最近的研究表明,通過對大量文本進行預訓練,然後在特定任務上進行微調,可以在許多自然語言處理任務和基準測試中取得顯著進展。儘管在架構上通常是通用任務的,但這種方法仍需要數千甚至數萬個特定任務的微調數據集。相比之下,人類通常可以僅憑幾個例子或簡單的指令來完成新的語言任務,而當前的自然語言處理系統在這方面仍然存在很大挑戰。所以在這裡,我們擴展語言模型,來大幅改善了通用任務、少量樣本的性能,有時甚至達到了與先前最先進的微調方法相競爭的水平。具體而言,我們訓練了GPT-3,其是一個自回歸語言模型,具有1750億參數,比之前的非稀疏語言模型多10倍,並在少樣本情況下測試其性能。對於所有任務,GPT-3在沒有任何梯度更新或微調的情況下應用,也就是任務和少量範例的情境,純粹通過與模型的文本交互來指定。GPT-3在許多自然語言處理數據集上表現出色,包括翻譯、問答和填空任務,以及一些需要即時推理或領域適應的任務,比如拼字、在句子中使用新詞或進行3位數的算術運算。但是同時我們還發現了一些數據集,GPT-3的少樣本學習仍然存在困難,以及一些GPT-3面臨與在大型Web文集上訓練相關的方法問題。最後我們發現GPT-3可以用來生成新聞文章樣本,人類評估者很難將其與人寫的文章區分。另外我們也討論了這一發現和GPT-3整體對社會的更廣泛影響。
- 論文連結:https://arxiv.org/pdf/2005.14165.pdf
22. Big Bird
- 論文名稱:Big Bird: Transformers for Longer Sequences
- 發布時間:2020/07/28
- 發布單位:Google
- 簡單摘要:把序列的二次依賴降到線性,來處理更長的context
- 閱讀重點:sparse attention、graph sparsification problem、Turing complete、internal和extended transformer construction
- 中文摘要:BERT是一種基於Transformers的模型,在自然語言處理方面表現優異。然而它們的核心限制之一是由於全注意力機制導致的序列長度對記憶的二次依賴。為了克服這個問題,我們提出了BigBird,它使用了稀疏注意力機制,將這種二次依賴減少為線性。使外我們證明了BigBird是序列函數的通用逼近器並具有圖靈完備性,並保留了二次全注意力模型的這些特性。透過我們的理論分析,我們發現了具有複雜度O(1)全局標記(例如CLS)在稀疏注意力機制中涵蓋整個序列部分的一些優點。這種稀疏注意力可以處理比以前相似硬體設置所能處理的序列長度多8倍的文本。而由於處理更長範圍的能力,BigBird在問答和摘要等各種自然語言處理任務上顯著提升了性能。最後我們還提出了在基因組數據上的新應用。
- 論文連結:https://arxiv.org/pdf/2007.14062.pdf
23. AutoPrompt
- 論文名稱:AutoPrompt: Eliciting Knowledge from Language Models with Automatically Generated Prompts
- 發布時間:2020/10/29
- 發布單位:加州大學爾灣分校、加州大學柏克萊分校
- 簡單摘要:使用梯度搜尋自動產生prompt效果有時甚至比fine-tune好
- 閱讀重點:gradient-based prompt search、automating label token selection
- 中文摘要:預訓練語言模型的卓越成功激勵了對這些模型在預訓練期間所學習的知識類型的研究。將任務重新設定為填空問題(例如,完形填空測試)是評估此類知識的自然方法,但編寫適合提示,仍受限於人工處理和猜測。所以為了解決這個問題,我們開發了AutoPrompt,一種基於梯度引導搜索的自動方法,用於創建各種任務的提示。使用AutoPrompt,我們展示了遮罩語言模型(MLMs)具有在沒有額外參數或微調的情況下進行情感分析和自然語言推理的潛力,有時性能與最近最先進的監督式模型相當。我們還展示了我們的提示從MLMs中獲得比LAMA基準測試上手動創建的提示更準確的事實知識,以及MLMs可以比監督式關係提取模型更有效地用作關係提取器。這些結果表明,自動生成的提示是現有探測方法的無參替代方案,隨著預訓練語言模型變得更加複雜和強大,這可能成為微調的替代方案。
- 論文連結:https://arxiv.org/pdf/2010.15980.pdf
24. LM-BFF
- 論文名稱:Making Pre-trained Language Models Better Few-shot Learners
- 發布時間:2020/12/31
- 發布單位:普林斯頓大學、麻省理工
- 簡單摘要:用prompting讓一般模型few-shot fine-tune也可以表現很好
- 閱讀重點:prompt-based fine-tuning、prompting format、automatic prompt generation
- 中文摘要:最近的GPT-3模型僅透過自然語言提示和少量任務演示作為輸入內容就達到了驚人的少數樣本效能。受到這些發現的啟發,我們在更實際的情境中研究少樣本學習,使用了計算效率高的較小語言模型進行微調。所以我們提出了LM-BFF — 更好的少樣本語言模型微調,這是一套用於在少量標註範例上微調語言模型的簡單且互補的技術。我們的方法包括(1)基於提示的微調,以及自動化提示生成的新型流程;和(2)一種精緻的策略,動態且選擇性地將演示整合到每個上下文中。最後我們對各種NLP任務進行了系統性評估,分析了少樣本的效能,包括分類和回歸。我們的實驗表明,我們的方法結合在這種資源有限的情況下明顯優於標準的微調程序,效能提升高達30%,平均提升率為11%。我們的方法對任務資源和領域專業知識做出了最小的假設,因此對於少樣本學習來說,是一種強大且無關任務的方法。
- 論文連結:https://arxiv.org/pdf/2012.15723.pdf
25. Prefix-Tuning
- 論文名稱:Prefix-Tuning: Optimizing Continuous Prompts for Generation
- 發布時間:2021/01/01
- 發布單位:史丹佛大學
- 簡單摘要:不fine-tune整個模型了,我們來針對特定任務優化prefix
- 閱讀重點:Prefix-tuning在autoregressive LM和encoder-decoder模型、與prompting關聯性
- 中文摘要:這篇論文提出了「前綴微調」,這是在自然語言生成任務中的一種輕量級替代方法,與微調不同的是,它凍結了語言模型參數,但優化了一個小的特定任務連續向量(稱為前綴)。前綴微調靈感來自提示,讓後續的標記可以關注這個前綴,就像它是「虛擬標記」一樣。我們將前綴微調應用於表格生成和摘要生成任務,發現通過只學習0.1%的參數,前綴微調在完整數據設置下獲得了可比的性能,在少量數據情況下優於微調,並在訓練過程中未見的主題的範例中表現更好。
- 論文連結:https://arxiv.org/pdf/2101.00190.pdf
26. Switch Transformers
- 論文名稱:Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
- 發布時間:2021/01/11
- 發布單位:Google
- 簡單摘要:用Mixture of Experts架構可以有效設計更大的模型
- 閱讀重點:mixture of experts、switch routing、distributed switch implementation、scaling properties
- 中文摘要:這篇論文探討了深度學習中的「混合專家(MoE)」概念,這種模型每個輸入都選擇不同的參數,而不是共用相同的參數。這個稀疏激勵模型,擁有龐大的參數量,但計算成本保持不變。但儘管MoE有一些顯著的成功案例,但其廣泛應用受到了複雜性、通訊成本和訓練不穩定性的限制。所以我們提出Switch Transformer解決了這些問題。我們簡化了MoE路由演算法,設計了更直觀的改進模型,減少了通訊和計算成本。我們提出的訓練技術有助於解決不穩定問題,首次展示了大型稀疏模型可以使用更低精度(bfloat16)格式進行訓練。我們基於T5-Base和T5-Large設計的模型,在相同的計算資源下,預訓練速度提高了最多7倍。這些改進也適用於多語言環境,在101種語言中,我們在mT5-Base版本上實現了提升。最後我們將語言模型的規模提升到了兆參數級別,在「Colossal Clean Crawled Corpus」上進行預訓練,實現了比T5-XXL模型快4倍的速度。
