我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
AI說書 - 從0開始 - 180 | RoBERTa 預訓練前言
留言
留言分享你的想法!

Learn AI 不 BI
225會員
646內容數
這裡將提供: AI、Machine Learning、Deep Learning、Reinforcement Learning、Probabilistic Graphical Model的讀書筆記與演算法介紹,一起在未來AI的世界擁抱AI技術,不BI。
Learn AI 不 BI的其他內容
2024/09/25
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
從 AI說書 - 從0開始 - 159 | Pretain 模型緣起 到 AI說書 - 從0開始 - 189 | 製作聊天介面,我們完成書籍:Transformers
2024/09/25
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
從 AI說書 - 從0開始 - 159 | Pretain 模型緣起 到 AI說書 - 從0開始 - 189 | 製作聊天介面,我們完成書籍:Transformers
2024/09/24
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
整理目前手上有的素材:
AI說書 - 從0開始 - 180 | RoBERTa 預訓練前言:RoBERTa 預訓練前言
AI說書 - 從0開始 - 181 | 預訓
2024/09/24
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
整理目前手上有的素材:
AI說書 - 從0開始 - 180 | RoBERTa 預訓練前言:RoBERTa 預訓練前言
AI說書 - 從0開始 - 181 | 預訓
2024/09/24
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
整理目前手上有的素材:
AI說書 - 從0開始 - 180 | RoBERTa 預訓練前言:RoBERTa 預訓練前言
AI說書 - 從0開始 - 181 | 預訓

2024/09/24
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
整理目前手上有的素材:
AI說書 - 從0開始 - 180 | RoBERTa 預訓練前言:RoBERTa 預訓練前言
AI說書 - 從0開始 - 181 | 預訓
你可能也想看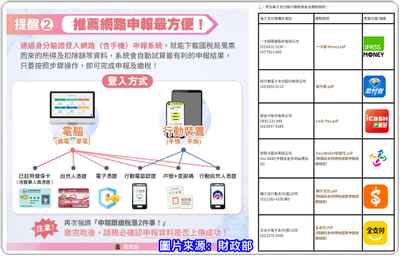
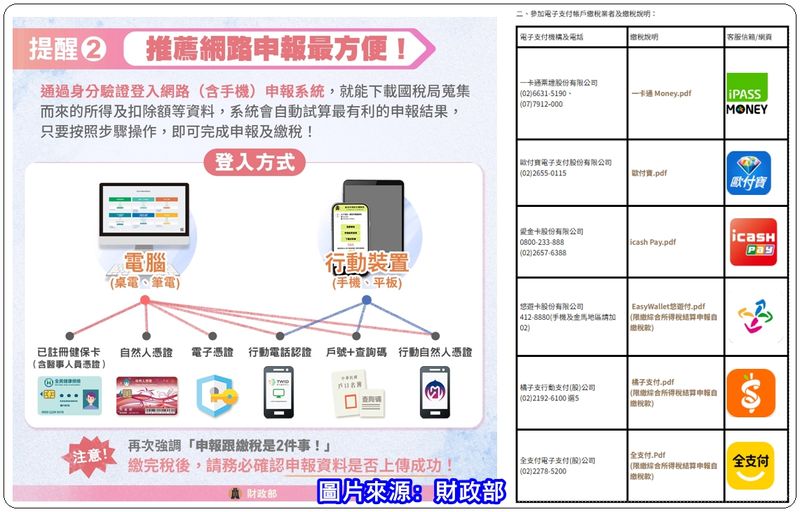
















每年4月、5月都是最多稅要繳的月份,當然大部份的人都是有機會繳到「綜合所得稅」,只是相當相當多人還不知道,原來繳給政府的稅!可以透過一些有活動的銀行信用卡或電子支付來繳,從繳費中賺一點點小確幸!就是賺個1%~2%大家也是很開心的,因為你們把沒回饋變成有回饋,就是用卡的最高境界
所得稅線上申報
每年4月、5月都是最多稅要繳的月份,當然大部份的人都是有機會繳到「綜合所得稅」,只是相當相當多人還不知道,原來繳給政府的稅!可以透過一些有活動的銀行信用卡或電子支付來繳,從繳費中賺一點點小確幸!就是賺個1%~2%大家也是很開心的,因為你們把沒回饋變成有回饋,就是用卡的最高境界
所得稅線上申報


全球科技產業的焦點,AKA 全村的希望 NVIDIA,於五月底正式發布了他們在今年 2025 第一季的財報 (輝達內部財務年度為 2026 Q1,實際日曆期間為今年二到四月),交出了打敗了市場預期的成績單。然而,在銷售持續高速成長的同時,川普政府加大對於中國的晶片管制......
全球科技產業的焦點,AKA 全村的希望 NVIDIA,於五月底正式發布了他們在今年 2025 第一季的財報 (輝達內部財務年度為 2026 Q1,實際日曆期間為今年二到四月),交出了打敗了市場預期的成績單。然而,在銷售持續高速成長的同時,川普政府加大對於中國的晶片管制......


我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
繼 AI說書 - 從0開始 - 82 與 xxx ,我們談論了衡量 AI 模型的方式,那當你訓練的模型比 State-of-the-Art 還要好並想要進行宣稱時,需要
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
繼 AI說書 - 從0開始 - 82 與 xxx ,我們談論了衡量 AI 模型的方式,那當你訓練的模型比 State-of-the-Art 還要好並想要進行宣稱時,需要

我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
Transformer 可以透過繼承預訓練模型 (Pretrained Model) 來微調 (Fine-Tune) 以執行下游任務。
Pretrained Mo
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
Transformer 可以透過繼承預訓練模型 (Pretrained Model) 來微調 (Fine-Tune) 以執行下游任務。
Pretrained Mo

我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
延續xxxx,ChatGPT 產生的程式,我們將它匯入 Colab 執行看看 ( Colab 使用教學見 使用Meta釋出的模型,實作Chat GPT - Part 0
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
延續xxxx,ChatGPT 產生的程式,我們將它匯入 Colab 執行看看 ( Colab 使用教學見 使用Meta釋出的模型,實作Chat GPT - Part 0

我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
先做個總回顧:
Transformer 架構總覽:AI說書 - 從0開始 - 39
Attention 意圖說明:AI說書 - 從0開始 - 40
Transfo
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
先做個總回顧:
Transformer 架構總覽:AI說書 - 從0開始 - 39
Attention 意圖說明:AI說書 - 從0開始 - 40
Transfo

我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
延續AI說書 - 從0開始 - 25示範了ChatGPT程式的能力,現在我們繼續做下去。
AI說書 - 從0開始 - 25在步驟7:Plot the confusio
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
延續AI說書 - 從0開始 - 25示範了ChatGPT程式的能力,現在我們繼續做下去。
AI說書 - 從0開始 - 25在步驟7:Plot the confusio

我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
延續AI說書 - 從0開始 - 22解釋Foundation Model與Engines意涵後,我們來試用看看ChatGPT。
嘗試問以下問題:Provide a
我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
延續AI說書 - 從0開始 - 22解釋Foundation Model與Engines意涵後,我們來試用看看ChatGPT。
嘗試問以下問題:Provide a