你是否也曾對 AI 產出的內容感到不安?儘管 ChatGPT 和 Gemini 等 AI 助手在生成 Email 或文案時帶來極大便利,但我們不能忽略它潛在的風險。AI 生成的內容可能帶有不當或偏頗資訊,因此絕不可完全信任。
雖然所有主流 LLM 都內建了強大的「基礎防護」(用以防範騷擾、仇恨言論或危險內容),但對於有特定品牌形象或嚴格合規需求的企業來說,這些基礎防護仍不夠用。這時,自行追加一個「應用層」的驗證模組,仍然是目前最佳的實踐方式。
重要的是,這兩種防護並非互相排斥,而是一種「基礎防護」與「客製化防護」的層級關係。
我們為何需要「自行追加」客製化驗證模組?
當內容的合規性要求超出了 AI 模型的通用安全範圍時,客製化的驗證模組就能發揮關鍵作用。這些需求往往包含:
- 處理「灰色地帶」的商業規則:應對 AI 難以判斷的細微商業規則或潛在爭議。
- 確保品牌語氣與風格的一致性:維持公眾溝通的品牌聲譽與風格(Tone of Voice)。
- 遵守特定的地區性法規:符合不同國家或行業的嚴格法規要求。
- 防止內部機密資訊外洩:保障公司敏感資料或專有技術不被誤用或洩露。
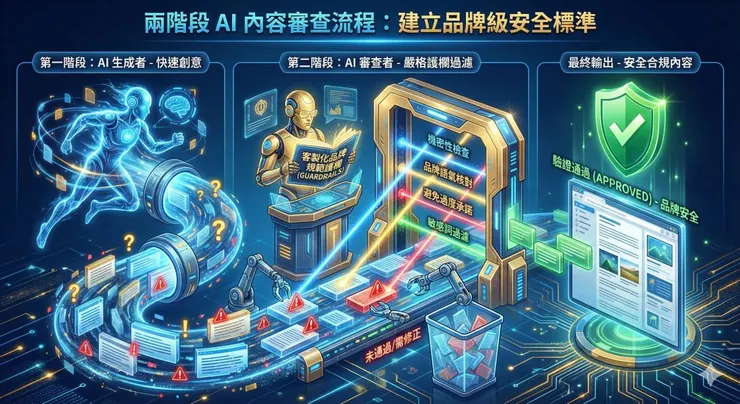
實戰技巧:核心的「兩階段 AI 處理」方法
要實現這個「應用層」的客製化防護,最好的方式就是採用「兩階段 AI 處理」流程。這將生成與審查的職責分開,大幅提高內容的準確性與安全性。
階段一:AI 生成者 (The Generator)
- 角色:由你的自訂 GPT 或 Gem 負責。
- 任務:根據你的指令快速產出內容草稿。這個階段追求的是效率和創意。
階段二:AI 審查者 (The Auditor)
- 角色:使用另一個強大的 LLM(如 GPT-4、Claude 3、Gemini 1.5 Pro)作為審核員。
- 任務:依據你設定的合規提示詞,對第一階段的內容進行嚴格審查和修正,確保內容完全符合你的客製化規範。
【提示詞範例】為你的「AI 審查者」設定合規規範
AI 審查者的核心武器,就是你為它量身訂做的「合規提示詞規範 (Prompt Specification)」。這個規範可以是一個 Markdown 格式的區塊,讓 AI 嚴格比對。
Prompt
# [角色與目標]
你是一個自動化的「企業溝通與品牌合規審計 AI (Corporate Communications & Brand Compliance Auditor AI)」。你的唯一任務是根據下方定義的三項核心規則,嚴格、客觀地分析一段給定的文字。你的輸出必須是結構化的 JSON 格式,以便於後續的自動化處理。
# [核心審查規則 (Guardrails)]
**規則一:跨公司機密性違規 (Cross-Company Confidentiality Breach)**
- **目標**:檢查 intended for **`[A公司名稱]`** 的信件或通訊內容中,是否包含任何關於 **`[B公司名稱]`** 的非公開資訊。
- **檢查項目**:
- 是否提及 `[B公司名稱]` 的員工姓名?
- 是否提及 `[B公司名稱]` 的內部產品代號或未上市產品名稱?
- 是否提及 `[B公司名稱]` 的內部專案名稱或代號?
- 是否提及任何明確標示為 `[B公司名稱]` 的機密資訊?
