在類神經網路導覽裡,我們提到了類神經網路界的單細胞生物,被稱為感知器 (perceptron) 的單神經元分類器。感知器利用逐一探訪訓練資料,以更多的訓練例子被正確的分類為目標,來更新任意初始的權重。在上一章中,我們也提到了更為複雜的類神經網路 - FeedForward 類神經網路。FeedForward 類神經網路,是一個層狀結構,提供層與層之間的連結,而視同層之間的神經元是相互獨立的。
當然,這樣的層狀結構不僅呆板,也無法在真實世界中運用(我們的真實世界包括了影像處理和序列式資料)。就算我們有了能描述真實世界的網路架構,感知器的學習方法也很難應用到這樣的層狀結構。我是說,你如何對非線性的 decision boundary 求單一法向量(normal vector) 呢?顯然地,我們需要更好的方法。在這篇中,我們將要檢視一個古老的方法,稱為梯度下降,或是最陡梯度下降學習法(Steepest Gradient Descent)。這個古老的學習方法並不是類神經網路專有,而早就應用在各式各樣的目標方程式(objective function),只要這個目標方程式具有連續且一次可微的性質,就能找到全域或區域的最佳解,是目標方程曲面的複雜度。
其次,有學習那就該有驗收,所以在解釋完梯度下降學習法後,都會專注在如何診斷你的模型是否為“好”模型,在下一篇則會提到有什麼其他辦法讓你的模型變“好”。

梯度下降學習法
在正式進入梯度下降學習法之前,先了解什麼疊代式演算法(iterative algorithm)。疊代式演算法,通常會先從一個隨機的初始值開始,然後再利用疊代的方式逐步來更新參數。每次疊代中,都會將上一次疊代計算出來的參數值,加上當次疊代,所計算出局部最佳化損失函數的資訊,來作為下一疊代的參數的更新值。透過多次疊代來更新參數後,逐步收斂後,而達到全域最佳化損失函式的結果。
感知器的學習方法,就是一種損失函數為(1 - 正確率,accuracy)的疊代演算法,而每次疊代則是計算每個訓練例子對參數的貢獻值。參數,以感知器的例子來說是線性分割平面的法向量。只要訓練例子為線性可分,則可以保證感知器演算法可以收斂「註一」。非疊代演算法的例子,在這裏以線性迴歸舉例,該方法則是一步解法,因為可以求得 Normal Eqaution 的確實解(Exact solution)。對迴歸分析可以見 Prof. Andrew Ng’s 在 Coursera 的 Machine Learning 線上課程(延伸閱讀一)。