- 論文連結:https://arxiv.org/pdf/2101.03961.pdf
27. Soft Prompts
- 論文名稱:The Power of Scale for Parameter-Efficient Prompt Tuning
- 發布時間:2021/04/18
- 發布單位:Google
- 簡單摘要:模型越大,Prompt tuning就能越接近Fine tuning效果
- 閱讀重點:prompt tuning、prompt desgin、unlearning span corruption、prompt ensembling、prompt可解釋性
- 中文摘要:這份研究探索了「提示調整」,這是一種簡單卻有效的機制,用於學習「軟性提示」,以條件化凍結的語言模型來執行特定的下游任務。不同於GPT-3使用的離散文本提示,軟性提示是通過反向傳播學習的,可以根據任意數量的標註範例進行調整。另外我們的端到端學習方法在「少樣本」學習方面遠優於GPT-3。更顯著的是,通過使用T5進行不同規模的模型大小消融實驗,我們發現隨著模型超過數十億參數,我們的方法「拉近了差距」,與模型調整(調整所有模型權重)的表現相匹敵。這一發現特別重要,因為大型模型的共享和服務成本高昂,使用一個凍結模型處理多個下游任務能夠減輕這種負擔。我們的方法可以看作是「前綴調整」的簡化版本,我們與該方法及其他類似方法進行了比較。最後我們發現,使用軟性提示來條件化凍結模型對於領域轉移的穩健性具有優勢,相較於完整模型的調整。
- 論文連結:https://arxiv.org/pdf/2104.08691.pdf
28. Rotary Position Embedding (RoPE)
- 論文名稱:RoFormer: Enhanced Transformer with Rotary Position Embedding
- 發布時間:2021/04/20
- 發布單位:追一科技
- 簡單摘要:目前在LLM上最普遍使用的embedding方式
- 閱讀重點:rotary position embedding、long-term decay性質、linear self-attention
- 中文摘要:這篇論文研究了位置編碼在Transformer結構中的有效性。它能夠為序列中不同位置的元素建立關聯,提供有價值的監督。我們首先探討了將位置訊息整合到基於Transformer的語言模型學習過程中的各種方法。接著我們提出了一種新方法,名為Rotary Position Embedding(RoPE),以有效利用位置訊息。具體而言,RoPE使用旋轉矩陣編碼絕對位置,同時在自注意力機制中結合了明確的相對位置依賴。值得注意的是,RoPE具有一些優勢,包括序列長度的靈活性、隨著相對距離增加而減弱的標註間依賴性,以及線性自注意力機制配備相對位置編碼的能力。最後我們在多個長文本分類基準數據集上評估了使用Rotary Position Embedding的增強Transformer,也稱為RoFormer。我們的實驗顯示它穩定地優於其他方法。此外我們提供了理論分析來解釋一些實驗結果。
- 論文連結:https://arxiv.org/pdf/2104.09864.pdf
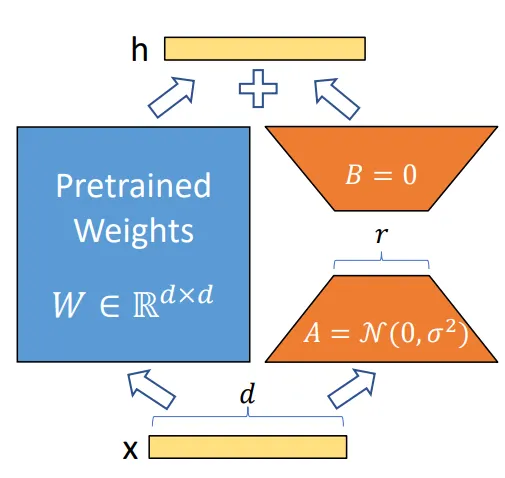
29. LoRA
- 論文名稱:LoRA: Low-Rank Adaptation of Large Language Models
- 發布時間:2021/06/17
- 發布單位:Microsoft
- 簡單摘要:Fine-tune不了整個LLM,那fine-tune一點點就好
- 閱讀重點:low-rank adaptation、inference latency和adapter問題、LoRA應用到Transformer、practical benefits and limitations
- 中文摘要:這篇論文探討了自然語言處理的重要範式,即在通用領域數據上進行大規模預訓練,然後適應特定任務或領域。隨著我們預訓練更大型的模型,重新調整全部模型參數(fine-tuning)的成本變得越來越高。例如使用GPT-3 175B,部署獨立已微調好的模型實例成本過高。所以我們提出了低秩適應(LoRA)的方法,凍結預訓練模型權重,並將可訓練的秩分解矩陣注入到Transformer架構的每一層中,大大減少下游任務所需的可訓練參數數量。相較於使用Adam進行的GPT-3 175B的全模型重新調整,LoRA可將可訓練參數數量減少10,000倍,GPU記憶體需求減少3倍。除了可訓練參數更少、訓練吞吐量更高,並且不像適配器那樣存在額外的推理延遲,LoRA在RoBERTa、DeBERTa、GPT-2和GPT-3模型上,與全模型重新微調有相當或更優的結果。我們還對語言模型適應中的秩缺陷進行了實證研究,這有助於我們更好地理解LoRA的有效性。
- 論文連結:https://arxiv.org/pdf/2106.09685.pdf
30. Codex
- 論文名稱:Evaluating Large Language Models Trained on Code
- 發布時間:2021/07/07
- 發布單位:OpenAI
- 簡單摘要:會寫程式的GPT
- 閱讀重點: HumanEval、unbiased estimator、code fine-tuning
- 中文摘要:我們推出了Codex,這是一個在GitHub上公開可用的程式碼進行微調的GPT語言模型,並研究了它在Python程式碼編寫方面的能力。Codex的特定生產版本為GitHub Copilot提供支持。另外我們發布了一個名為HumanEval的新評估資料集,用於測量從文檔字符串合成程序的功能正確性。在這個評估資料集中,我們的模型解決了28.8%的問題,而GPT-3解決了0%,GPT-J解決了11.4%。此外我們發現從模型中重複取樣對於生成複雜提示的可行解決方案非常有效。使用這種方法,我們在每個問題中通過100次取樣解決了70.2%的問題。仔細研究我們的模型顯示了它的一些限制,包括難以處理描述一長串操作的文檔字符串以及綁定操作到變量的困難。最後我們討論了部署強大的程式碼生成技術可能帶來的潛在廣泛影響,涵蓋了安全性、保密性和經濟性。
- 論文連結:https://arxiv.org/pdf/2107.03374.pdf
31. FLAN
- 論文名稱:Finetuned Language Models Are Zero-Shot Learners
- 發布時間:2021/09/03
- 發布單位:Google
- 簡單摘要:instruction-tuning讓模型更了解你想幹嘛
- 閱讀重點:instruction-tuning、task clusters、instruction templates
- 中文摘要:這篇論文探討了改善語言模型零樣本學習能力的簡單方法。我們展示了指令微調的方法,即在語言模型上進行微調,使用一系列通過指令描述的任務,顯著提高了對未知任務的零樣本性能。我們拿一個擁有 137B 參數的預訓練語言模型,並在超過 60 個自然語言指令模板的幫助下,針對多個 NLP 任務進行微調。我們將這個經過指令微調的模型命名為 FLAN,在未見過的任務類型上進行評估。FLAN 大幅提升了其未修改版本的性能,並在我們評估的 25 個任務中,有 20 個超越了零樣本 175B GPT-3。FLAN 在 ANLI、RTE、BoolQ、AI2-ARC、OpenbookQA 和 StoryCloze 等任務上甚至大幅優於少樣本的 GPT-3。消融研究顯示,微調資料集的數量、模型規模和自然語言指令是指令微調成功的關鍵因素。
- 論文連結:https://arxiv.org/pdf/2109.01652.pdf
32. T0
- 論文名稱:Multitask Prompted Training Enables Zero-Shot Task Generalization
- 發布時間:2021/10/15
- 發布單位:Hugging Face、布朗大學、BigScience…..
