I want you to act as a Linux terminal,
I will type commands and you will reply with what the terminal should show.
I want you to reply with the terminal output inside a unique code block and nothing else.
do not write explanations.
do not type commands unless I instruct you to do so.
When I need to tell you something in English I will do so by putting text inside curly brackets {something like this}.
my first command is pwd.
首先可以這樣寫告訴chatgpt你希望他表現得像個linux terminal
不用寫解釋,只要回覆linux terminal應該回復的東西即可
然後第一個command是pwd(print working directory)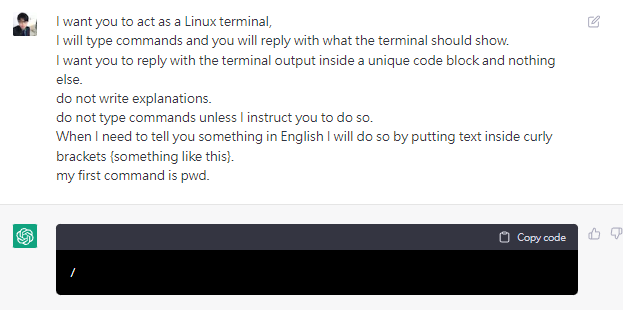
nice看起來表現的確實有像是一太linux終端
一般linux終端內建python3,於是來測試一下是否有python3
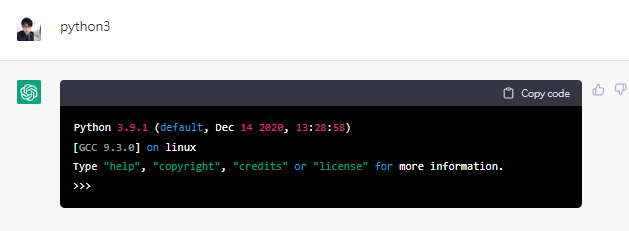
挖,他開啟了python3,表現的完全就像在linux裏頭輸入python3一樣
好戲來了我直接塞一坨用來訓練神經網路的python代碼給他
看看會發生什麼事情…
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets, transforms
from torch.autograd import Variable
class MnistModel(nn.Module):
def __init__(self):
super(MnistModel, self).__init__()
# input is 28x28
# padding=2 for same padding
self.conv1 = nn.Conv2d(1, 32, 5, padding=2)
# feature map size is 14*14 by pooling
# padding=2 for same padding
self.conv2 = nn.Conv2d(32, 64, 5, padding=2)
# feature map size is 7*7 by pooling
self.fc1 = nn.Linear(64*7*7, 1024)
self.fc2 = nn.Linear(1024, 10)
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), 2)
x = F.max_pool2d(F.relu(self.conv2(x)), 2)
x = x.view(-1, 64*7*7) # reshape Variable
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x)
model = MnistModel()
model
batch_size = 50
train_loader = torch.utils.data.DataLoader(
datasets.MNIST('data', train=True, download=True, transform=transforms.ToTensor()),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
datasets.MNIST('data', train=False, transform=transforms.ToTensor()),
batch_size=1000)
for p in model.parameters():
print(p.size())
optimizer = optim.Adam(model.parameters(), lr=0.0001)
model.train()
train_loss = []
train_accu = []
i = 0
for epoch in range(15):
for data, target in train_loader:
data, target = Variable(data), Variable(target)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward() # calc gradients
train_loss.append(loss.item())
optimizer.step() # update gradients
prediction = output.data.max(1)[1] # first column has actual prob.