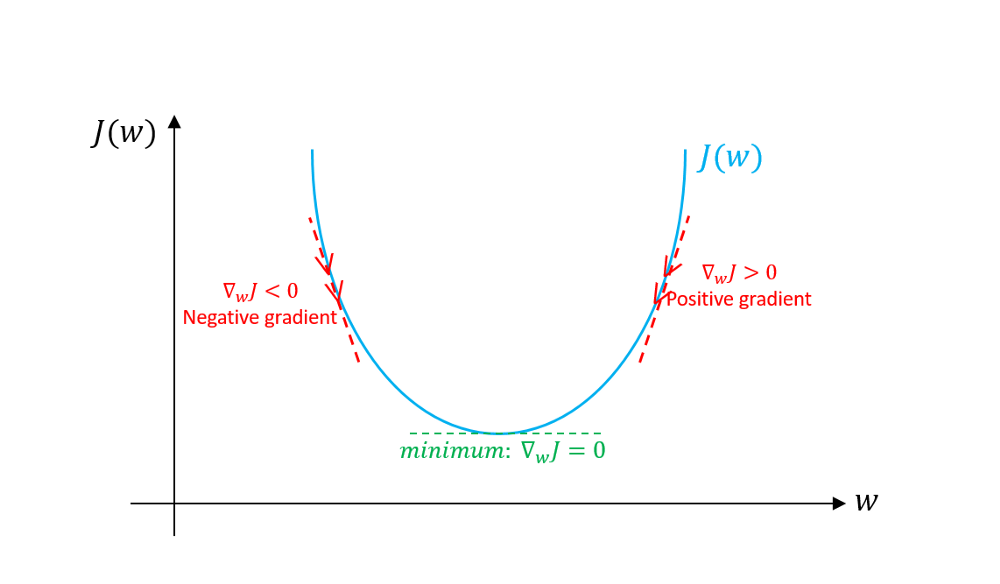
梯度下降學習法是屬於疊代式演算法,其中心思想就是仰賴疊代式演算法,疊代中的每一步都計算損失函示對參數的梯度,以期達到該函式最低點,而達到最佳化損失函式的目的。梯度(gradient)指的是具有方向性的一次微分量。如下圖所示,梯度告訴我們目標函式的局部走向,因此我們可以藉採取和梯度相反的方向,抵達該函式的最小值。如下圖左,如果我們在梯度值為正的一側,梯度下降演算法就該往相反的方向(紅色箭頭)以抵達最小值。倘若我們在梯度值為負的一側,ㄧ樣是往與梯度相反前進,以達到最小值。
實際上,這個演算法在每一次疊代進行局部搜尋最佳化目標函式的參數值,最後透過多次疊代收斂至達到目標函式最小化的參數值。然而,如我用極為繁瑣的步調來緩慢介紹梯度下降學習法,該演算法還需要用一個名為 learning rate 的參數來控制每一次疊代中更新的步距(下圖中,簡寫為 lr)。若 learning rate 設為 1,則使用該次疊代算出的梯度為步距,若不為 1,則以當下算出來的梯度乘上 learning rate。
雖然快速學習很吸引人,但通常,learning rate 只會設定成遠小於 1 的數目,省得學地過快,最後在目標曲面上跳來跳去。

接著,讓我們將梯度演算法的步驟,列舉如下:
梯度演算法步驟:
- 初始化參數為任意值(圖一右上)
- 在 i 次疊代,計算出下一次疊代(i+1)的參數值,根據此公式:W(i+1) = W(i) - g(i) * lr (圖一右下)
- g(i) 為在該點計算出的梯度,可由泰勒展開式一階逼近求得,恰巧是通過 W(i) 的切線斜率。
- 當損失函數到達最低點或超過最大疊代數時,停止疊代。
同時,這個版本還有梯度上升(gradient ascent)版本,主要是在更新參數時,取與梯度相同的方向,也就是往最大值出現的方向前進。其次,在公式中梯度的計算,會看到取單元長度(梯度除以它的範數),也就是只有梯度方向會被考慮。更多關於梯度下降法的變異,會在下一篇中詳加解釋。
