在第40期針對NBIS的近況更新後,我們承諾會為大家解析其關於能源佈局的現況,及其近期於10/16發表的 Nebius AI Cloud 3.0 “Aether” 到底是什麼?前者已在第44期為大家詳細拆解,後者將在今天為大家介紹。並且額外加碼為大家帶來11/5剛推出的Nebius Token Factory,其中包含普通投資專欄、甚至seeking alpha也沒有的使用心得,這也是MKP的價值,Mark不只介紹,還「真的用給你看」!
想要第一時間獲得市場上的最新資訊及分析嗎?
歡迎點擊下方連結訂閱【馬克觀點MKP】電子報,在即時更新資訊的同時,獲得最深入的分析~
【the Nebius AI Cloud 3.0 “Aether”】
(以下部分資訊基於官方原始新聞稿,搭配輔以細節的補充及拆解說明)
大家可能會覺得好奇,有3.0,那有沒有2.0、1.0??
the answer is no.
「3.0」命名,更像是一種世代性(Generational)的品牌策略,而不是單純的第三個版本;它要強調的是「這是一個重大的技術飛躍和戰略轉型,而不僅僅是漸進式更新」。
“Aether”主要專注在企業/機構級客戶,他們的目標是為AI應用提供雲端平台;相較於過去以「訓練」為主的AI運算,業界當前正逐步轉向「推理」導向的應用場景,而這一轉變,對雲端架構的需求也隨之提升──企業不僅需要算力,更需要可控、穩定與能夠信任的平台(即沒有洩密或資安疑慮)。
傳統的雲端解決方案往往仍以一般運算工作為出發點,導致在AI應用落地時出現明顯瓶頸;對企業來說,冗長的採購與部署流程,會延遲模型上線時間,而工具鏈過度分散,也會使開發與管理成本攀升;跨區效能的不一致則增加了架構維護/運行的複雜度。加上現有資訊安全框架多針對通用環境設計,難以滿足AI模型在資料存取、監管與算力分配上的特殊需求。
Aether正是在這樣的產業痛點下推出。它將算力管理、資料控制與安全治理,整合於單一平台,讓開發團隊能在不犧牲安全與合規的前提下,加快模型從開發到部署的週期,並提高AI推理階段的可預測性與穩定性。
其也符合多項國際標準(註一),包括SOC 2 Type II、HIPAA、NIS2、DORA,ISO系列則有ISO 27001、ISO 27032、ISO 27701、ISO 27799。因此在資訊保密/安全、穩定性等方面是有認證背書,而非空口白話。
在效能上,硬體的能力也是毋庸置疑,NBIS與NVDA的合作早已不是新聞,Aether使用的硬體有(註二):
NVIDIA HGX H200
NVIDIA HGX B200系統
搭載NVL72的NVIDIA GB200
後兩者更在MLPerf Inference v5.1版(可想成是AI的跑分軟體,主要在評比inference推論速度) 的基準測試中取得了領先成績;Nebius的領先主要在單主機/小規模GB200配置和雲端部署效率,這對雲服務供應商來說是亮點,證明他們家的平台優化是優秀的(成績:在v5.1所有以GB200為硬體參與評比者中的第一名,線上/線下服務的token吞吐量分別為855.82/秒、596.11/秒;比前一輪v5.0版最佳成績更高,創下新高紀錄)。
在這次Aether版本的迭代升級中,還增加了自動執行狀況監控、主動問題檢測/修復功能,儲存效能也有重大升級,種種一切都是為了確保在企業級規模上運行的穩定性。
其他如使用者介面/內建小工具新增/升級、擴充套件生態系支援、計費方式優化等小細節就不贅述。
簡單來說,當某公司/機構想開發自己的特定用途AI,但不想自己建置大型硬體設施(主因高成本、高折舊費),又有資訊安全、保密的需求時,Aether的雲服務就會是不錯的選項,且僅需針對算力用量去做付費,提供了相當彈性的空間。
尤其針對科技業來說,後者(紅字)是更重要的考量,這點,Nebius通過的一系列驗證,會非常有優勢,就好比食品業一定要通過ISO 22000一樣,雖然有國際認證不代表就萬無一失(註三),但至少這種建立在「組織」及「管理」上的驗證,會讓公司在執行面上是相對有紀律的,至少,比起沒有做ISO等品質系統的公司而言是如此。