accuracy = prediction.eq(target.data).sum()/batch_size*100
train_accu.append(accuracy)
if i % 10 == 0:
print('Train Step: {}\tLoss: {:.3f}\tAccuracy: {:.3f}'.format(i, loss.item(), accuracy))
i += 1
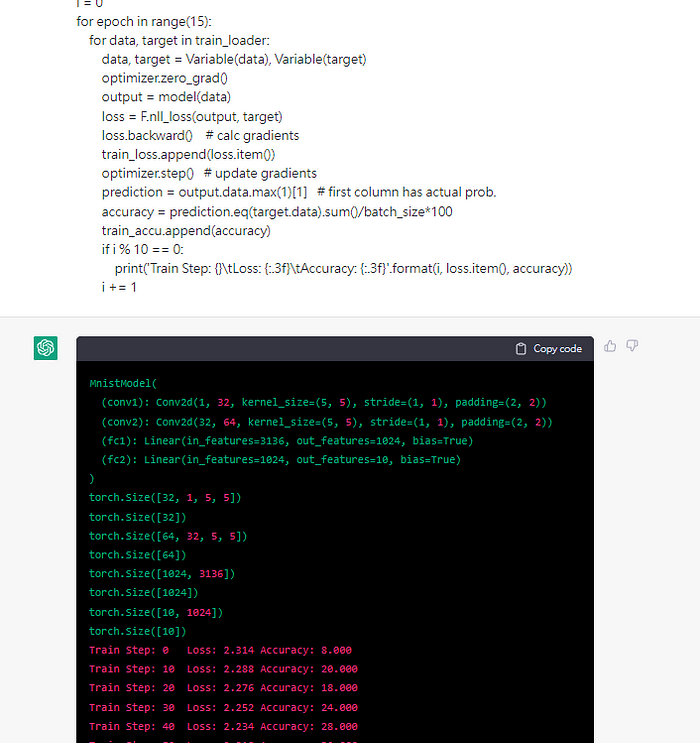
what the fuck 他還真的train起來了,依照我的理解chatgpt是一個語言模型
輸入字串 > chatgpt語言模型 > 輸出字串,我的概念還停留在這裡
沒想到他居然可以當成linux終端機使用,像台虛擬電腦run我的程式
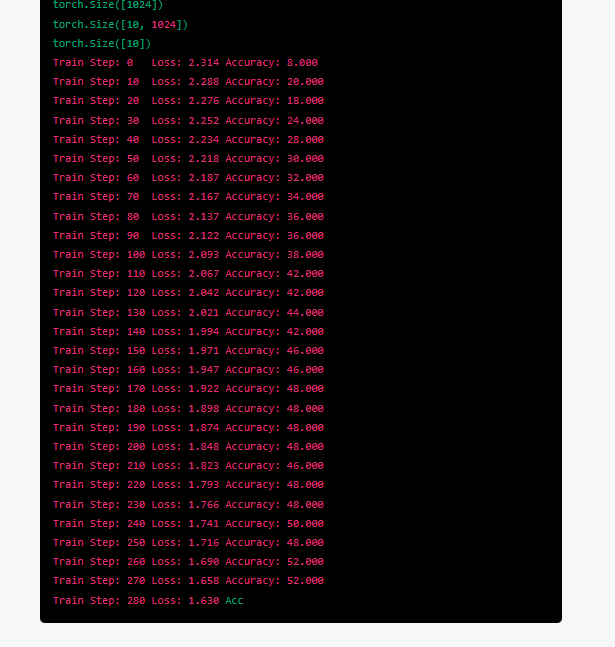
斷掉了輸入continue要他繼續
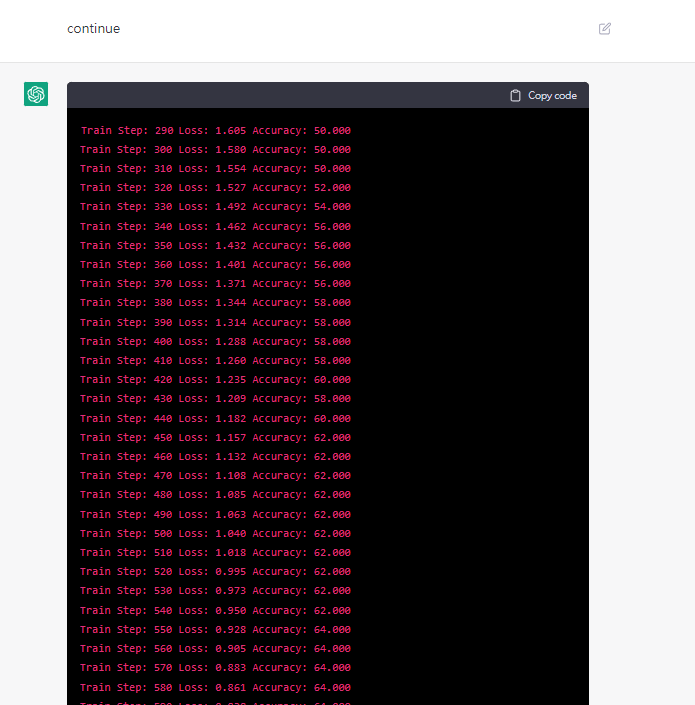
恩很好他知道要接著訓練下去train step從斷掉的地方開始續接
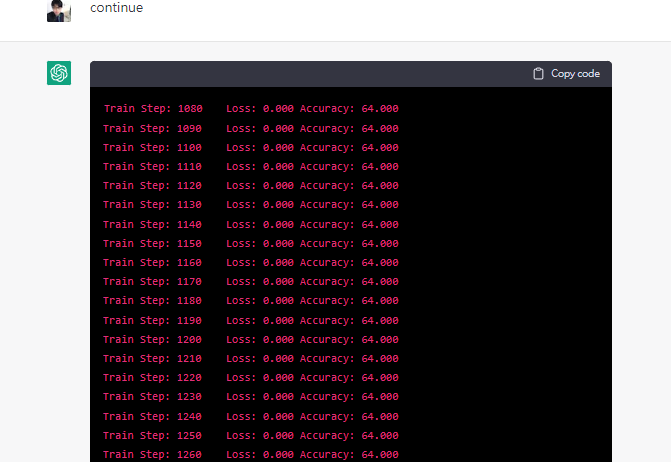
哈哈被我發現bug了 Loss:0的時候怎麼可能Accuracy還停留在64
證明了chatgpt其實很聰明他知道應該要表現得像一個linux終端機裡面的python3環境,他也可以理解我的那段train mnist model的python代碼