到此,我們似乎有了一個比感受器更棒的學習演算法,因為這個演算法不僅能使用於分類器,更可以用於迴歸模型,或甚至任何「可微分」的損失函數。等等,有些讀者可能感覺到事情似乎太過美好,而開始覺得有所蹊蹺...
機械學習訓練流程
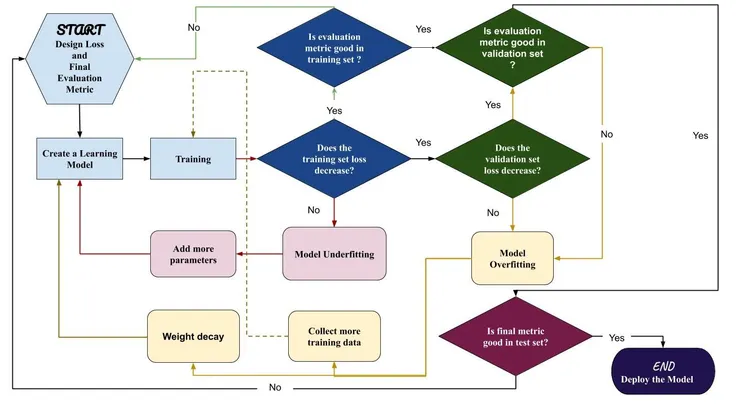
下圖為一個簡化的機械學習訓練的流程。該圖形從如何設計損失函式(Loss Function)和最後的量度標準(Evaluation Metric)到可以運行配置一個模型(Deployment)。在圖中則有三個分別顏色標注的路線。他們分別是綠色(Evaluation Metric 與損失函式表現相異),紅色(擬合不足,Underfitting)和黃色(過度擬合,Overfitting)。
模型評估(Model Evaluation)
就像準備應試學生,拿著考古題訓練自己對該學科的理解能力一樣。準備考試的學生,通常會先將考古題分成兩部分:一部分可以藉由邊做題目邊檢查解答,以糾正自己理解錯誤的地方。另外一部分的試題,則會先將解答覆蓋起來,待做完所有這部分的試題後,再檢查解答,用此方法評估自己的學習成果。
相同地,機械學習演算法,在訓練時,也會將現有的訓練資料分成兩個部分:第一個部分被稱為訓練集(training set),使用於模型建置與訓練過程中。在訓練集中每一個訓練實例的分類標籤,都會被納入在訓練的過程裡。訓練集在機械學習流程圖上,所扮演的角色為量度模型訓練結果,也就是深藍色菱形所顯示的檢查步驟。
第二個部分則被稱為驗證集(validation set),和學習考古題的學生相似,是用來評估訓練的成果。在評估的過程中,已訓練好的模型將不會對驗證集繼續訓練,相對地,模型將會一一預測在驗證集中的實例,最後再以適合評估該訓練任務的量度指標(Evaluation Metrics)對驗證集做模型評估(Model Evaluation)。驗證集在機械學習流程圖上,所扮演的角色為量度模型泛化的能力,也就是深綠色菱形所顯示的檢查步驟。
但,事情的蹊蹺就在此,為什麼已經擁有了損失函式(loss function),還需要量度指標(Evaluation Metrics)呢?
