Durbin-Watson test,對模組的殘差項進行相關聯性檢定,常應用於迴歸分析以及需要限制殘差項要為獨立常態分配。不過我在應用上更關心價格資料是否有聚集在均線附近,若有則可以判定盤整盤,反之則有趨勢發生,相關統計檢定計算步驟詳列如下
- 以均線為例,首先計算出各筆價格與均線之間的殘差,並帶入檢定統計量,請參考下圖一
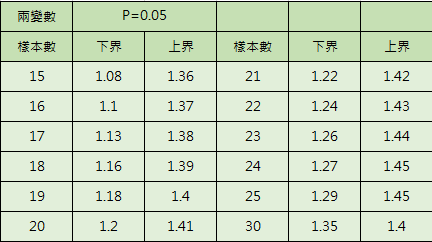
- 統計檢定量介於0~4之間,正相關、負相關檢定與對應的上界、下界,分別有六種關係,
正相關時候
如果d <= 下界 ,誤差項自我相關為正
如果d >= 上界 ,不拒絕,無自我相關
如果下界 < d < 上界 ,則檢定結果無法確認
負相關時候
如果(4 - d) <= 下界 ,誤差項自我相關為負
如果(4 - d) >= 上界,不拒絕,無自我相關
如果下界 < (4 - d) < 上界 ,則檢定結果無法確認