如果把前面把Z檢定和標準誤、標準差給搞懂,那麼t檢定的理解其實就滿簡單的了。
實務上來說,用Z檢定的機會其實比t檢定少,這是因為t分數只需要使用樣本標準差就能算出來,而Z分數卻需要仰賴一個我們根本不知道多少的母體標準差。這篇的目標就是介紹單樣本t檢定的原理,稍微有點長,比較需要耐心。
本篇文章所介紹的t分數,全名為Student't score (有人翻譯為司徒頓t檢定)。一般在社會科學研究當中,沒有特別舉出全名的話,t分數通常就是指Student't score。
之所以會強調這一點,是因為除了經典的Student't test之外,也有其他的t-test存在。
t分數跟Z分數很類似
首先我們需要介紹一下t分數是什麼東西。
在先前的文章 (統計急救箱─抽樣分布與標準誤) 當中,提到過抽樣分布會長成什麼樣子,是由兩個數值決定的:第一個是母體平均數(決定位置),第二個是母體標準差(決定寬度)。
但因為我們不會知道母體標準差是多少,所以就只好用已知的樣本標準差 (就是這次收資料算出來的標準差) 來代替,形成抽樣分布的標準誤 (SE)。這樣一來,我們就可以做像是Z檢定一樣的統計檢定囉~
這個檢定的名字,就叫做t檢定。也就是說,把Z檢定裡的抽樣分布標準差 (standard deviation of sampling distribution),改成抽樣分布標準誤 (standard error of sampling distribution),就會從Z檢定變成t檢定了。

t檢定的原理跟Z檢定是相同的,只是用的是標準誤而不是標準差
t分數和Z分數的關鍵差異:自由度
但這時候可能會有個疑惑...就這麼簡單?直接把母體標準差換成樣本標準差真的不會有什麼問題嗎?
嗯...原理上來說其實真的就這麼簡單沒錯。但當然把母體標準差直接換成樣本標準差,還是會有點不一樣的。那就是...這樣計算出來的抽樣分布不會是個常態分布,而變成一種叫做t分布的分布。
哇,那這下問題不就大了?前面說的假設檢定都建立在抽樣分布形成的常態分布上,結果現在t檢定卻建立在一個不是常態的分布上,那我們怎麼算機率做檢定?
沒關係,我們先來看看t分布到底長成什麼樣子再說。
t分布雖然不是一個常態分布,但其實長得也滿像常態的。更重要的是,t分布的形狀會隨著我們抽樣的樣本大小而改變。
這是什麼意思呢?我們用下面的圖來比較一下。假設下面描繪的都是所謂的「抽樣分布 (sampling distribution)」(想了解抽樣分布是什麼,可以參考統計急救箱─抽樣分布與中央極限定理(一))。
黑色的線就是標準常態分布 (平均數為0,標準差為1的常態分布),紅色的線段是樣本數很小的時候算出的t分布,藍色的線段樣本數比紅色的多,綠色的線段樣本數又比藍色更多。也就是說,黑色的線就是我們拿來做Z檢定的常態分布曲線,而紅色、藍色、綠色的線則是我們把Z分數改成t分數後得出來的分布曲線(只不過這三條線代表的抽樣樣本數是不一樣的)。
在這裡我們會發現一件事:樣本數越大的時候,t分數的線會越來越靠近常態分布 (綠色的線很接近黑色的線)。
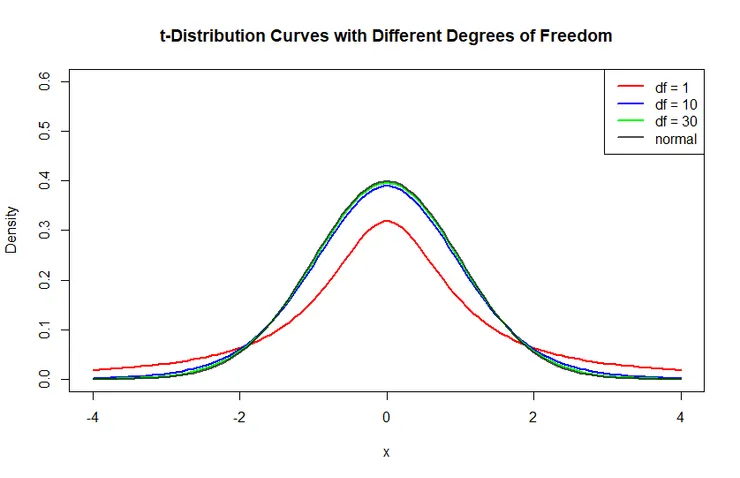
不同自由度下的t分布
有趣的是,當樣本數大到某個程度以後,t分布的線段幾乎就不會再隨著樣本數增加而改變了。這個時候的t分布,長得跟常態分布已經幾乎是一模一樣。
下圖中我們又再次畫了不同樣本數所得出的抽樣分布曲線。可以發現幾乎分不出這些t分布的線段 (綠色、藍色、紅色) 和常態分布曲線的差異了。
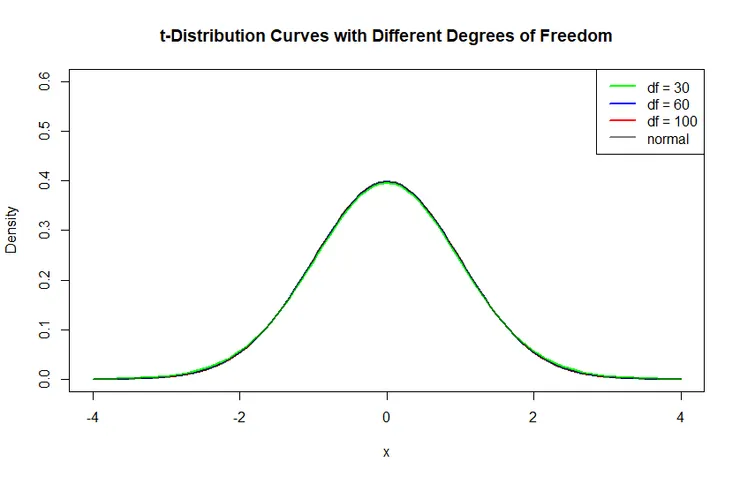
自由度夠大的t分數跟常態分布差不多了
到了這個時候,使用樣本標準差而不是母體標準差來計算抽樣分布的標準誤,感覺就沒什麼大問題了吧?因為當樣本數大到某個地步之後,所得到的t分數分布跟常態分布幾乎沒有差,那接下來的事情也就跟Z檢定差不多了。至於這個樣本數到底多大才行?普遍常用的標準是超過30就可以了 (Field, 2017)。
雖然上面都是說隨著抽樣的樣本數變大 (想像成從袋子中抽出的球數目越多),t分布會越加趨近於常態。不過在統計上不會說樣本數,而是有一個特殊的名詞叫做「自由度 (degree of freedom, df)」來表達t分布樣貌的改變(所以可以看到上面的圖,右上角寫的都是df而不是N,代表這是說自由度的意思)。
為什麼要這麼麻煩,弄一個新名詞出來?這是因為自由度才是真正決定t分布樣子的參數,只不過這個自由度跟樣本數有關,所以上面為了解釋上的方便才會先用樣本數代替。在不同的情況下,自由度跟樣本數之間的關係會有變化,所以使用樣本數來表達t分布的樣貌不如使用自由度來的精確。也因為這個原因,在報告t檢定結果時一定會一起報告自由度的。
雖然我會建議還是要知道自由度怎麼算比較好,但對於初學者來說也不用太執著這個問題,可以先看統計軟體給你的數字就行了。
單樣本t檢定的運作原理(跟Z檢定是一樣的)
上面花了大量篇幅指出t分布和Z分布的相似與相異處。不過如果要給個不精確的超級懶人包的話:
在樣本數夠大的時候t分布可以直接被當成Z分布,也因此可以當成抽樣分布來看待。
所以在實務上,t檢定的原理幾乎就跟Z檢定一樣了,這裡就只快速講一下基本邏輯。
首先,依循Z檢定的邏輯,我們要透過抽樣分布 (sampling distribution) 來做假設檢驗──「若母體平均數為mu,我們現在觀察到的樣本平均數有多大的機率會發生?」假如機率很小 (小於5%機會),我們就可以傾向說母體平均數可能不是mu。
![又是這張圖,只不過這次我們要用t分布來當作抽樣分布了 [*1]](https://resize-image.vocus.cc/resize?norotation=true&quality=80&url=https%3A%2F%2Fimages.vocus.cc%2Fb6efcd72-c228-4e2c-98e6-ae6bf48cffbb.jpg&width=740&sign=Mxklvefep2AATS5kaZWBKsBrIshi-Zb8lBheDCTcXM0)
又是這張圖,只不過這次我們要用t分布來當作抽樣分布了 [*1]
在統計急救箱─常態Z分數與Z檢定中,我們以平均數為中心,分別加上或減去一個標準差找出兩個臨界值,畫出了95%的區間。如果觀察值落於這個區間之外,就代表當母體平均數為mu時,看到當前結果的機率小於5%,所以我們拒絕虛無假設 (也就是認為母體平均比較有可能不是mu)。而在t檢定中,我們用同樣的方法找出臨界值,只是把標準差換成標準誤而已。