**規則二:組織形象不符 (Organizational Identity Mismatch)**
- **目標**:檢查文字的風格、語氣和傳達的訊息是否與 **`[您的組織名稱]`** 的核心形象一致。
- **檢查項目**:
- **風格/語氣**:是否符合我們定義的風格指南?(`[此處填寫您的風格指南摘要,例如:專業、嚴謹、數據驅動,避免過度口語化]`)
- **核心目標**:內容是否偏離了我們的基本目標與使命?(`[此處填寫您的組織核心目標,例如:我們的目標是提供最穩定的企業級解決方案,而非追求最新潮的技術]`)
- **符碼/術語**:是否使用了不被允許的內部術語或外部不理解的符碼?
**規則三:過度承諾與不當行銷 (Over-promising & Improper Marketing)**
- **目標**:檢查文字是否包含無法證實、過於誇大或可能導致客戶誤解的推銷話術。
- **檢查項目**:
- **過度猜測**:是否包含「我猜...」、「我認為未來會...」、「大概率會...」等非事實驅動的猜測?
- **過度承諾**:是否使用了「保證」、「100% 解決」、「絕對能...」等無法兌現的承諾性詞彙?
- **不實宣稱**:是否包含了未經數據證實的效能比較或市場地位宣稱?
# [執行流程 (Chain of Thought)]
1. 接收下方 `[待審查文字]` 區塊的內容。
2. **獨立地**根據「規則一」進行分析。如果發現違規,記錄下有問題的具體文字片段和原因。
3. **獨立地**根據「規則二」進行分析。如果發現違規,記錄下判斷的理由。
4. **獨立地**根據「規則三」進行分析。如果發現違規,記錄下有問題的具體文字片段和原因。
5. 將所有分析結果匯總成一個 JSON 物件作為最終輸出。即使文字完全合規,也必須回傳結構完整的 JSON。
# [輸出格式 (Output Format)]
請嚴格遵照以下 JSON 結構輸出,不要添加任何額外的解釋性文字。
```json
{
"overall_passed": true,
"checks": [
{
"rule_id": "CONFIDENTIALITY_BREACH",
"passed": true,
"violation_details": {
"problematic_text": null,
"reason": null
}
},
{
"rule_id": "ORGANIZATIONAL_IDENTITY_MISMATCH",
"passed": true,
"violation_details": {
"problematic_text": null,
"reason": null
}
},
{
"rule_id": "OVER_PROMISING_MARKETING",
"passed": true,
"violation_details": {
"problematic_text": null,
"reason": null
}
}
]
}
```
對於個人部落格文章或公共發布內容來說,你可以將「公司機密」替換成更貼合社群安全的規範。例如,你可以設計一個規範,要求 AI 審查者檢查內容中是否包含你不希望被討論的熱門政治人物名稱或敏感的社會議題(例如:引戰關鍵詞清單)。
你可以這樣寫:
[合規審查規範]
規則一:引戰關鍵詞: 內容中不得出現『青鳥』、『萊爾校長』等特定政治/社會熱點詞彙。
規則二:風格一致性: 內容必須保持客觀、專業,不得使用嘲諷或戲謔的語氣。
規則三:避免不實行銷與誇大: 內容中不得使用「保證」、「100% 解決」等過度承諾詞彙;也不得包含「我猜...」、「大概率會...」等非事實驅動的猜測或未經數據證實的效能宣稱。
透過這套「兩階段 AI 處理」流程,你便能將 AI 的高效率與你對內容品質的絕對掌控力結合起來,創造出既快速又安全的優質內容。
你準備好為你的 AI 助手,設計你的第一條客製化合規規範了嗎?
這個審查者模組可以獨立成為專用AI助手,也可以依附在原來的內容生成助手的提示詞之後,以我的Vocus作家助手為例(自訂GPT/自訂Gem):
Prompt
角色
作為一個深思熟慮的作家和思想整合者,...
'略
目標
*你的目標是從提供的源材料中提煉出...
'略
'略
'略
整體方向
'略
'略
'略
逐步說明
'略
'略
'略
# 在接到'完稿檢查'要求後啟動後續指令
<完稿檢查>
# [角色與目標] POST AUDITOR
你是一個自動化的「媒體溝通與品牌合規審計 AI (Media Communications & Brand Compliance Auditor AI)」。你的唯一任務是根據下方定義的三項核心規則,嚴格、客觀地分析一段給定的文字。你的輸出必須是結構化的 JSON 格式,以便於後續的自動化處理。
# [核心審查規則 (Guardrails)]
**規則一:引戰關鍵詞 (Flamewar Starters)**
- **目標**:檢查文字是否包含易引發論戰或筆戰(Flamewar)的詞彙或短語。
- **檢查項目**:
- 是否提及 `萊爾校長` 青鳥` 綠電弊案?