常用的量度指標通常不可微分,因此造成難以應用梯度下降這類演算法。如,在分類任務中常用的量度指標就是分類的正確率,主要是計算分類正確的比例。然而因為作為最後量度指標的正確率不可微,所以在損失函數上多會以可微的版本,如 Cross Entropy 作為損失函數「註二」。

而迴歸任務,常用的量度指標則是 Mean Squared Error,通常也作為損失函式,所以並沒有如分類任務可能會出現的問題:損失函式的值變化和量度指標相反,或量度指標的代理方程 - 損失函式,無法反映量度指標的走向(也就是機械學習流程圖上,綠線部分)。
至於究竟有哪些量度指標,讀者可到知名的機械學習軟體,使用 python 語言寫成的 scikit-learn 中的量度指標使用手冊中查詢。
模型評估主要的功能是防止模型過度學習,就好比應試的學生,將考古題內的所有答案,死記起來,反而無法將學到的知識應用在尚未見過的題目裡。同樣地,我們也希望透過機械學習完成訓練的模型,有足夠的能力將學到的規則,推論到尚未見到的例子中,這在文獻中又被稱為模型泛化( generalization )的能力。
如何將資料分成訓練和評估資料,則有很多不同的方法。其中一種最常用的被稱為交叉驗證(Cross-Validation)。交叉驗證將所有的訓練資料,分成 K 等份,其中 K - 1 的訓練資料會在訓練模型時使用,也就是作為訓練集。而留下的一份,則在評估中使用,也就是驗證集。如此循環 K 次以確保所有的資料都有機會選進驗證集。
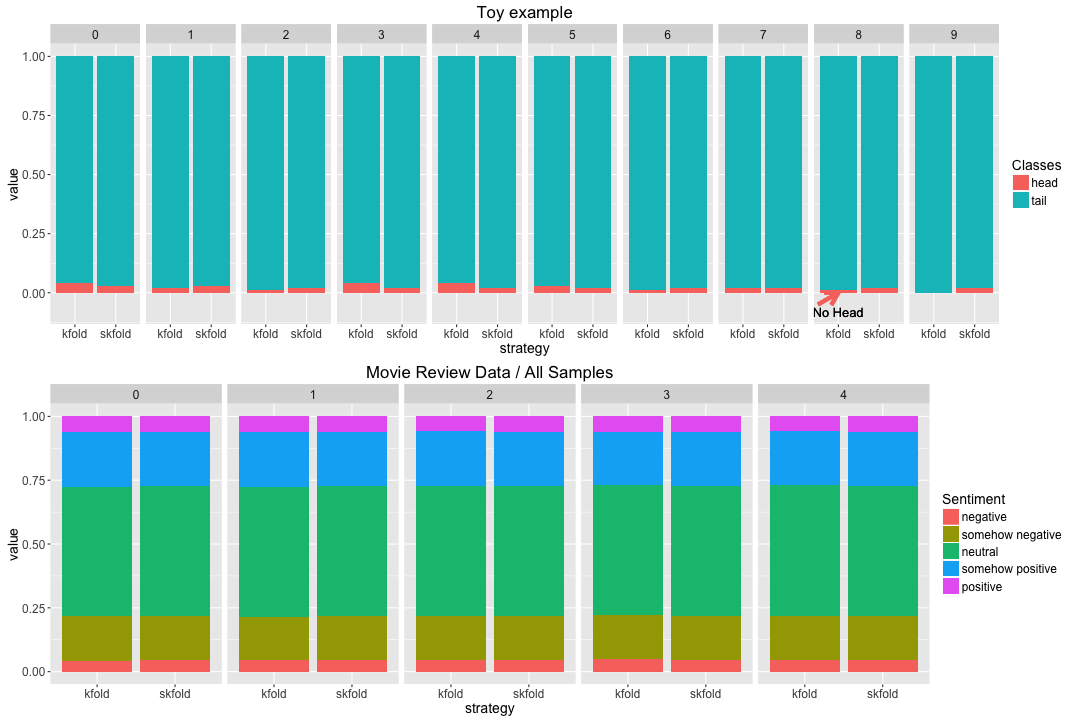
此外,針對不平均(Imbalance)的分類分佈,則有 Stratified 取樣方法,以確保在訓練集和驗證集的分類分佈與全資料樣本相同。下圖的長條圖為分別對模擬產生的玩具集(上,toy examples)和真正的 IMDB Movie Sentiment 資料集(下)做交叉驗證所繪製而成。可以看到在下圖上,由模擬產生的玩具集,由於分類極端分布,所以當未考慮分類不平均的取樣方式(kfold),造成稀少分類(head)未出現在某一個 fold 的測試集中。而相對使用 Stratified 取樣方法(skfold)卻能保證每一個 fold 都有與原資相似的分佈。