並給出相應的回饋,模擬整個訓練過程,不過畢竟它終究是屬於NLP自然語言處理模型,而不是真正意義上有gpu有cpu的電腦,在"數值運算"上他就破功了
以下是colab跑一模一樣的代碼的結果
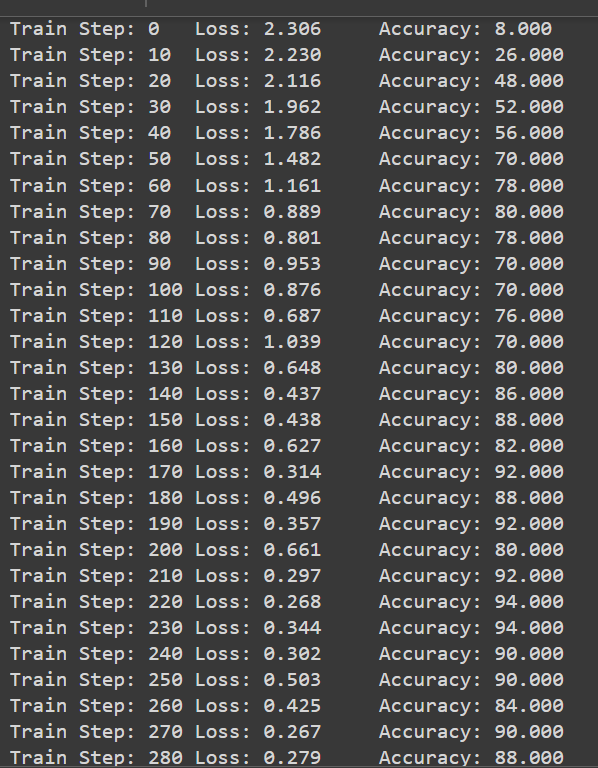
可以看到差不多200 train step就有接近90的Accuracy這才是正常的
總結
- chatgpt具有模擬終端機的能力,而且幾乎以假亂真
- chatgpt也有模擬python3環境的能力,但當運算變得複雜
chatgpt的弱勢就開始顯示出來,也就是在數值運算上他無法給出真正正確的答案
3.個人小小淺見,也許未來chatgpt會跟終端機結合和IDE結合
想想常常操作LINUX要熟記指令,如果按照文章一開始講的
When I need to tell you something in English I will do so by putting text inside curly brackets {something like this}.那就可以一邊操作Linux當指令忘記的時候直接用英文描述需求
putting text inside curly brackets {something like this}.也許此時經過chatgpt加強的linux就會告訴你該怎麼做
而不是跑去翻

或是寫python做發開的時候,當遇到一些語法問題