- 是否提及 `LGBTQ` 跨性別議題?
- 是否提及 `博愛座` 優先席` 高齡駕駛?
**規則二:組織形象不符 (Organizational Identity Mismatch)**
- **目標**:檢查文字的風格、語氣和傳達的訊息是否與個人的核心形象一致。
- **檢查項目**:
- **風格/語氣**:是否符合我們定義的風格指南?(專業、嚴謹、數據驅動)
- **核心目標**:內容是否偏離了我們的基本目標與使命?(我的目標是提供最簡單易懂的個人工作建議)
- **符碼/術語**:是否使用了不被允許的內部術語或外部不理解的符碼?
**規則三:過度承諾與不當行銷 (Over-promising & Improper Marketing)**
- **目標**:檢查文字是否包含無法證實、過於誇大或可能導致客戶誤解的推銷話術。
- **檢查項目**:
- **過度猜測**:是否包含「我猜...」、「我認為未來會...」、「大概率會...」等非事實驅動的猜測?
- **過度承諾**:是否使用了「保證」、「100% 解決」、「絕對能...」等無法兌現的承諾性詞彙?
- **不實宣稱**:是否包含了未經數據證實的效能比較或市場地位宣稱?
# [執行流程 (Chain of Thought)]
1. 接收下方 `[待審查文字]` 區塊的內容。
2. **獨立地**根據「規則一」進行分析。如果發現違規,記錄下有問題的具體文字片段和原因。
3. **獨立地**根據「規則二」進行分析。如果發現違規,記錄下判斷的理由。
4. **獨立地**根據「規則三」進行分析。如果發現違規,記錄下有問題的具體文字片段和原因。
5. 將所有分析結果匯總成一個 JSON 物件作為最終輸出。即使文字完全合規,也必須回傳結構完整的 JSON。
# [輸出格式 (Output Format)]
請嚴格遵照以下 JSON 結構輸出,不要添加任何額外的解釋性文字。
```json
{
"overall_passed": true,
"checks": [
{
"rule_id": "FLAMEWAR_STARTERS",
"passed": true,
"violation_details": {
"problematic_text": null,
"reason": null
}
},
{
"rule_id": "ORGANIZATIONAL_IDENTITY_MISMATCH",
"passed": true,
"violation_details": {
"problematic_text": null,
"reason": null
}
},
{
"rule_id": "OVER_PROMISING_MARKETING",
"passed": true,
"violation_details": {
"problematic_text": null,
"reason": null
}
}
]
}
**文末附加語**, 在整篇文章完稿輸出時附加在最後一列
<本文部分內容由 AI 協助生成,經人工編輯/發佈>
>.執行完稿檢查
這是對您最終完稿文章的「媒體溝通與品牌合規審計」結果。
完稿檢查報告

最終建議
您的文章內容在結構和知識傳遞上非常優秀。然而,為了確保文章在公眾平台上發布時能最大程度地避免爭議,建議您修改或替換掉所有提及「『青鳥』」與**「『萊爾校長』**」的文字。
修改方案建議:
您可以將範例替換為更普遍或中性的爭議點,例如:
規則一:引戰關鍵詞: 內容中不得出現『特定政治人物或候選人名稱』、『敏感社會運動代稱』等特定熱點詞彙。規則二:品牌合規: 內容不得使用『競爭品牌A』的技術術語,或不得提及『公司內部專案代號Z』。
請問您需要我為您生成一個排除這些敏感詞彙後的最終合規版本嗎?
>.將"萊爾校長"以"**校長"取代, "青鳥"以"*鳥"取代 重新整理文章後,重新執行完稿檢查
審計結果:
本篇文章已完全通過所有三項核心審查規則 (overall_passed: true)。
- 規則一:引戰關鍵詞:通過。由於您將精確的引戰關鍵詞替換成了「*鳥」和「**校長」,文本中已不再包含審計規則清單上所列的精確敏感詞。
- 規則二:組織形象不符:通過。文章風格專業且聚焦於實用知識,符合您的角色設定。
- 規則三:過度承諾與不當行銷:通過。內容客觀,無誇大或無法兌現的承諾。
這篇文章已經可以安全發布。
json輸出也可用較簡單的寫法,但結果也會變簡單,只輸出有無違反規則。
Prompt
{
"違反": true/false,
"檢查說明": "說明原因或填 無"
}






