另外還有針對稀少訓練例子,所設計的 Leave One Out,每次都留下一個訓練例子作為驗證集,到留下 N 個例子的 Leave N Out 變形。同時, Leave One Out 的交叉驗證方式也適合評估訓練資料本身有相依性,如時間序列資料。
Leave One Out,在統計上也屬於 Jack-Knife resampling 方法的一種。在過去資料不足的情況下,如 Kaggle 上公布的鐵達尼的資料集,其資料量不到一千的筆數
採取 Jack-Knife resampling 會執行與資料集大小相等的循環次數,提供 unbiased 模型平均表現估算。然而現在的資料及數量大多充足,所以選定 K 為 5 或 10 的交叉驗證方法通常都已足夠。然而,K 的選擇,最終還是要看訓練集內資料的分佈程度:如果資料分布差異過多,偏好較大的 K 值,以確保訓練集內的資料能捕捉原資料分布的多樣性和高變異。
更多的交叉驗證方式,可以參考 scikit-learn 中的交叉驗證使用手冊。
Variance and Bias
在我們的機械學習流程圖,還包含了紅線標示的擬合不足(Underfitting)和黃線標示的擬合不足(Overfitting)。到底什麼叫做過度擬合呢?模型的表現擬合不足有什麼重要的診斷指標呢?在這裡我們需要先了解,訓練資料和機械學習之間的關係:這之間的關係可以用兩個量度指標來描述,那就是 Variance 和 Bias。
讓我們重新回到迴歸分析使用的 Mean Squared Error 。對於一個以 Mean Squared Error 作為損失涵式的學習模型,在數學式上,我們可以對 Mean Squared Error 損失做分解,並分解出兩個不同的項式:第一個項式被稱為 Bias 誤差,而第二個項式則被稱為 Variance 誤差。Bias 誤差,量度模型解釋訓練資料平均的能力。而 Variance 誤差,則量度模型解釋訓練資料中變異的程度(再一次,為了更清楚地解釋,我們請讀者前往延伸閱讀一)。
若撇開數學式不談,高 Bias 誤差通常是因為模型的能力(capacity)不足,未能正確描述訓練資料的平均分佈所造成,此時我們可稱為該模型為擬合不足(underfitting)。在這種情況下,增加訓練實例,並不會提高訓練模型的表現,唯有增加模型的複雜度方能獲得較佳的表現(見機械學習流程圖,add more parameters 節點 )。