在Z檢定中我們找臨界值是使用抽樣分布的標準差,而在t檢定中則是用標準誤
現在有了臨界值後,唯一剩下需要知道的就是這次抽樣平均數落在這個分布圖上面的哪個點了。計算方法跟Z分數差不多,只是把抽樣分布的標準差改成標準誤就行了。

計算本次抽樣平均數在抽樣分布中的t分數
以上就是t分數和t檢定的基本運作方式囉~
t分數在實務上很好用的,熟悉原理對於後續進階的統計檢定會很有幫助喔。
前一篇說專案快上軌道了,結果...
總之人果然不能亂說話,再不更新我自己都以為要棄坑了。
現在學會單樣本的t檢定了,下一篇就來講講一個常見的應用──相關係數的顯著性檢定吧。
去年開始這個寫作計畫的時候,原本預計一年後至少寫到ANOVA的啊...orz
備註:
[*1] 雖然我之前都說這個常態分布圖的縱軸是機率,但其實並不完全正確。如果仔細瞧瞧縱軸會發現這個常態分布曲線的頂點超過1,但難道有機率可以大於1的嗎?嗯...並不是這樣的。這種圖形在統計上叫做機率密度函數圖 (probability density function, pdf),它的縱軸是有可能大於1沒錯,但把縱軸當成機率來看在某種意義上也沒錯。總之...如果真的想知道的話,要先學會積分才可以,所以這裡就不多說了。不過統計急救箱─常態分布與機率的最後其實有稍微提到一些相關概念。
參考文獻
其實講出建議t檢定樣本數建議超過30的教科書到處都是,這裡只是舉出其中一本而已。
Field, A. (2017). Discovering statistics using IBM SPSS statistics (5th ed.). Sage.
致謝
本文所用圖片當中的素材來自於https://www.flaticon.com,由juicy_fish創作。






