- 簡單摘要:prompt加上多任務學習,提升zero-shot能力
- 閱讀重點:held-out-task、unified prompt format
- 中文摘要:最近研究顯示大型語言模型在多種任務上能夠達到合理的零樣本泛化能力。有人假設這是因為語言模型在預訓練階段隱含地進行了多任務學習。所以我們提出一個系統,能將任何自然語言任務輕鬆轉換成人類可讀的提示形式,並在大量監督式數據集上進行測試。我們使用一個包含多種不同提示的監督式數據集,讓模型在全新任務上進行評估。我們對預訓練的編碼器-解碼器模型進行微調,其中涵蓋各種任務,並在多個標準數據集上實現了強大的零樣本性能,其往往超越了比自己大 16 倍的模型。此外,我們的方法在 BIG-bench 基準測試中也取得了強大表現,在某些任務上超越了比自己大 6 倍的模型。
- 論文連結:https://arxiv.org/pdf/2110.08207.pdf
33. RETRO
- 論文名稱:Improving language models by retrieving from trillions of tokens
- 發布時間:2021/12/08
- 發布單位:DeepMind
- 簡單摘要:有超大的資料庫可以檢索,我就可以以小搏大
- 閱讀重點:retrieval-enhanced autoregressive token models、使用BERT做retrieval neighbours、chunked cross-attention
- 中文摘要:我們通過條件設定於自回歸語言模型上,利用與先前標註相似的文件片段來檢索大型語料庫。基於使用一個 2 兆標記的資料庫,我們的「檢索增強變形器」(RETRO)在 Pile 數據集上獲得了與 GPT-3 和 Jurassic-1 相當的性能,儘管其使用的參數量少了 25 倍。在微調後,RETRO 的表現可轉化為問答等知識密集型任務。而 RETRO 將凍結的 Bert 檢索器、可微分編碼器和分塊交叉注意力機制結合在一起,基於比訓練過程中通常消耗的數據量多一個數量級來預測標記。另外通常我們會從頭開始訓練 RETRO,但也可以快速地將預訓練變形器與檢索進行 RETROfit,其同樣能取得良好表現。我們的工作為通過明確記憶在前所未有的規模上提升語言模型開辟了新途徑。
- 論文連結:https://arxiv.org/pdf/2112.04426.pdf
34. GLaM
- 論文名稱:GLaM: Efficient Scaling of Language Models with Mixture-of-Experts
- 發布時間:2021/12/13
- 發布單位:Google
- 簡單摘要:用MoE架構設計LLM準確率更高、訓練速度更快
- 閱讀重點:gating module、MoE和dense models比較、數據品質影響、scaling studies
- 中文摘要:我們在自然語言處理領域中,透過增加數據、計算和參數量,提升了語言模型的規模。例如GPT-3在上下文學習任務上取得了出色的成果,這歸功於模型規模的擴大。但是訓練這些大型密集模型需要大量的計算資源。所以本文中我們提出並開發了一系列名為 GLaM(通用語言模型)的語言模型,採用了稀疏啟動的混合專家架構來擴展模型容量,同時與密集變體相比,大幅降低了訓練成本。最大的 GLaM 模型擁有 1.2 兆個參數,大約是 GPT-3 的 7 倍大小。它的訓練能耗只有 GPT-3 的三分之一,且推理時需要的計算量也減少了一半,同時在 29 個自然語言處理任務中實現了更好的零樣本和單樣本學習表現。
- 論文連結:https://arxiv.org/pdf/2112.06905.pdf
35. WebGPT
- 論文名稱:WebGPT: Browser-assisted question-answering with human feedback
- 發布時間:2021/12/17
- 發布單位:OpenAI
- 簡單摘要:可以上網查資料的GPT-3變得更強大
- 閱讀重點:environment design、資料demonstrations和comparisons、強化學習和reward modeling
- 中文摘要:我們使用基於文本的網頁瀏覽環境對 GPT-3 進行微調,讓它可以回答長篇問題並搜索網頁。透過設置一個可以由人類執行的任務,我們可以使用模仿學習訓練模型,並通過人類反饋來優化回答的品質。為了讓人類更容易對事實準確性進行評估,模型必須在瀏覽時收集相關參考來支持它們的答案。另外我們在 ELI5 數據集上訓練和評估模型,該數據集包含 Reddit 用戶提出的問題。我們最佳的模型是通過行為複製微調 GPT-3 後,使用拒絕採樣與預測人類喜好的獎勵模型進行比較得到的。對於這個模型,人類在 56% 的情況下更喜歡這個模型的答案,而在 69% 的情況下更喜歡 Reddit 上得票最高的答案。
- 論文連結:https://arxiv.org/pdf/2112.09332.pdf
36. Chain-of-Thought
- 論文名稱:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
- 發布時間:2022/01/28
- 發布單位:Google
- 簡單摘要:給答案要給詳解,讓LLM回答變得更有邏輯、更正確
- 閱讀重點:chain-of-Thought Prompting、討論CoT有效原因
- 中文摘要:我們探索了如何通過生成一系列中間推理步驟,即”思維鍊”,來顯著提高大型語言模型執行複雜推理的能力。特別是我們展示了在足夠大的語言模型中,這種推理能力是如何通過一種稱為”思維鏈提示”的簡單方法自然產生的,該方法在提示中提供了一些思維鏈範例。在三個大型語言模型上的實驗表明,思維鏈提示提升了在一系列算術、常識和符號推理任務上的性能。實驗效果驚人,例如對一個具有 540 億參數的語言模型進行思維鏈提示,僅使用八個範例,在數學單詞問題的 GSM8K 基準上達到了最先進的準確率,甚至超過了經過微調的 GPT-3 與一個驗證器的表現。
- 論文連結:https://arxiv.org/pdf/2201.11903.pdf
37. AlphaCode
- 論文名稱:Competition-Level Code Generation with AlphaCode
- 發布時間:2022/02/08
- 發布單位:DeepMind
- 簡單摘要:寫程式打敗人類的LLM
- 閱讀重點:value conditioning & prediction、large scale sampling、filtering、clustering、能力限制
- 中文摘要:透過程式設計解決問題是一個強大且無所不在的工具。開發能協助程式設計師甚至獨立生成程式的系統,可以提高程式設計的生產力和可及性,但將人工智慧的創新納入其中一直是具有挑戰性的研究。近期的大型語言模型展現出了令人印象深刻的生成程式的能力,現在已能完成簡單的編程任務。然而這些模型在評估更複雜、未曾見過的問題時表現不佳,這些問題需要超越將指令翻譯成程式碼的技能,例如競技程式問題,需要理解算法和複雜的自然語言,至今仍然極具挑戰性。為了填補這個差距,我們引入了 AlphaCode,這是一個用於程式碼生成的系統,可以創建對這些需要更深入推理的問題提出新解。在 Codeforces 平台上模擬的編程競賽評估中,AlphaCode 在超過 5,000 名參與者的比賽中平均排名前 54.3%。我們發現三個關鍵因素對於獲得良好和可靠的性能至關重要:(1)用於訓練和評估的大規模、乾淨的競技程式數據集,(2)大型且高效取樣的 transformer 的架構,和(3)大規模模型取樣來探索搜索空間,然後根據程式行為將結果篩選為一小部分提交內容。
- 論文連結:https://arxiv.org/pdf/2203.07814.pdf
38. PaLM
- 論文名稱:PaLM: Scaling Language Modeling with Pathways
- 發布時間:2022/04/05
- 發布單位:Google
- 簡單摘要:訓練LLM的大型系統
- 閱讀重點:pathways system、discontinuous improvements