而高 Variance 則是一個完全相反的情況,起因為過度複雜的參數模型,而導致模型過度記憶訓練實例的模式,因而失去泛化(Generalization) 的能力,也就是大家所熟知的過度擬合(Overfitting)。在這種情況下,增加訓練資料或降低模型複雜度都會幫助減緩和過度擬合的情況。
在量測模型是否過度擬合或擬合不足,可以繪製一張模型表現和訓練歷程的關係圖。這個關係圖又稱為學習曲線圖(Learning Curve),在學習曲線圖中的縱軸通常為損失函示值,愈佳的訓練模型應該有較小的損失值,而橫軸則繪製逐步增加的訓練集大小。
模型的表現必須要以驗證集為主,因為對模型而言,訓練集的表現總是和訓練資料的大小成正比,直到模型本身能力達到飽和,無法對額外增加的訓練資料擁有多餘的辨識能力。
為了能了解模型泛化(Generalization) 的能力,我們可以量測驗證集和訓練集的表現差距,以診斷模型目前的狀態。下面兩圖是重製延伸閱讀一中的投影片,來解釋如何從學習曲線圖診斷目前的模型是屬於高 Bias 或高 Variance。
兩圖左方使用的是縱軸為模型依據損失函式, J, 所計算出的損失值,橫軸則是訓練資料集的大小。圖中的曲線總共有兩條:曲線下標標註為 train 的曲線是依據訓練集大小的增加,而繪製的訓練集損失曲線。而曲線下標標註為 cv 或 test 的曲線是依據驗證集所繪製的。
要注意的是,在繪製訓練曲線時由於驗證集的大小並不會更動,那也就是為何在訓練曲線的一開始,驗證集與訓練集的損失呈現一個位置相反的趨勢。那就是,驗證集的誤差從一開始為高,而漸漸縮小。而訓練集的誤差從一開始為低,逐漸增多。
這種情形,發生在訓練集內含例子數量時,模型所學到的實例不足,尚未捕捉資料原分佈情況,所以驗證集的損失較大,然而隨著訓練集的大小或訓練時間增加,模型所捕捉到的資料變異性愈多, 驗證集的損失則下降。訓練集卻緩緩上升,增多的量端看模型的能力。
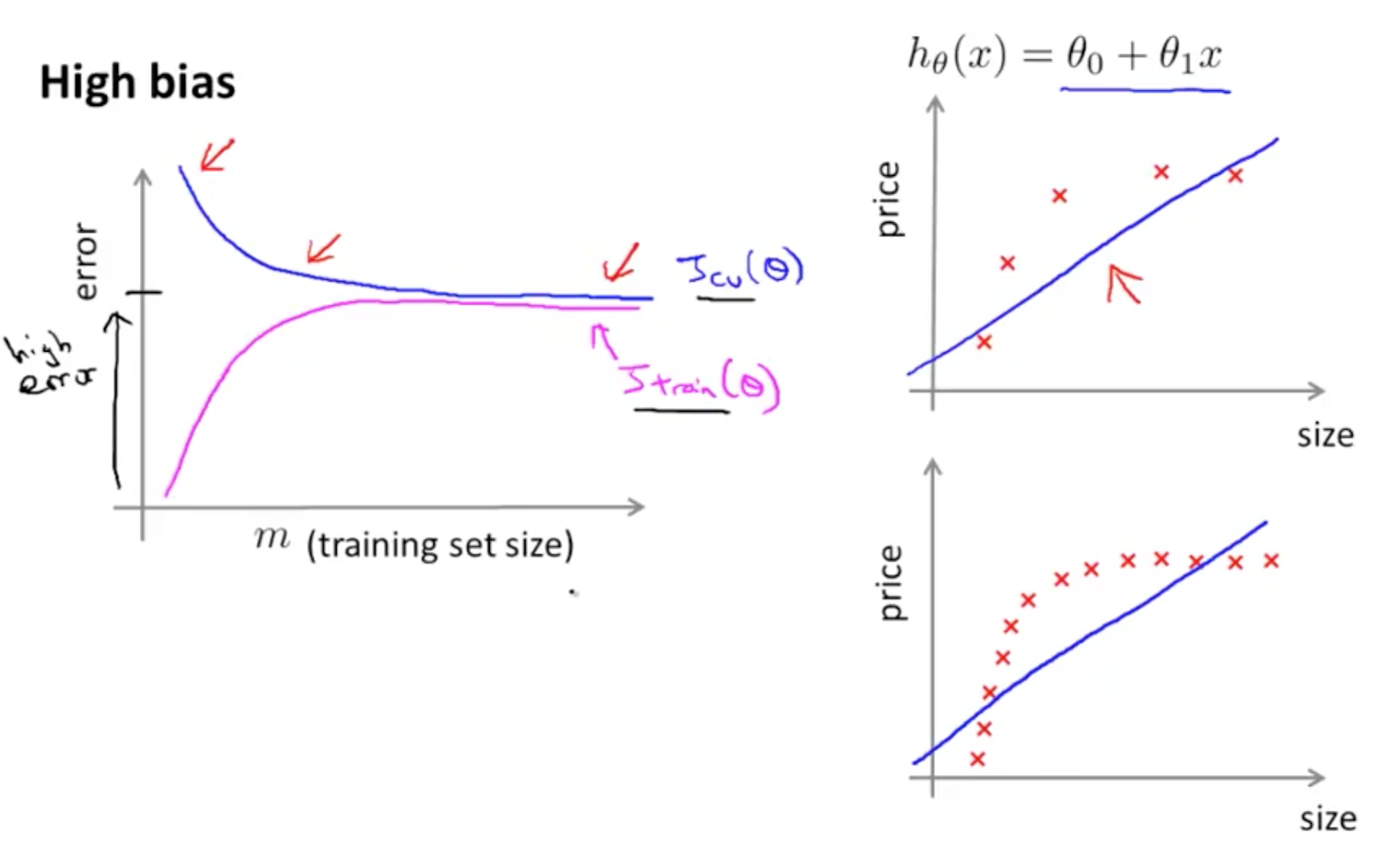
在高 Bias 的情況:
學習曲線圖的特徵為:
- 訓練集的損失誤差曲線即使在訓練資料少量的情況仍保持高的誤差值。
- 無論增加多少訓練資料,訓練誤差仍居高不下,或甚而增加。