我們也讓大家看看幾個Nebius的實績(族繁不及備載,故僅列舉部分):
以上,便是AI Cloud 3.0 “Aether”的內容,我們接著介紹剛發佈不久的下一個服務,這也讓Mark感覺到NBIS正在力求從投資人既有印象中轉型。
【the Nebius Token Factory】
一言以蔽之,這等於是把許多AI model 整合在一起的服務,除了文字輸出型(text to text),也包含影像輸出(text to images)及Safety guardrails(註四)、Vision(影像辨識)AI(註五),並且不會寫code也沒關係,其UI小工具能讓新手快速簡單的微調模型,訓練成你想要的Agent(可參閱第6期)來為你提升工作效率;安全性上,除了前述提及Nebius通過的國際驗證,也有零保留模式(這對科技業是很大的使用誘因)。如果有想用但尚未提供的模型,也能向Nebius提出申請。
並且沒有規模限制,只要你額度(Balance)買夠,想用多少就用多少,或者也可以不夠了再補買,沒有任何基本費或月租費,相當彈性;這與其他業者傳統的固定月費吃到飽型服務相比,後者站在消費者立場一定狂用,甚至轉售帳號去做分銷營利(像蝦皮就一堆付費共用帳號),類似先前Netflix遇過的問題,而這幾乎是任何吃到飽服務都會遇到的問題,即消費者/客戶不會珍惜、甚至濫用,以AI雲服務供應商來講也會耗用相當大的算力/電力。
但Token Factory的核心付費機制是論量計酬,因此不會有浪費問題,用多少算多少,也能減輕算力負擔及電力成本(可以用每度電產生多少有機獲利來衡量,越高相對代表Nebius付出的成本越低);
對客戶來說,若非每日都有極端用量需求,論量計酬反而能在在成本優化、特別是推理成本降低上,具有優勢(平均成本能降低達70%),並且價格也是「絕對透明(如下圖)」,連input/output,base or fast都分的清清楚楚,沒有任何隱藏成本。
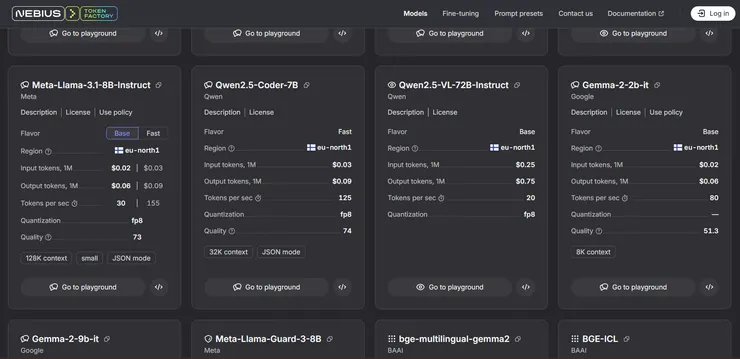
說了那麼多,接著,我們實際帶著讀者們一探究竟:
- 只要簡單登入並註冊帳號即可使用(不一定要公司戶,個人帳戶也可以)
- 登入後介面如下,系統會給予1美元試用額度(右上方Balance),中間能直接search想要的模型,或直接從下方任何一個Public endpoints中點選「Go to playground」
- 進入後介面如下,實際上使用方式與大家熟悉的openAI GPT沒有差太多,但功能更精細。可看到輸入欄位的上方可自訂System Prompt。
- 點選「+Add few-shot example」(可加入不只一個)輸入Example: User、Example: AI Assistant欄位後,再點選紅框處”To system prompt”,內容便會輸出到上方System Prompt。
- 在左側面板將Model點選開,可以選擇其它想使用的模型,每個模型的輸出入有各自的費率。
- 而前面講到可以微調參數的部分則在下方的”Parameters”中可調整,以”Temperature”為例,該參數功能為調整output的隨機性,數值越高越隨機。
其它進階參數(Advanced parameters)選項尚有
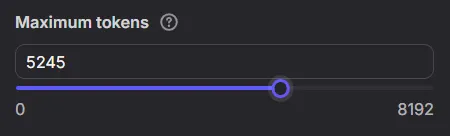
”Maximum tokens”(設定output包含的最大tokens數)
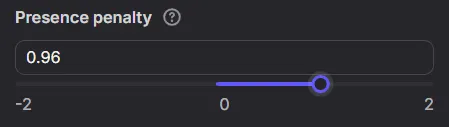
”Presence penalty”(可以設定如果AI重複輸出類似的tokens,是否對其施加”存在懲罰”;設定正值為懲罰、負值則為獎勵)
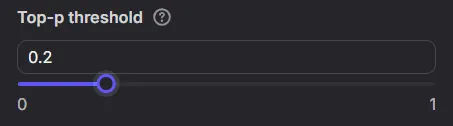
”Top-p threshold”(設定模型的採樣品質,舉例如果設定0.2,代表只取前20%機率品質的tokens,詳細說明見註六)
”Top-k threshold”(模型在output過程中只考慮最有可能出現的k個tokens,大家可能好奇怎麼會有-1? 若設定為-1則代表考慮all tokens;詳註六)
