我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
先做個總回顧:
- Transformer 架構總覽:AI說書 - 從0開始 - 39
- Attention 意圖說明:AI說書 - 從0開始 - 40
- Transformer 內的 Encoder 架構總覽:AI說書 - 從0開始 - 41
- Input Embedding 意圖說明:AI說書 - 從0開始 - 42
- Embedding 訓練方式:AI說書 - 從0開始 - 43
- Embedding 結果呈現:AI說書 - 從0開始 - 44
- Positional Encoding 功能介紹:AI說書 - 從0開始 - 45
- Positional Encoding 畫圖感受:AI說書 - 從0開始 - 46
- Positional Encoding 實際計算:AI說書 - 從0開始 - 47
- Embedding 與 Positional Encoding 的相似度比較:AI說書 - 從0開始 - 48
- Embedding 與 Positional Encoding 的合成方式:AI說書 - 從0開始 - 49
- Embedding 與 Positional Encoding 的合成前後討論:AI說書 - 從0開始 - 50
- Multi-Head Attention 意圖說明:AI說書 - 從0開始 - 51
- Single-Head Attention 數學說明:AI說書 - 從0開始 - 52
- Multi-Head Attention 數學說明:AI說書 - 從0開始 - 53
- Attention 機制程式說明 - 輸入端:AI說書 - 從0開始 - 53
- Attention 機制程式說明 - Query 端:AI說書 - 從0開始 - 54
- Attention 機制程式說明 - Key 端:AI說書 - 從0開始 - 54
- Attention 機制程式說明 - Value 端:AI說書 - 從0開始 - 55
- Attention 機制程式說明 - Query 、 Key 、 Value 結果:AI說書 - 從0開始 - 56
- Attention 機制程式說明 - Attention Score 計算:AI說書 - 從0開始 - 57
- Attention 機制程式說明 - Attention Score 正規化計算:AI說書 - 從0開始 - 58
- Attention 機制程式說明 - 輸出結果計算:AI說書 - 從0開始 - 59
- Attention 機制程式說明 - 輸出結果呈現:AI說書 - 從0開始 - 60
- Attention 機制程式說明 - 總整理:AI說書 - 從0開始 - 61
- Attention 例子回歸 Google 原始模型的提點:AI說書 - 從0開始 - 62
- Single-Head 過度到 Multi-Head Attention 程式手法:AI說書 - 從0開始 - 63
- Add & Layer Normalization 說明:AI說書 - 從0開始 - 64
- Feedforward 說明:AI說書 - 從0開始 - 65
至此講完 Transformer 的 Encoder 部分,而 Decoder 架構如下:
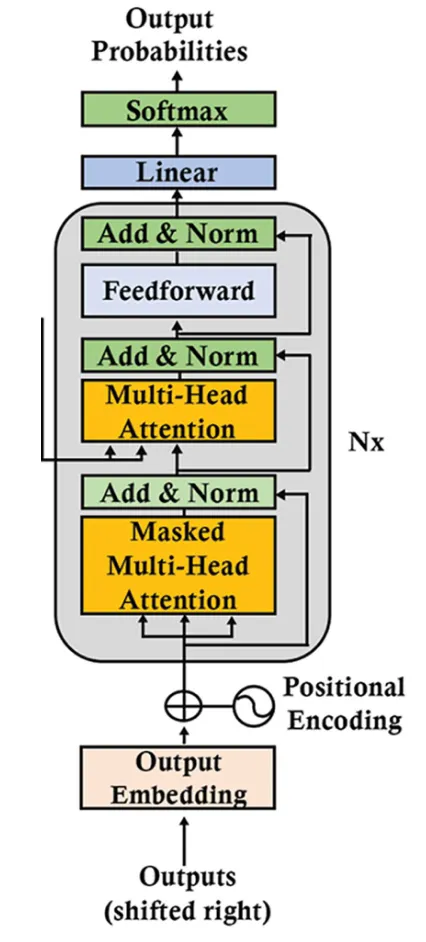
- 原始 Google 的 Transformer 論文中,其於 Decoder 內,一樣配置 N = 6
- 一個 Decoder Layer 中,包含三個 Sublayer ,其分別為:
- Multi-Headed Masked Attention Mechanism
- Multi-Headed Attention Mechanism
- Fully Connected Position-Wise Feedforward Network


