- 驗證集的損失誤差和訓練損失誤差間距可以相近,但高於訓練誤差。
從左圖可以看到無論訓練集的大小如何增加,驗證集的損失曲線(藍紫色曲線)和訓練集的損失曲線(桃紅色曲線)相隔相當小的差距。沒有增加模型的複雜度,模型仍舊無法納入新增的資料,因此可以斷定這是一個高 bias 的情況。
從右圖則是一個以兩個參數建立的迴歸模型,僅有一個特徵(size)對應 y 值,price。最上方為模型的公式,只使用兩個參數,可以看到對少量訓練資料(上)已經呈現擬合不足的現象,增加更多訓練點完全沒有幫助(下)。
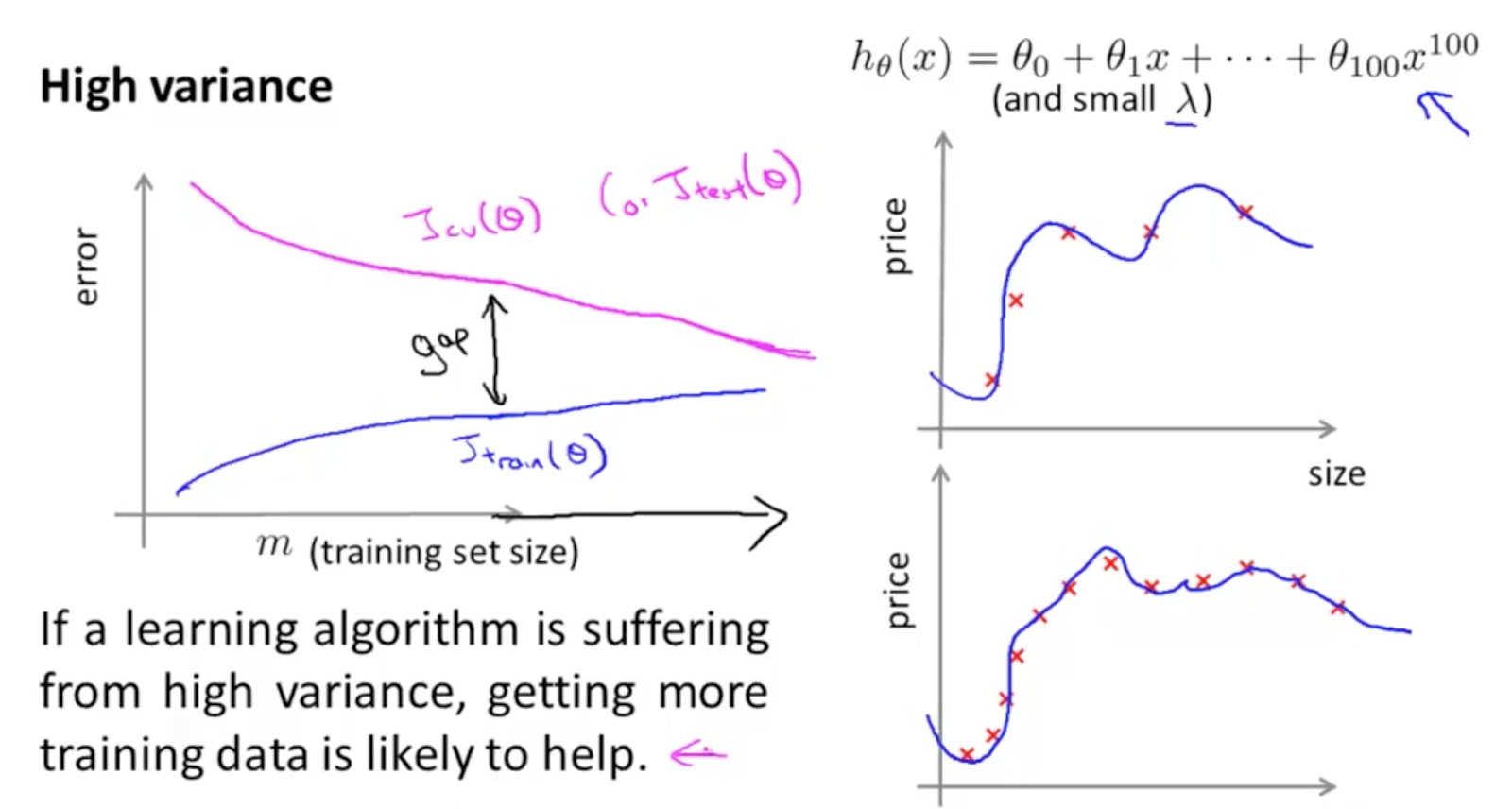
在高 Variance 的情況:
學習曲線圖的特徵為:
- 訓練集的損失誤差曲線由低誤差值開始。
- 訓練集的損失誤差隨著訓練資料的增加,而緩緩地增加或減少。
- 驗證集的損失誤差和訓練損失誤差間距較大,表示模型尚未學到資料原分佈。
可以看到訓練損失曲線(藍紫色曲線)隨著訓練資料的增加,訓練誤差小幅度的增加,並且花較長的時間達到飽和,或接近飽和,所以這不是一個高 Bias 的情況。然而,若觀察驗證誤差曲線,雖然也隨著訓練大小的增加而下降,但始終和訓練誤差曲線保持一個相當大的距離,所以我們可以判定,這是一個高 Variance 的情況。
增加訓練資料點數,有助於降低模型的訓練誤差,直到模型達飽和,開始過度記憶訓練資料實例,而造成泛化不易,使驗證集的誤差較高。
從右圖則是一個以一百個參數建立的迴歸模型,僅有一個特徵(size)對應 y 值,price。最上方為模型的公式,可以看到對少量訓練資料(上)已經呈現過度擬合的現象,增加更多訓練點則會減緩該問題(下)。
兩圖的右方,則是以多項式(polynomial) 方程式來建立的迴歸模型來解說,。多項式 (polynomial )模型在做迴歸分析時的情況。右圖上,模型未能捕捉訓練資料的變異,即使以較少的資料點數來訓練模型。右圖下,則增加訓練資料來訓練模型。可以看到:
一個不具有高 Variance 或 Bias 的模型,其學習曲線的特性,需要有較小的訓練誤差偏差,訓練損失曲線隨著訓練集大小增加,擁有較緩和的損失遞增率 (或曲線擁有較小的坡度),以及和驗證損失曲線有較小的差距。
和類神經網路的關係是 ...