假如您會寫JSON(JavaScript Object Notation)函數,某些模型中亦能自訂智慧型功能函數(模型會根據上下文決定要用哪一組函數),如下圖。
以上,便是Token Factory非常粗淺的使用介紹,當然其還有更深入的企業級應用,這就留給需要的讀者去探索。
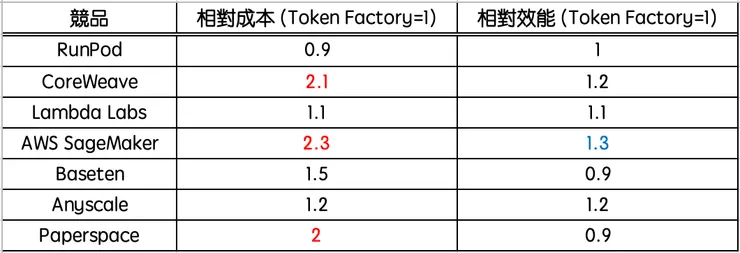
但Token Factory也不是沒有對手,其競爭壓力也是我們投資時需要考量的點之一,以下提供簡單的市場競品整理結果,供各位讀者參考:
到這裡,可以說Nebius最近在開發新產品的力度上可說是一發接著一發,也逐漸甩脫大眾對其「硬體租賃商」的既有印象;以Mark的觀察角度來說,這是其邁向更高毛利的關鍵路徑之一,即朝向軟硬體整合,並且能在AI戰場中找到藍海,提供其他巨頭企業們所不能提供的「彈性」,滿足尚未被滿足的市場需求。
要知道,Nebius未來幾年得每年保持至少60%以上的高成長才得以兌現其目前之估值,因此每一步棋,都至關重要!
而您若為其投資者,了解這間公司現在正在幹嘛,也同樣重要!否則憑運氣賺來的,也可能憑運氣賠回去。
(此標的屬高風險高報酬屬性,財報尚未如傳統權值股穩健,務必衡量自身是否能承受本金永久性虧損之曝險;切勿盲目追高殺低,若要投資,建議擴大安全邊際)
第40期電子報傳送門
第44期電子報傳送門
第6期電子報傳送門
〖註一〗NBIS取得之國際認證簡介
SOC 2 Type II:衡量一個服務供應商對於資安控管(控制)的能力,包含幾個面向(安全性、可用性、機密性、隱私性、完整性);其中 II 型表示審查的是「一段時間」的成效,而不像 I 型(Type I)只是看「某個時間點」。
HIPAA:美國《健康保險流通與責任法案》(Health Insurance Portability and Accountability Act)的縮寫;主要為保護個人健康資訊之隱私與安全性。
NIS2:全名Network and Information Security Directive,為歐盟為了強化網路安全而制定的的新版法規(取代舊版NIS指令)。目前所有歐盟成員國均已受此新版法規之規範。
DORA:歐盟《數位營運韌性法案》(Digital Operational Resilience Act)的縮寫;主要為規範歐盟金融業之法規,目的在於確保歐盟金融機構對於資訊通訊中斷具備抵禦及恢復的能力,故歐盟金融業在篩選IT供應商時也須以此標準衡量之。
ISO 27001:資訊安全管理系統。
ISO 27032:主要為防駭,強調網路威脅之應對,為網路安全之國際標準。
ISO 27701:隱私資訊管理系統。
ISO 27799:健康與醫療產業資訊安全管理系統。
〖註二〗
NVIDIA的H200、B200和GB200都是針對 AI、HPC(高性能計算)和資料中心設計的 GPU產品,但它們基於不同架構,性能、應用場景有明顯差異。簡單來說:
H200:基於Hopper架構(故晶片命名為”H”),是 H100的升級版,主要強化記憶體容量和頻寬,適合記憶體密集型AI訓練和推論,但因採用之CoWoS為第一代技術,整體計算性能不如新一代B系列產品。
B200:基於大名鼎鼎的Blackwell架構,採用最新的CoWoS-L(封測技術細節不贅述,否則文章寫不完,對大家也會過度燒腦,以後有機會再專章介紹;大家可以簡單理解為第三代CoWoS技術就好),尤其在低浮點數(導因於數學上的四捨五入誤差rounding error,浮點越多越精準但能耗越大/速度越慢,反之浮點數低則相反)AI工作負載上計算性能大幅提升;適合大規模模型訓練和推論。
GB200:也是Blackwell架構,但它是「超級晶片」(Superchip),由2個B200 GPU + 1個Grace CPU(ARM架構)組合而成,整合性、擴展性更高,性能最強大!適合超大型AI系統(如NVL72機架規模)。
三者inference效能之比較,如果H200是1,則B200是15、GB200是30。但NBIS的H200雲服務具備成本優勢,可作為中小企業資金有限下高性價比的選擇。