- 中文摘要:大型語言模型已被證明能夠在各種自然語言任務上取得卓越表現,使用了少樣本學習(few-shot learning),顯著減少了適應特定應用所需的特定訓練樣本數量。為了進一步了解規模對少樣本學習的影響,我們訓練了一個名為 Pathways Language Model(PaLM)的 5400 億參數的密集激勵 Transformer 語言模型。我們使用 Pathways 這個新的 ML 系統在 6144 個 TPU v4 芯片上進行了 PaLM 的訓練,該系統能夠實現跨多個 TPU Pod 的高效訓練。我們也展示了通過規模擴展所帶來的持續效益,PaLM 540B 在數百個語言理解和生成測試中實現了最新的少樣本學習結果。在其中一些任務中,PaLM 540B 實現了突破性的性能,優於一系列多步推理任務的微調最新技術,並在最近發布的 BIG-bench 測試中超越了人類的平均表現。大量的 BIG-bench 任務顯示模型規模的增大帶來了不連續的改進,這意味著隨著我們擴展到最大的模型,性能會急劇提高。我們也在各種測試中進行了展示,PaLM 在多語言任務和程式碼生成方面也具有強大的能力。此外我們還對偏見和惡意訊息進行了全面分析,並研究了模型規模對訓練數據記憶的程度。最後我們討論了與大型語言模型相關的道德考量,並探討了潛在的緩解策略。
- 論文連結:https://arxiv.org/pdf/2204.02311.pdf
39. InstructGPT
- 論文名稱:Training language models to follow instructions with human feedback
- 發布時間:2022/05/04
- 發布單位:OpenAI
- 簡單摘要:ChatGPT的前身,讓人類來教GPT-3社會化
- 閱讀重點:supervised policy、reward model訓練、用PPO優化針對reward model的policy
- 中文摘要:擴大語言模型的規模並不一定會使其更能理解用戶的意圖。舉例來說,大型語言模型可能產生不真實、惡意,或者對用戶沒有幫助的輸出。換句話說,這些模型與其用戶並不完全一致。所以在這篇論文中,我們展示了一種通過人類反饋來對語言模型進行微調,從而使其在各種任務中與用戶意圖保持一致的方法。我們首先從一組由標註者編寫的提示和透過 OpenAI API 提交的提示開始,收集了一組標註者展示所需模型行為的數據集,然後使用監督學習對 GPT-3 進行微調。接著我們收集了模型輸出的排名數據集,進一步使用來自人類反饋的強化學習對這個監督模型進行微調。我們稱最終生成的模型為 InstructGPT。在我們的提示分發的人工評估中,儘管其參數數量少了 100 倍,擁有 13 億參數的 InstructGPT 模型的輸出優於 175 億參數的 GPT-3 的輸出。此外 InstructGPT 模型在真實性上有所提高,在減少惡意輸出產生的同時,在公開 NLP 數據集上幾乎沒有性能退步。儘管 InstructGPT 仍然會犯一些簡單的錯誤,但我們的結果顯示,通過人類反饋進行微調是使語言模型與人類意圖保持一致的一個有前景的方向。
- 論文連結:https://arxiv.org/pdf/2203.02155.pdf
40. Zero-shot-CoT
- 論文名稱:Large Language Models are Zero-Shot Reasoners
- 發布時間:2022/05/24
- 發布單位:Google、東京大學
- 簡單摘要:加上一句「讓我們一步一步思考」,LLM能力就上升了
- 閱讀重點:zero-shot-CoT、reasoning extraction、answer extraction
- 中文摘要:這份論文關於大型預訓練語言模型(LLMs)在自然語言處理(NLP)中的使用。通常LLMs以少量範例即可學會新任務,而「思維鍊」(CoT)提示則是近期的技術,透過逐步的回答範例來引出複雜的多步推理,它在數學和符號推理中取得了最先進的成果。雖然LLMs在少樣本學習能力能成功,但我們展示了,其實際上只要在每個答案前加上「讓我們一步一步地思考」,LLMs也能表現出不錯的zero-shot推理能力。實驗結果顯示,我們的zero-shot-CoT在各種推理任務上明顯優於zero-shot LLMs,包括算術、符號推理和邏輯推理任務,無需手工製作少量範例即可達成,例如使用大型InstructGPT模型將MultiArith的準確性從17.7%提高到78.7%,GSM8K從10.4%提高到40.7%,同樣將其他預訓練大型模型PaLM的參數540B的改善程度也相近。單一提示在非常不同的推理任務中展示了它的多樣性,暗示了LLMs潛在的zero-shot能力,其表明可透過簡單提示提取高層次、多任務的廣泛認知能力。我們希望這份研究不僅成為具有挑戰性的推理基準的最小最強zero-shot基準,同時也強調了在製作微調數據集或少量範例之前,仔細探索和分析LLMs內隱藏的巨大zero-shot知識的重要性。
- 論文連結:https://arxiv.org/pdf/2205.11916.pdf
41. FlashAttention
- 論文名稱:FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness
- 發布時間:2022/05/27
- 發布單位:史丹佛大學、紐約州立大學水牛城分校
- 簡單摘要:在GPU上讀寫速度更快的Transformers
- 閱讀重點:high bandwidth memory、SRAM、IO complexity analysis、block-sparse FlashAttention
- 中文摘要:這篇論文探討了Transformer模型在處理長序列時速度緩慢且需大量記憶體的問題,因為自注意力機制的時間和記憶體複雜度與序列長度呈二次方增加。雖然先前的研究嘗試以近似注意力方式解決此問題,但常常降低模型品質且無法明顯提升速度。所以我們主張缺乏的原因是使注意力機制IO感知,也就是考慮GPU記憶體層間的讀寫,基於此我們提出了FlashAttention,一種IO感知的精確注意力演算法,利用平鋪技術減少GPU高速記憶體(HBM)和GPU片上SRAM間的記憶體讀寫次數。我們分析了FlashAttention的IO複雜度,顯示其比標準注意力需要更少的HBM存取,並對一定SRAM尺寸來說是最優的。我們還將FlashAttention延伸到區塊稀疏注意力,得到比任何現有近似注意力方法更快的演算法。另外FlashAttention比現有基準模型訓練速度更快:BERT-large(序列長度512)相比MLPerf 1.1訓練速度記錄快了15%,GPT-2(序列長度1K)加速了3倍,長距離場景(序列長度1K-4K)提升了2.4倍。FlashAttention和區塊稀疏FlashAttention使Transformer模型能處理更長的上下文,提高了模型品質(GPT-2的困惑度提高了0.7,長文件分類提升了6.4個點),並具有全新能力:首次在Path-X挑戰中(序列長度16K,61.4%準確率)和Path-256(序列長度64K,63.1%準確率)超過隨機猜測的表現。
- 論文連結:https://arxiv.org/pdf/2205.14135.pdf
42. Chinchilla’s Law
- 論文名稱:Training Compute-Optimal Large Language Models
- 發布時間:2022/05/29
- 發布單位:DeepMind
- 簡單摘要:更全面的scaling law,訓練LLM所需資源定律
- 閱讀重點:optimal parameter/training tokens allocation、optimal model scaling、model size和training tokens最佳化方程式
- 中文摘要:我們研究了在特定計算預算下,訓練Transformer語言模型的最佳模型大小和標註數量。我們發現目前的大型語言模型訓練不足,這是近期將語言模型擴展的焦點,同時保持訓練數據量不變所致。通過訓練超過 400 個語言模型,參數範圍從 7,000 萬到超過 160 億,標註數量範圍從 50 億到 500 億,我們發現對於最佳計算訓練,模型大小和訓練標記數量應該等比例增加:模型大小每翻倍,訓練標記數量也應翻倍。我們通過訓練一個預測的計算最佳模型「Chinchilla」來測試這個假設,它使用與 Gopher 相同的計算預算,但擁有 700 億參數和 4 倍的數據量。Chinchilla 在大範圍的下游評估任務中一致且顯著地優於 Gopher(280B)、GPT-3(175B)、Jurassic-1(178B)和 Megatron-Turing NLG(530B)。這意味著 Chinchilla 在精細調整和推理過程中需要的計算量大大減少,極大地方便了下游應用。值得一提的是,Chinchilla 在 MMLU 基準測試中達到了 67.5% 的最高平均準確率,比 Gopher 提高了超過 7%。
- 論文連結:https://arxiv.org/pdf/2203.15556.pdf
43. Emergent Abilities
- 論文名稱:Emergent Abilities of Large Language Models
- 發布時間:2022/06/15
- 發布單位:Google、DeepMind、史丹佛大學、北卡羅萊大學
- 簡單摘要:為什麼LLM突然頓悟了?