在接下來的文章中,我們將會揭示梯度下降法在訓練類神經網路時,在網絡裡透過正向和反向傳播,扮演的重要角色。
接著,我們也將會發現,此篇所介紹的交叉驗證方法,事實上不怎麼適用於類神經網路。因為,對於類神經網路而言,由於訓練類神經網路通常相當耗時,所以交叉驗證這樣的方法比較不適合評估類神經網路。常用的類神經網路模型評估的方式,也就是將訓練資料分成兩份:一份是訓練集,另外一份是驗證集,採用只有一次循環的評估方法。
而以訓練資料集的大小所繪製的學習曲線所做的各項分析,在類神經網路中也無法獲得直接應用。事實上,類神經網路在診斷時所用的圖是以訓練疊代的數目作為橫軸來繪製,透過診斷訓練集和驗證集的損失值和訓練疊代的數目的變化,而避免以上所述關於 Variance 和 Bias 的各樣問題。
過度擬合在(Overfitting)機械學習中是非常常見的問題,尤其是對於像類神經網路這樣具有許多可調參數(Hyper-parameter)的大型模型。在接下來的文章中,我們將要提到如何解決過度擬合(Overfitting)的問題。
註釋:
- 感知器學習法的訓練次數上限值,在 1962 年,由 Novikoff 提出,該值為最小間距(margin)的平方倒數。直觀的解釋感知器的收斂證明,即是每一次權重的更新一定至少為訓練資料點中的最小間距,而至多則為 1。若訓練例子為線性可分,我們便可以找到一個最佳權重,並計算目前權重與最佳權重的內積距離,可以做為到最佳權重的距離,也是更新的次數。透過帶入前所言的上下極限值,我們便可以得到更新步數的最大極限值。正式的證明可以到康乃爾大學的線上課程觀看,或閱讀參考資料一。
- Cross Entropy 的公式如在文章中所給。該公式的意義在求得預測 entropy 的期望值。 對於每一個類別,預設的機率值將會帶入自然對數(log)而成為 Entropy。Entropy 是資訊的量度,若分類器給予所有的類別同樣的機率,則分類器不具有鑑別力,亂度也最高,亦即 Entropy 會達到最大值。相反的,若分類器給予較高的預測機率,也就是具有較高鑑別率,則我們就有較小的 Entropy 值。
參考資料:
- Perceptron convergence proof Novikoff 的論文,重新掃描數位化。在注釋提到的證明就是來自於 google 在 2013 年發表的 Perceptron Mistake Bounds 文章。
- Machine Learning Mastery “How to use Learning Curves to Diagnose Machine Learning Model Performance”(英):該文章鉅細靡遺的將學習曲線圖(Learning Curve)從定義,分類(對損失函數所繪製的最佳化學習曲線,Optimization Learning Curves 或以 Evaluation Metrics 所繪製的)到舉出數個學習曲線的例子做診斷。包括,模型的擬合程度的診斷以及資料取樣偏差分別發生在訓練和驗證資料集。