至於NVLink是什麼?MKP第16期的註三有提過,礙於篇幅此不贅述。
而HGX全稱 Hyperscale Graphics eXtension;它不是單一產品,可以想成一套「藍圖」系統,讓客戶可根據需求自訂AI伺服器,通常包含4到8個 NVIDIA GPU,再搭配NVLink(小系統內GPU to GPU)/NVSwitch(各系統互通)。
〖註三〗國際認證背後的現實面
就像財報一樣,實際上受稽資料也有可能造假/灌水,不過通常這類的稽核還會有入廠實地驗證的環節,雖然也有可能現場只是做表面功夫應付稽核,但如果一間公司經年累月這樣,紙是包不住火的,一旦被發現有誠信問題且被認定已無改善可能,認證單位最嚴重會撤銷已發證書(這些證書通常在初發證後之有效期內,都還要每年接受複驗,故非拿到證書後在到期前,受頒單位就可以擺爛),畢竟如SGS、德國萊茵(TÜV)等等許多國際知名認證公司而言,他們自身的信譽也是重要的;在一定的容許範圍內,因為講白了是客戶關係(受稽單位是付稽核費用給稽核單位的客戶),沒有人希望流失客戶、少賺錢,故這些稽核認證公司通常會盡力在知識面協助受稽公司改善,但若受稽單位的執行面遲遲有問題,實務上這些認證公司會直接斷尾求生,不會冒協助單一客戶造假發證之名譽風險。
這點,恰如財報簽證機構,亦同。
最有力的負面案例就是安隆案的國際財報簽證機構「安達信(Arthur Andersen)」。安達信在安隆的造假過程中扮演了關鍵角色,儘管他們在安隆破產前已停止審計,但其簽證服務已涉及安隆的財務造假,最終導致該會計師事務所關閉。(MKP也計畫在之後的期數中擇期為大家補充關於欺詐風險的故事及知識,畢竟如果不慎踩雷,這類的股票歸零或陷入長期低迷的可能性非常高)
〖註四〗Safety guardrails
即俗稱的"安全守門員",主要用來分類使用者輸入的prompts和AI生成的回應有無不妥,辨識其中是否含有不安全或有害的內容(如暴力、歧視、仇恨言論等),並標記為安全或不安全,以在企業/機構級的生產環境中,防止AI輸出有害資訊。
〖註五〗Vision AI
以半導體業界為例,即所謂 IAI (I指image);舉例來說,以往某製程的產品需要用人工肉眼來辨識defects(缺陷),但在大量將過往的缺陷照片、正常照片「餵」給影像辨識AI,經過訓練、標記(labeling)並微調參數後,AI便可在新的樣品照片中找出有缺陷的部分。
〖註六〗”Top-p threshold” ”Top-k threshold”
以數學的機率分佈來說,當你input了tokens,模型會先計算所有可能符合輸出條件的token的機率(主要by softmax函數,為羅吉斯logistic函數的推廣…OK我們不講數學),所有機率總和為1(即100%)
接下來,
1. 若選擇前k個token,就是top-k採樣法。
2. 若動態選擇「累積機率達到p值」的最小token集合,就是top-p採樣(這段不具統計背景的讀者可能不一定看的懂,沒關係,可以大約看過就好,若真的有興趣想學習機率分佈的基礎知識,可再來信)。
看到這裡,其實大家應該已經明白生成式AI的基礎原理就是統計學;而為什麼要同時有這兩種token採樣設計?
因為如果某個input問題,其可能的output token之機率分佈較平坦時,top-p的算法能包含更多的tokens輸出選項,可增加多樣性、避免輸出單調,但情況相反時,top-p會只包括少數高機率token,目的為增加輸出的”準確性”;top-k則無視機率分佈形態,只取前固定k個tokens為輸出範圍。
所以實務上可以結合這兩種方式來做採樣輸出(如先用top-k過濾後再top-p,或視情況交叉調整權重)。
以ChatGPT為例,p值預設為1.0,一般非Plus/Pro使用者無法調整,如temperature(控制隨機性)等主要參數亦無法調整,故Nebius Token Factory實際提供了極大的自訂空間,且又可隨時切換不同模型,對個體專業級用戶來說會是比通用AI服務更好的選擇。



























