
本篇使用UCI機器學習資料庫的Online Shoppers Purchasing Intention Dataset,資料內容為12330筆的顧客網站不同形式(管理、消息、產品)頁面的瀏覽數、瀏覽時間、離開率、跳轉率、頁面價值,以及顧客來自區域、作業系統、瀏覽器等等類別背景變項,本篇將會透過統計與機器學習方式篩選變項,並進行最終顧客是否會購買的預測。 1、首先讓我們載入資料並查看一下資料型態,發現部分背景變項被錯誤轉換成整數型態,不過本篇只會使用連續變項,所以無需進行修改,唯有想要預測的y值Revenue是布林值,將它改成R語言中的factor後進行下一步。
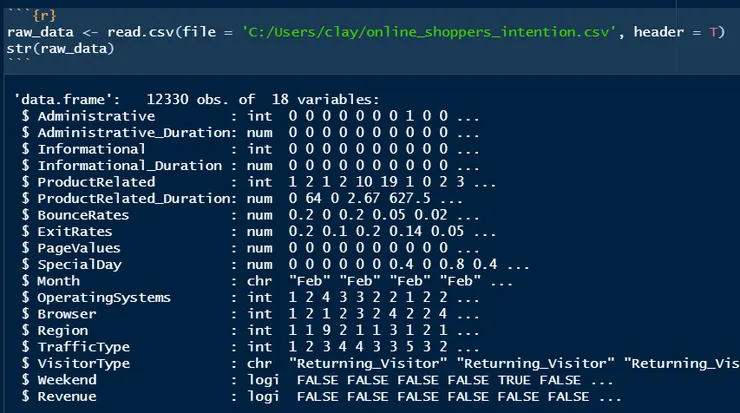
2、刪除第11~17項背景變項,在R語言中可透過c(11:17)這種方式表達從第11筆到17筆資料,加上負號(-)代表是移除這些資料,所以也可透過c(1:10,18)這種方式表達,透過colnames方式重新命名column名稱,並指定為所引入之指定內容。
接著我們引入Hmisc這個套件,裡面的rcorr函數可以讓我們一目了然的察看各變項之間的相關性,對於我們查看資料狀態及建立統計迴歸模型都有很好的幫助,避免可能會遇到的問題,如:多元共線性。
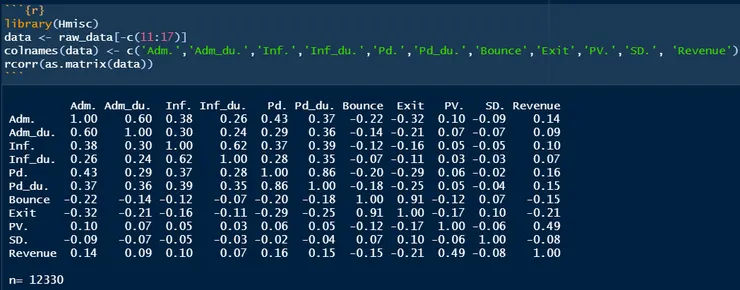
3、根據上方資料,我們會發現行政管理瀏覽次數(Adm.)和行政管理頁面瀏覽時間(Adm_du)有高度相,r=0.60,其他兩種頁面也有同樣情況,回頭查看原始資料發現,基本上如果顧客沒有瀏覽該種頁面,該種頁面的瀏覽時間也會為0,也就是說,只要次數為0,時間必定為0;次數不為0,時間必定不為0。(當發生此種現象,代表資料並非獨立,(0,0)的資料實際上沒有帶來任何資訊,往後會提及處理這種現象的方式)
因為缺乏相關領域的知識,我還是先留下這些資料,於下一步執行特徵篩選再進行刪除的動作。
4、我們可以簡單地透過Boruta這個函數得到特徵選取的建議,方式為
Boruta(y~X, data),呈現的報表會給予特徵是否為重要特徵,根據報表回應,所有變項都是重要變項,我們就不排除任何一個特徵。

5、最後我們透過決策樹建立模型,預測出顧客最後是否進行購物,我們這邊採用rpart函數來進行模型的建立,一樣須先載入rpart套件,模型建立方法與建立線性模型方式很像,我們挑出80%資料當作訓練集、20%當作測試集,最後透過predict這個函數將測試集的資料預測,並製作混淆矩陣檢查預測準確度。
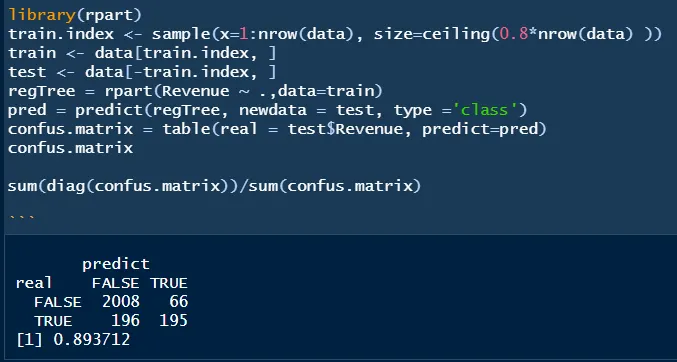
6、結論,透過上述方法與特徵選取過程,預測準確度可達接近90%,但其實這個資料集中有很大的資料不平衡問題(unbalaneced data),往後會提及相關的解決方式,如undersampling、smote、GAN等等方式。
喜歡這些內容麻煩幫我按讚,也可分享出去給更多人知道,學海無涯,這些只是一點點小知識,希望大家會喜歡!