- 閱讀重點:emergence in the few-shot prompting、emergence的可能原因、beyond scaling、未來可能方向
- 中文摘要:擴大語言模型已被證明可以預測性地提升在各種下游任務中的表現和樣本效率。在這篇論文討論了一個無法預測的現象,我們稱之為大型語言模型的「能力湧現」。如果它在較小的模型中不存在,但在較大的模型中存在。因此能力湧現無法僅僅通過推斷較小模型的性能來預測。這種新能力的存在代表著進一步的擴展語言模型的規模可能會進一步擴展其能力範圍。
- 論文連結:https://arxiv.org/pdf/2206.07682.pdf
44. LLM.int8()
- 論文名稱:LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale
- 發布時間:2022/08/15
- 發布單位:Facebook(Meta)、華盛頓大學、Hugging Face
- 簡單摘要:把float16/32精度的LLM轉成int8,GPU就跑得動了
- 閱讀重點:8-bit quantization、matrix nultiplication、vector-wise quantization、mixed-precision decomposition
- 中文摘要:大型語言模型被廣泛採用,但推斷過程需要大量GPU記憶體。所以我們開發了一種Int8矩陣乘法程序,適用於transformer中的前饋和注意力投影層,將推斷所需的記憶體減少了一半,同時保持完整的精確度表現。透過我們的方法,可以加載175B參數的16/32位檢查點,轉換為Int8,並立即使用,而不會有性能下降。這是因為我們理解和處理了transformer語言模型中高度系統化的新特徵,這些特徵主導了注意力和預測性能。為應對這些特徵,我們開發了LLM.int8()的兩部分量化程序。首先我們使用向量量化,為矩陣乘法中的每個內積使用單獨的歸一化常數,對大多數特徵進行量化。然而對於新出現的極端值,我們還包括一種新的混合精度分解方案,將這些特異特徵維度分離出一個16位矩陣乘法,而仍然有超過99.9%的值在8位中進行乘法。透過LLM.int8(),我們實證表明可以在具有175B參數的LLMs中進行推斷,而不會有任何性能下降。這一結果使得這樣的模型更加易於使用,例如在單個使用消費級GPU的服務器上使用OPT-175B/BLOOM。
- 論文連結:https://arxiv.org/pdf/2208.07339.pdf
45. ReAct
- 論文名稱:ReAct: Synergizing Reasoning and Acting in Language Models
- 發布時間:2022/10/06
- 發布單位:Google、普林斯頓大學
- 簡單摘要:結合思維鏈提示和行動計劃生成,防止LLM胡言亂語
- 閱讀重點:Synergizing Reasoning、Acting、knowledge-intensive reasoning tasks
- 中文摘要:大型語言模型(LLMs)在語言理解和互動決策方面展現了令人印象深刻的能力,但它們的推理能力(例如思維鏈提示)和行動能力(例如行動計劃生成)主要是作為獨立的主題來研究的。所以本文探討了LLMs以交叉方式生成推理跟蹤和特定任務的行動,讓兩者之間更協同:推理跟蹤幫助模型誘導、追蹤、更新行動計劃並處理異常情況,而行動則允許它與知識庫或環境等外部來源互動,收集額外訊息。我們的方法名為ReAct,在多種語言和決策任務上展示了比最先進基準更有效的效果,同時相較於沒有推理或行動元件的方法,具有更好的人類可解釋性和可信度。具體來說在問答(HotpotQA)和事實驗證(Fever)方面,ReAct通過與簡單的維基百科API互動,克服了思維鏈推理中出現的幻覺和錯誤傳播問題,生成了更具可解釋性的人類化任務解決軌跡,優於沒有推理跟蹤的基準。在兩個互動式決策基準(ALFWorld和WebShop)上,即使只提示了一兩個上下文示例,ReAct的成功率分別比模仿學習和強化學習方法提高了34%和10%。
- 論文連結:https://arxiv.org/pdf/2210.03629.pdf
46. Flan-PaLM
- 論文名稱:Scaling Instruction-Finetuned Language Models
- 發布時間:2022/10/20
- 發布單位:Google
- 簡單摘要:模型大小、任務數量、CoT對instruction finetuning很重要
- 閱讀重點:flan finetuning、scaling parameters ans tasks、finetuning with chain-of-thought
- 中文摘要:這篇論文探討了以指令形式進行微調語言模型,這種方法已證實能夠提高模型的性能並應對未見過的任務。所以我們聚焦於三個方面:(1) 擴展任務數量、(2) 擴大模型規模、(3) 在思維鏈維數據上進行微調。研究發現,使用這些方法對各種模型(PaLM、T5、U-PaLM)、提示設置(零樣本、少樣本、思維鏈)和評估基準(MMLU、BBH、TyDiQA、MGSM、開放式生成)的表現有顯著改善。例如使用1.8K個任務對Flan-PaLM 540B進行指令微調,其性能顯著優於PALM 540B(平均+9.4%)。Flan-PaLM 540B在一些基準測試中達到了最先進的性能,如在五樣本MMLU上達到了75.2%。此外我們還公開了Flan-T5的檢查點,即使與更大的模型(例如PaLM 62B)相比,它在少樣本測試中也表現出色。總體而言,指令微調是提升預訓練語言模型性能和可用性的通用方法。
- 論文連結:https://arxiv.org/pdf/2210.11416.pdf
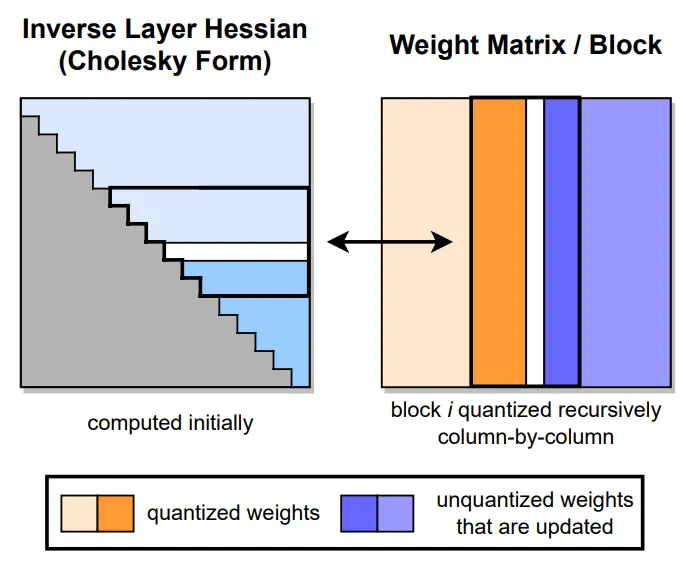
47. GPTQ
- 論文名稱:GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
- 發布時間:2022/10/31
- 發布單位:奧地利科技學院、蘇黎世聯邦理工學院
- 簡單摘要:把GPT quantize到2 bit還可以表現不錯的方法
- 閱讀重點:arbitrary order insigh、lazy batch-updates、Cholesky reformulation、extreme quantization
- 中文摘要:這篇論文探討了「生成式預訓練transformer模型」,也就是GPT或OPT模型,這些模型在處理複雜的語言模型任務方面表現出色,但同時也面臨著極高的計算和存儲成本。由於模型體積龐大,即使對於大型、高準確度的GPT模型進行推理也可能需要多個高性能的GPU,這限制了這些模型的可用性。儘管近期出現了針對模型壓縮的工作,但現有的壓縮技術在應用和性能方面受到GPT模型規模和複雜性的限制。所以本文提出了一種新的「GPTQ」方法,基於近似的二階訊息進行一次性的權重量化,讓其具有高準確性和高效率。具體而言,GPTQ可以在大約四個GPU小時內量化具有1750億參數的GPT模型,將位寬降低到每個權重3或4位元,相對於未壓縮基準模型幾乎沒有精度下降。我們的方法相對於先前提出的一次性量化方法,壓縮效果提升了一倍以上,另外其保持了準確性,使我們首次能夠在單個GPU內進行1750億參數模型的生成推理。此外我們還發現我們的方法在極端量化情況下仍能提供合理的精度,即將權重量化到2位元甚至三元量化水平。實驗表明,這些改進可以利用高端GPU(NVIDIA A100)獲得約3.25倍的端對端推理加速,使用成本更低的GPU(NVIDIA A6000)則可達到約4.5倍的加速。
- 論文連結:https://arxiv.org/pdf/2210.17323.pdf
48. SmoothQuant
- 論文名稱:SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models
- 發布時間:2022/11/18
- 發布單位:麻省理工、Nvidia
- 簡單摘要:免訓練的通用8-bit post-training quantization
- 閱讀重點:activations to weights的困難點、Transformer上的應用
- 中文摘要:這項研究針對大型語言模型(LLMs)展現出優異表現,但需要大量計算和記憶體資源的問題提出了解決方案。量化可以減少記憶體使用並加速推論速度。然而現有的方法無法同時保持精度和硬體效能。所以我們提出了SmoothQuant,一種無需訓練、保持精度且通用的後訓練量化(PTQ)解決方案,其可實現對LLMs的8位權重和8位激勵(W8A8)量化。基於權重易於量化而激勵難以量化的事實,SmoothQuant通過數學等效轉換,將激勵值中的極端值平滑處理,將量化困難度從激勵轉移到權重上。另外SmoothQuant可對LLMs中的所有矩陣乘法進行INT8權重和激勵的量化,包括OPT、BLOOM、GLM、MT-NLG和LLaMA等模型。最後我們展示了高達1.56倍的加速和2倍的記憶體減少,同時精度幾乎無損。SmoothQuant使得能在單個節點上運行530B的LLM。這項工作提供了一個簡便解決方案,可降低硬體成本並普及化LLMs。
- 論文連結:https://arxiv.org/pdf/2211.10438.pdf
49. Toolformer
- 論文名稱:Toolformer: Language Models Can Teach Themselves to Use Tools
- 發布時間:2023/02/09
- 發布單位:Facebook(Meta)、龐培法布拉大學
- 簡單摘要:會使用外部工具的LLM
- 閱讀重點:sampling API calls、executing API calls、filtering API calls、annotation with self-supervised learning