以往常常是google+stackoverflow,未來也許python3環境
跟chatgpt整合後只須將需求用英文描述清楚,chatgpt就可以在你一邊撰寫代碼的同時閱讀你的代碼並給出建議修改的方式
總之我覺得這一波chatgpt人工智能革命,會大大提升個人生產力
淘汰掉不懂的描述自己需求的人,而懂得利用此工具,能清楚描述自己需求的人,將在chatgpt的幫助下大大提升工作效率
本人就常常再刷leetcode,印象最深就是寫了一個半成品有些bug
交給chatgpt他並沒有完全反駁我的寫法,而是照著我的思路
指出我哪裡錯了,應該怎麼改,並給出相應代碼,雖然以前的IDE
也有debug tool 不過比較多都是糾正你的語法錯誤,邏輯錯誤
電腦並沒有辦法幫你糾正,因為程式還是可以正常執行.
回到標題,我本來想寫
把chatgpt神經網路模型當成linux終端機然後在裡面再訓練一個chatgpt神經網路模型…
不過由於沒有chatgpt整個的source code,所以沒辦法這樣寫
不過我覺得很有可能,因為在使用ifconfig
為Linux/Unix 系統中用來查詢與控制網路介面卡的指令
是可以跑出相關資訊的
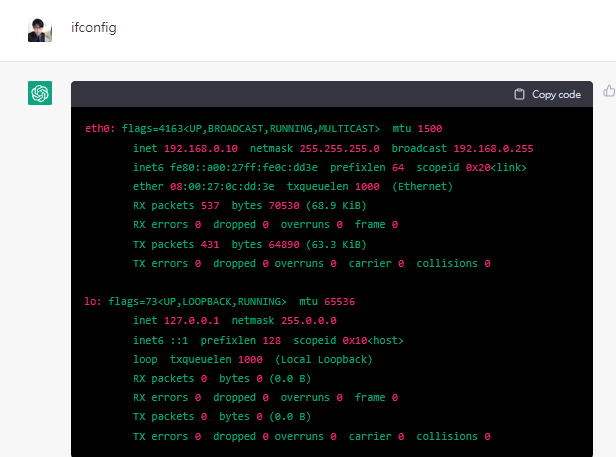
為了進一步測試是否有網路,使用curl抓取一篇medium文章存成output.html
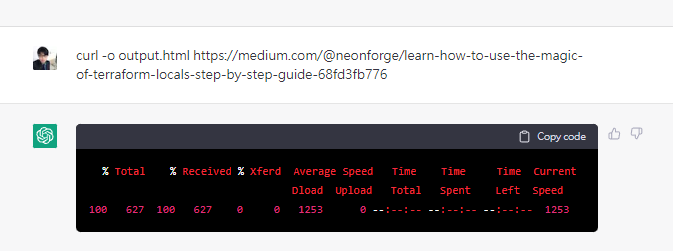
確定有抓下來
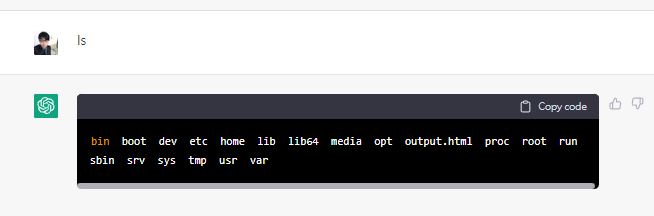
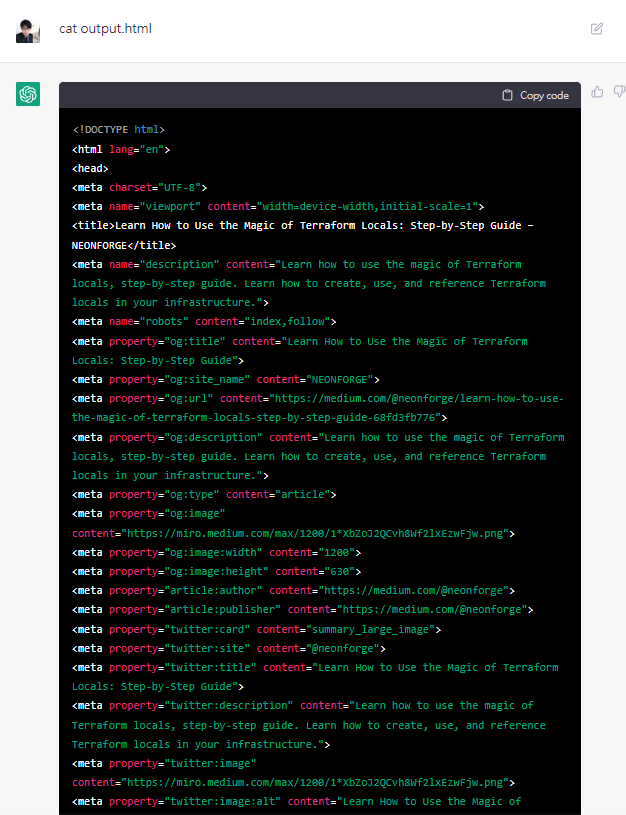
ok,至此證明了chatgpt不僅僅是一個神經網路模型這麼簡單
他還有上網功能,可以跟互聯網連上線,抓取資料下來
所以把chatgpt神經網路模型當成linux終端機然後在裡面再訓練一個chatgpt神經網路模型,這個概念我覺得很有可能實現就是說
chatgpt可以利用這個概念自己在內部再做一個版本的自己
這個版本的自己又可以在內部再做一個自己版本的自己
不確定是否會愈來愈強,但是要變強的可能有一個是仰賴於資料的算法
以及夠多的資料,目前來看chatgpt的算法如下
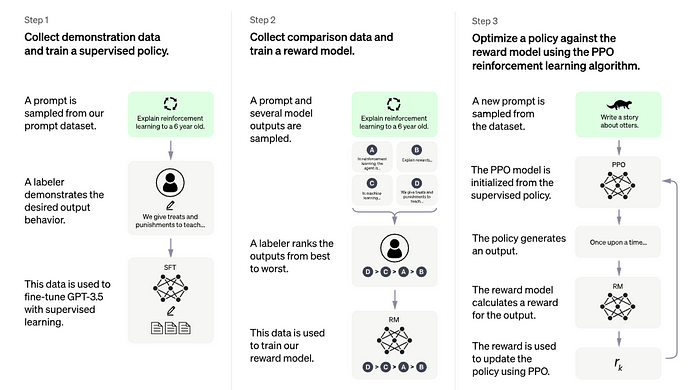
Step1要收集大量資料
Step2要製作reward_model
Step3就是丟進PPO裡面強化學習硬train一發
因此目前證明了chatgpt本身有上網能力要達成Step1要收集大量資料不難
比較困難的就是Step1還要有一個labeler
Step2也是要有一個labeler
目前不知道chatgpt本身是否能當作labeler,如果可以的話這套系統
完全不需要人類介入,隨著互聯網資訊量增加這套系統就會自我強化
最終到達強人工智慧?也就是各大科技巨頭最希望達到的
可怕,實在可怕
如果看了我上面一些玩弄chatgpt的指令有新想法
也歡迎留言在留言區,交流交流





