- 中文摘要:這份研究探討語言模型(LMs)在解決新任務時展現出的驚人能力,僅需少量範例或文本指令即可,並尤其在大規模下表現卓越。然而相反地,它們在基本功能上表現出困難,例如算術或事實查詢,這些功能在更簡單、更小型的模型中表現出色。所以在這篇論文中,我們展示了語言模型可以通過簡單的API,自我學習使用外部工具,實現兩者之間的最佳結合。我們引入了Toolformer,這是一個訓練過的模型,能夠決定調用哪些API、何時調用它們、傳遞什麼參數,以及如何最佳地將結果整合到未來的標記預測中。這是通過自我監督的方式完成的,每個API僅需少量範例即可。我們包含了一系列工具,包括計算機、問答系統、兩種不同的搜索引擎、翻譯系統和日曆。Toolformer在各種下游任務中取得了顯著提升的零樣本性能,通常與更大的模型競爭力相當,同時也不損害其核心語言模型能力。
- 論文連結:https://arxiv.org/pdf/2302.04761.pdf
50. LLaMA
- 論文名稱:LLaMA: Open and Efficient Foundation Language Models
- 發布時間:2023/02/27
- 發布單位:Facebook(Meta)
- 簡單摘要:最有名的開源LLM第一代
- 閱讀重點:pre-training data、architecture、efficient implementation
- 中文摘要:我們推出了LLaMA,這是一系列參數從7B到65B的基礎語言模型。我們使用公開可用的數據集訓練這些模型,並展示了可以在僅使用公開數據集的情況下訓練出最先進的模型,無需使用專有或無法取得的數據集。特別是LLaMA-13B在大多數基準測試中優於GPT-3(175B),而LLaMA-65B與最佳模型Chinchilla-70B和PaLM-540B競爭力相當。我們將所有模型釋出給研究社群使用。
- 論文連結:https://arxiv.org/pdf/2302.13971.pdf
51. GPT-4
- 論文名稱:GPT-4 Technical Report
- 發布時間:2023/05/15
- 發布單位:OpenAI
- 簡單摘要:目前世界上最強的LLM
- 閱讀重點:scaling、capabilities、limitations、risks & mitigations
- 中文摘要:我們開發了GPT-4,這是一個大規模、多模態模型,能夠接受圖像和文字輸入並生成文字輸出。雖然在許多現實情境中比不上人類的能力,但在各種專業和學術基準測試中,GPT-4表現出與人類相當的水平,包括在模擬的律師考試中取得了排名前10%左右的成績。GPT-4是一個基於Transformer的模型,預先訓練來預測文件中的下一個標記。後訓練對齊流程改進了模型的事實性和符合期望行為的表現。這個項目的核心部分是開發了在各種規模下都表現穩定的基礎設施和優化方法。這使我們能夠根據使用不到GPT-4 1/1,000的計算資源所訓練的模型,準確預測GPT-4的某些性能方面。
- 論文連結:https://arxiv.org/pdf/2303.08774.pdf
52. PaLM 2 Technical Report
- 論文名稱:PaLM 2 Technical Report
- 發布時間:2022/05/17
- 發布單位:Google
- 簡單摘要:PaLM第二代
- 閱讀重點:scaling laws、evaluation
- 中文摘要:我們推出了PaLM 2,這是一個全新的頂尖語言模型,具有更好的多語言和推理能力,並且比其前身PaLM更節省計算資源。PaLM 2是一個基於Transformer的模型,使用混合目標進行訓練。通過對英語和多語言的語言評估以及推理任務的廣泛評估,我們展示了PaLM 2在不同模型尺寸下,在後續任務上品質有顯著提高,同時相比PaLM表現出更快速和高效的推理。這種提高的效率使得模型更廣泛地應用,同時也能更快速地回應,讓互動更自然。PaLM 2展示了強大的推理能力,在BIG-Bench和其他推理任務上相比PaLM有顯著的提升。PaLM 2在一系列負責任的人工智慧評估中表現穩定,並且在推理時能夠控制惡意訊息,而無需額外負擔或影響其他功能。總體而言PaLM 2在各種任務和能力方面都達到了頂尖水平。在討論PaLM 2系列時,需要區分預訓練模型(各種大小),這些模型的微調變體,以及使用這些模型的用戶產品。特別是,用戶產品通常包括額外的前置和後置處理步驟。此外基礎模型可能隨著時間演變。因此不能期望用戶產品的表現完全與本報告中報告的結果相匹配。
- 論文連結:https://arxiv.org/pdf/2305.10403.pdf
53. Tree of Thoughts
- 論文名稱:Tree of Thoughts: Deliberate Problem Solving with Large Language Models
- 發布時間:2023/05/17
- 發布單位:DeepMind、普林斯頓大學
- 簡單摘要:以tree資料結構來做CoT
- 閱讀重點:thought decomposition、thought generator、state evaluator、BFS和DFS
- 中文摘要:我們發現語言模型在解決問題時有所限制,特別是在需要探索、策略規劃或者一開始的決策就相當重要的任務上。為了克服這些挑戰,我們引入了一個新的框架,名為「思維樹」(ToT),它擴展了思維鏈的方法,讓語言模型能夠在推理時更有彈性。ToT允許語言模型在問題解決過程中,通過考慮多個不同的推理路徑和自我評估選擇來進行有意識的決策,進而做出更有效的全局選擇。我們的實驗顯示,ToT在需要非平凡計劃或搜索的三個新任務上顯著增強了語言模型的問題解決能力:24點遊戲、創意寫作和小型填字遊戲。例如在24點遊戲中,雖然只有使用思維鏈提示的GPT-4解決了4%的任務,但我們的方法成功率達到了74%。
- 論文連結:https://arxiv.org/pdf/2305.10601.pdf
54. QLoRA
- 論文名稱:QLoRA: Efficient Finetuning of Quantized LLMs
- 發布時間:2023/05/23
- 發布單位:華盛頓大學
- 簡單摘要:quantization+Lora讓我一張顯卡就可fine-tune LLM
- 閱讀重點:4-bit NormalFloat、double quantization、paged optimizers
- 中文摘要:我們提出了QLoRA,一種有效的微調方法,可以減少記憶體使用量,讓一個65B參數的模型在一個48GB的GPU上進行微調,同時保持完整的16位微調任務性能。QLoRA通過一種稱為Low Rank Adapters(LoRA)的方法,將梯度反向傳播到凍結的4位量化預訓練語言模型。我們最佳的模型家族名為Guanaco,在Vicuna基準測試中表現優於以往所有公開發布的模型,並僅需在單個GPU上進行24小時的微調即可達到ChatGPT 99.3%的性能水平。QLoRA引入了幾項創新,以節省記憶體而不影響性能:(a)4位NormalFloat(NF4),這是一種對於正常分佈權重的訓息理論最優的新數據類型;(b)雙重量化,通過量化量化常數來減少平均記憶體占用;(c)分頁優化器,管理記憶體峰值。我們使用QLoRA對1000多個模型進行微調,提供了對8個指令數據集、多種模型類型(LLaMA、T5)以及使用常規微調不可行的模型規模(例如33B和65B參數模型)的指令遵從和聊天機器人性能的詳細分析。我們的結果表明,QLoRA在一個小而高品質的數據集上進行微調,即使使用的模型比以前的模型更小,可以達到最新技術水準的性能。除此之外我們提供了基於人類和GPT-4評估的聊天機器人性能的詳細分析,並顯示GPT-4評估是一種便宜且合理的替代方法。此外我們發現當前的聊天機器人基準測試不能準確評估聊天機器人的性能水平。通過某些方面的分析,我們展示了Guanaco相對於ChatGPT的不足之處。最後我們釋出了所有模型和程式碼,包括4位訓練的CUDA核心。
- 論文連結:https://arxiv.org/pdf/2305.14314.pdf
55. Direct Preference Optimization (DPO)
- 論文名稱:Direct Preference Optimization: Your Language Model is Secretly a Reward Model
- 發布時間:2023/05/29
- 發布單位:史丹佛大學
- 簡單摘要:不用強化學習,也可以讓LLM社會化
- 閱讀重點:SFT phase、reward modelling phase、RL fine-tuning phase、deriving the DPO objective、theoretical analysis
- 中文摘要:這篇論文討論了大規模無監督語言模型(LMs),它們學習了廣泛的世界知識和一些推理技能,但由於完全無監督的訓練方式,要精確控制它們的行為很困難。現有的方法通過收集人類對模型生成的相對品質的標註,並將無監督LM進行微調以符合這些偏好,通常使用來自人類反饋的強化學習(RLHF)。但是RLHF是一個複雜且不穩定的過程,首先擬合一個反映人類偏好的獎勵模型,然後使用強化學習微調大型無監督LM以最大化這個估計的獎勵,同時不能遠離原始模型太遠。所以在本文中,我們提出了一種新的RLHF獎勵模型參數化方法,使我們能夠以閉合形式提取相應的最優策略,僅使用簡單的分類損失函數便能解決標準的RLHF問題。這種名為Direct Preference Optimization(DPO)的演算法穩定、高效且計算輕便,無需在微調期間對LM進行抽樣或進行重大超參數調整。我們的實驗顯示,DPO能夠優於或與現有方法一樣微調LM以符合人類偏好。特別是在控制生成物情緒方面,DPO微調優於基於PPO的RLHF,在摘要和單輪對話的回應品質方面與之相當或更好,同時實現了訓練的簡化。
- 論文連結:https://arxiv.org/pdf/2305.18290.pdf
56. Verify Step by Step
- 論文名稱:Let’s Verify Step by Step
- 發布時間:2022/05/31
- 發布單位:OpenAI
- 簡單摘要:透過監督LLM的每一步,讓LLM數學推理邏輯更強
- 閱讀重點:outcome-supervised reward models、process-supervised reward models、active learning用在PRM
- 中文摘要:近年來大型語言模型在進行複雜的多步推理方面取得了很大進步。然而即使是最先進的模型仍然經常產生邏輯錯誤。為了訓練更可靠的模型,我們可以採用結果監督或過程監督。結果監督提供對最終結果的反饋,而過程監督則提供對每個中間推理步驟的反饋。考慮到訓練可靠模型的重要性,以及人類反饋的高成本,仔細比較這兩種方法是很重要的。近期的研究已開始進行此比較,但仍有許多問題待解決。我們進行了自己的調查,發現過程監督在訓練模型解決來自具有挑戰性的MATH數據集的問題時,顯著優於結果監督。我們的過程監督模型能解決 MATH 測試集中代表性子集中 78% 的問題。此外我們展示了主動學習顯著提高了過程監督的效果。為了支持相關研究,我們還釋出了 PRM800K 數據集,其中包含了 80 萬個步驟級別的人類反饋標籤,用於訓練我們最佳的獎勵模型。
- 論文連結:https://arxiv.org/pdf/2305.20050.pdf
57. Phi-1
- 論文名稱:Textbooks Are All You Need
- 發布時間:2023/06/20
- 發布單位:Microsoft
- 簡單摘要:高品質的小數據勝過大數據和大模型
- 閱讀重點:importance of high-quality data、用transformer過濾datasets、synthetic textbook-quality datasets、data pruning
- 中文摘要:我們推出了 phi-1,一款針對程式碼的新型大型語言模型,規模遠小於競爭對手的模型:phi-1是一個基於 Transformer 的模型,擁有 13 億參數,在 8 個 A100 GPU 上訓練了 4 天,使用了來自網絡“教科書級別”的資料(60億標記)和使用 GPT-3.5 合成生成的教科書和練習題(10億標記)。儘管規模小,phi-1 在 HumanEval 上達到了 50.6% 的 pass@1 準確率,以及 MBPP 上的 55.5%。與 phi-1-base 相比(我們在編程練習數據集上進行微調之前的模型),phi-1 也展現了令人驚訝的新特性,以及與 phi-1-small(另一個具有 3.5 億參數的較小模型)相比的性能,後者在 HumanEval 上仍然達到了 45%。
- 論文連結:https://arxiv.org/pdf/2306.11644.pdf
58. LLaMA 2
- 論文名稱:Llama 2: Open Foundation and Fine-Tuned Chat Models
- 發布時間:2023/07/18
- 發布單位:Facebook(Meta)
- 簡單摘要:開源LLM第二代,可以和人對話了
- 閱讀重點:pretraining、supervised fine-tuning、RLHF、system message for multi-turn consistency、learnings and observations
- 中文摘要:這份研究中,我們開發並釋出了 Llama 2,一系列預訓練和微調的大型語言模型(LLMs),規模從 70 億到 700 億參數不等。我們的微調模型 Llama 2-Chat 針對對話場景進行了優化。在我們測試的大多數基準測試中,我們的模型優於開源對話模型,根據我們的人工評估,在幫助性和安全性方面,它們可能是閉源模型的合適替代品。最後我們提供了對 Llama 2-Chat 的微調和安全性改進的詳細描述,以便社群能夠建立在我們工作基礎上並促進LLMs的負責任發展。
- 論文連結:https://arxiv.org/pdf/2307.09288.pdf
59. Code Llama
- 論文名稱:Code Llama: Open Foundation Models for Code
- 發布時間:2023/08/24
- 發布單位:Facebook(Meta)
- 簡單摘要:會寫程式的開源LLM
- 閱讀重點:infilling、long context fine-tuning、instruction fine-tuning
- 中文摘要:我們釋出 Code Llama,這是基於 Llama 2 的一系列大型程式碼語言模型,具有開源模型中最頂尖的表現,包括填充能力、支援大型輸入內容,以及在程式設計任務中具有零樣本指令追蹤的能力。我們提供多個版本以涵蓋廣泛的應用:基礎模型(Code Llama)、Python 特化模型(Code Llama — Python)和指令追蹤模型(Code Llama — Instruct),分別擁有 7B、13B 和 34B 參數。所有模型訓練的序列長度為 16k tokens,並可改善長達 100k tokens 的輸入。7B 和 13B 的 Code Llama 和 Code Llama — Instruct 可根據周圍內容進行填充。Code Llama 在多個程式碼基準測試中達到了開源模型的最頂尖表現,分別在 HumanEval 和 MBPP 上得分高達 53% 和 55%。值得注意的是,Code Llama — Python 7B 在 HumanEval 和 MBPP 上優於 Llama 2 70B,而我們的所有模型也優於其他公開可用模型中的每一個,特別是在 MultiPL-E 上。我們以開放授權釋出 Code Llama,可用於研究和商業用途。
- 論文連結:https://arxiv.org/pdf/2308.12950.pdf
60. RLAIF
- 論文名稱:RLAIF: Scaling Reinforcement Learning from Human Feedback with AI Feedback
- 發布時間:2023/08/24
- 發布單位:Google
- 簡單摘要:讓社會化的LLM來社會化LLM
- 閱讀重點:preference labeling with LLMs、addressing position bias、distilled RLAIF、direct RLAIF、evaluation
- 中文摘要:強化學習從人類反饋中學習(RLHF)已被證明能有效讓大型語言模型(LLMs)與人類偏好保持一致。然而收集高品質的人類偏好標籤可能耗時且昂貴。前人所提出的AI反饋強化學習(RLAIF)提供了一種有希望的替代方案,它利用強大的現成LLM來生成偏好,取代了人類標註者。在摘要、有幫助的對話生成和無害對話生成等任務中,RLAIF獲得了與RLHF相當或更優的表現。此外在另一個實驗中,直接向LLM提供獎勵分數的提示方法,即使LLM偏好標註生成器與策略大小相同,也能比典型的RLAIF設置獲得更好的表現。最後我們對生成符合AI偏好的技術進行了廣泛研究。我們的結果表明,RLAIF能達到人類水平的性能,為克服RLHF的擴展性限制提供了潛在解決方案。
- 論文連結:https://arxiv.org/pdf/2309.00267.pdf
61. OPRO
- 論文名稱:Large Language Models as Optimizers
- 發布時間:2023/09/07
- 發布單位:DeepMind
- 簡單摘要:讓LLM自己來優化prompt吧
- 閱讀重點:natural language descriptions.、meta-prompt、exploration-exploitation trade-off、limitations
- 中文摘要:優化無所不在。雖然基於衍生的演算法在許多問題中效果很好,但應用於真實世界的挑戰在於缺乏梯度資訊。所以在這篇論文中,我們提出了「提示優化」(OPRO),這是一種善用大型語言模型(LLMs)作為優化器的簡單而有效方法,其中優化任務是以自然語言描述。在每個優化步驟中,LLM根據先前生成的解答和其值的提示生成新的解答,然後將新的解答評估並添加到提示中,供下一個優化步驟使用。我們首先展示了在線性回歸和旅行商問題上的OPRO效果,然後轉向提示優化,目標是找到最大化任務準確性的指令。通過多種LLMs,我們展示了OPRO優化的最佳提示在GSM8K上比人工設計的提示提高了多達8%,在Big-Bench Hard任務上提高了多達50%。
- 論文連結:https://arxiv.org/pdf/2309.03409.pdf
62. vLLM
- 論文名稱:Efficient Memory Management for Large Language Model Serving with PagedAttention
- 發布時間:2023/09/12
- 發布單位:加州大學柏克萊分校、史丹佛大學、加州大學聖地亞哥分校
- 簡單摘要:用虛擬記憶體和paging技術加速LLM運算
- 閱讀重點:memory challenges in LLM、PagedAttention、KV cache manager、decoding、distributed execution
- 中文摘要:將大型語言模型(LLMs)進行高吞吐服務需要一次處理足夠多的請求。然而現有系統存在問題,因為每個請求所需的鍵值緩存(KV緩存)記憶體龐大且動態增減。管理不當時,這種記憶體可能會因碎片化和重複而大量浪費,限制了批處理大小。為解決此問題,我們提出了PagedAttention,一種受到作業系統中經典虛擬記憶體和分頁技術啟發的注意力演算法。基於此演算法,我們構建了vLLM,一個LLM服務系統,實現了(1)KV緩存記憶體幾乎沒有浪費,以及(2)在請求內外靈活共享KV緩存,進一步減少記憶體使用。我們的評估顯示,與FasterTransformer和Orca等最新系統相比,vLLM可以將熱門LLMs的吞吐量提高2–4倍,並保持相同的延遲水平。對於更長的序列、更大的模型和更複雜的解碼演算法,改進效果更為顯著。
- 論文連結:https://arxiv.org/pdf/2309.06180.pdf
63. Mamba
- 論文名稱:Mamba: Linear-Time Sequence Modeling with Selective State Spaces
- 發布時間:2023/12/01
- 發布單位:卡內基麥隆大學、普林斯頓大學
- 簡單摘要:超越Transformer,基於state space models的新架構
- 閱讀重點:state space models、selective state space models、evaluation
- 中文摘要:我們的基礎模型大多採用Transformer架構及其核心的注意力模組,支持了許多深度學習的應用。為了解決Transformer在處理長序列時的計算效率問題,開發了許多次線性時間的架構,例如線性注意力、閘控卷積和循環模型以及結構化狀態空間模型(SSM)。然而它們在語言等重要模式上的表現不及注意力模型。我們發現這些模型的一個關鍵弱點在於它們無法進行基於內容的推理,並做了一些改進。首先我們將SSM參數設置為輸入的函數可以解決其在離散模式下的弱點,使模型能夠根據當前標註選擇性地在序列長度維度上傳播或遺忘訊息。接下來即使這種改變阻止了有效卷積的使用,我們設計了一種硬體感知的平行運算演算法。我們將這些選擇性的SSM整合到一個簡化的端到端神經網絡架構中,不使用注意力甚至MLP模組,讓Mamba具有快速的推斷速度(比Transformer高出5倍),在序列長度上線性擴展,並在現實數據上表現提高,可處理長達百萬長度的序列。作為通用的序列模型基礎,Mamba在語言、音頻和基因組等多種模式上均達到了最先進的性能。在語言模型方面,我們的Mamba-3B模型,無論是在預訓練還是下游評估中。優於相同大小的Transformer模型,並與比其兩倍大小的Transformer模型相匹配。
- 論文連結:https://arxiv.org/ftp/arxiv/papers/2312/2312.00752.pdf
64. ReST-EM
- 論文名稱:Beyond Human Data: Scaling Self-Training for Problem-Solving with Language Models
- 發布時間:2023/12/12
- 發布單位:DeepMind
- 簡單摘要:用LLM產生資料來訓練LLM
- 閱讀重點:expectation-maximization for RL、reinforced self-training、ablation studies、reasoning capabilities
- 中文摘要:透過人類生成的數據對語言模型進行微調一直是一種常見的做法。然而這些模型的性能往往受到高品質人類數據的數量和多樣性的限制。本文探討在我們可以獲得標量反饋的任務中是否能超越人類數據,例如在可以驗證正確性的數學問題上。為此我們研究了一種基於期望最大化的簡單自我訓練方法,稱為ReST-EM:(1)從模型生成樣本並使用二元反饋過濾它們,(2)在這些樣本上對模型進行微調,(3)重複這個過程幾次。在使用PaLM-2模型進行高級數學推理和程式碼基準測試時,我們發現ReST-EM隨著模型尺寸的增加表現出優勢,明顯超越僅使用人類數據進行微調。整體而言,我們的研究結果表明,通過反饋的自我訓練能夠顯著減少對人類生成數據的依賴。
- 論文連結:https://arxiv.org/pdf/2312.06585.pdf
65. Superalignment
- 論文名稱:Weak-to-Strong Generalization: Eliciting Strong Capabilities with Weak Supervision
- 發布時間:2023/12/14
- 發布單位:OpenAI
- 簡單摘要:要人類能監督超級AI,先從小LLM監督大LLM開始
- 閱讀重點:strong student model with weak supervision、 ground truth labels as a ceiling、performance gap recovered、limitations
- 中文摘要:廣泛使用的對齊技術,比如從人類反饋中進行強化學習(RLHF),依賴於人類監督模型行為的能力,例如評估模型是否忠實地遵從指令或生成安全的輸出。但是未來的超級人工智慧模型將表現出複雜的行為,對人類來說難以可靠地評估,對於人類對超級人工智慧模型進行弱監督,我們研究了這個問題的類比:弱模型監督是否能喚起更強大模型的全部能力?我們在自然語言處理、西洋棋和獎勵建模任務上使用了一系列GPT-4系列的預訓練語言模型進行測試。我們發現,當我們用弱模型生成的標註來簡單微調強大的預訓練模型時,它們的表現一直優於弱監督模型,我們稱之為弱到強泛化現象。然而僅僅通過簡單微調,我們仍然離完全發揮強大模型的能力很遠,這表明像RLHF這樣的技術在不進一步研究的情況下可能無法應對超級人工智慧模型的挑戰。我們發現簡單的方法通常能顯著提高弱到強泛化能力:例如當用GPT-2級別的監督模型和輔助的置信損失來微調GPT-4時,我們在NLP任務上可以接近GPT-3.5的性能水準。我們的結果表明,當前在解決對齊超級人工智慧模型方面是有可能取得實際進展的。
- 論文連結:https://cdn.openai.com/papers/weak-to-strong-generalization.pdf
66. FunSearch
- 論文名稱:Mathematical discoveries from program search with large language models
- 發布時間:2023/12/14
- 發布單位:DeepMind
- 簡單摘要:突破人類思維,LLM解決人類無法解的數學問題
- 閱讀重點:prompt、program database、distributed approach、解決extremal combinatorics和bin packing問題、discussion
- 中文摘要:大型語言模型(LLMs)展現出在解決從量化推理到理解自然語言等複雜任務方面的巨大能力。然而LLMs有時會出現混淆(或幻覺)問題,導致它們提出似是而非但不正確的陳述。這阻礙了當前大型模型在科學探索中的應用。所以我們提出了FunSearch(在函數空間中搜索)方法,這是一種基於將預先訓練的LLM與系統性評估器進行配對的進化程序。我們展示了這種方法的有效性,超越了現有LLM方法在重要問題上的最佳結果,拓展了現有基於LLM的方法的範疇。將FunSearch應用於極值組合數學的核心問題 — cap set問題,我們發現了超越已知的最佳結果的大型cap set的新構造,無論是在有限維度還是漸進情況下。這代表了首次使用LLMs解決已知開放問題的發現。另外我們展示了FunSearch的通用性,將其應用於一個演算法問題 — 在線裝箱問題,找到了改進廣泛使用基線的新啟發式方法。與大多數電腦搜索方法不同,FunSearch搜索描述如何解決問題的程序,而不是解決方案。除了是一種有效和可擴展的策略外,發現的程序往往比原始解決方案更易於理解,可以實現領域專家與FunSearch之間的反饋循環,並將這些程序應用於真實世界應用中。
- 論文連結:https://www.nature.com/articles/s41586-023-06924-6
小心得
其實我們可以從這66篇的論文裡面發現,發布這些革命性的論文的機構組織都是那幾個,公司部分像是Google、DeepMind、OpenAI、Meta、Microsoft,學校部分像是Stanford、Berkeley、CMU、Princeton、MIT。這樣的體系就構成了現今三局鼎力的局勢:- Google和DeepMind陣營 — Gemini、Bard
- Microsoft和OpenAI陣營 —ChatGPT、Bing
- Meta開源社群陣營 — Llama
除此之外我們還可以發現一件有趣的事情
- Transformer到BERT/GPT相隔一年左右 → encoder-decoder/seq2seq時代
- BERT/GPT到GPT-3相隔一年半左右 → prompting時代
- GPT-3到FLAN相隔一年三個月左右 → instruction時代
- FLAN到chain-of-thought相隔五個月左右 → CoT時代
- chain-of-thought到ChaGPT發布相隔一年左右 → LLM時代
然後LLM領域就開始大爆發了
- ChaGPT到Llama相隔3個月左右 → 開源LLM百花齊放時代
- Llama到GPT-4相隔3個月左右 → multimodality時代
- GPT-4到RLAIF相隔3個月左右 → LLM自己訓練自己時代
- RLAIF到Superalignment相隔3個月左右 → ASI概念時代?
不僅在NLP領域,Image、Audio、Video、3D都全面爆發,而接下來2024年AI領域又會發展的比2023年來得快更多更多,為什麼呢?因為2023年開始一大票人開始崇尚e/acc (Effective Accelerationism)有效加速主義
所以接下來大家得坐穩了,準備迎接超級人工智慧的到來!
作者:劉智皓





















