在上一篇文章解釋了常態分布怎麼幫助我們計算事件發生的機率,而更之前也看過了抽樣分布是如何形成常態分布的過程,現在就要利用這兩件事情來慢慢帶出什麼是統計學中的「假設檢定」了。
結合抽樣分布與常態分布的機率特性
先來想想「抽樣分布會成為常態」與「常態分布中的機率可以被計算出來」這兩件事情如何結合在一起,以及結合起來會發生什麼事?
按照前面的慣例,我們還是先準備一個黑色大塑膠袋,裡面塞進去五顆0分球和五顆1分球。
我們從袋子裡面隨機抽取n顆球出來(n小於10)並且計算得到的平均數,在重複做這件事情很多很多次之後,我們必然會得到一個常態的分布。這個分布稱為「抽樣分布 (sampling distribution)」。
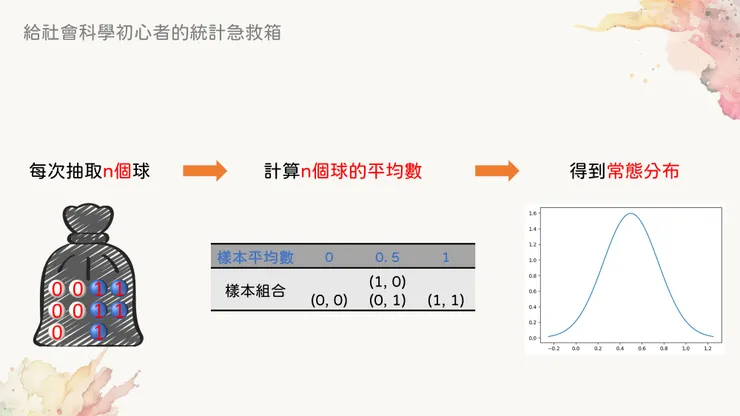
根據中央極限定理,抽樣最終會得到常態分布
而又由於常態分布的特性,只要知道母體的平均數和標準差,就可以知道常態分布上任一點的發生機率。也就是說,在知道母體平均數和標準差的情況下,我們就可以推估這次抽樣得到的樣本平均數有多可能會發生。只不過實務上,我們更常會說的是推估「某個範圍之內」的平均數發生的機率有多高。
例如對於母體平均數是0.5、標準差也是0.5的抽樣分布來說(也就是我們上面黑色塑膠袋裡的球),我隨便從裡面進行一次抽樣,在實際抽出來之前就可以知道有34.1%的機率會得到0~0.5之間的平均數。
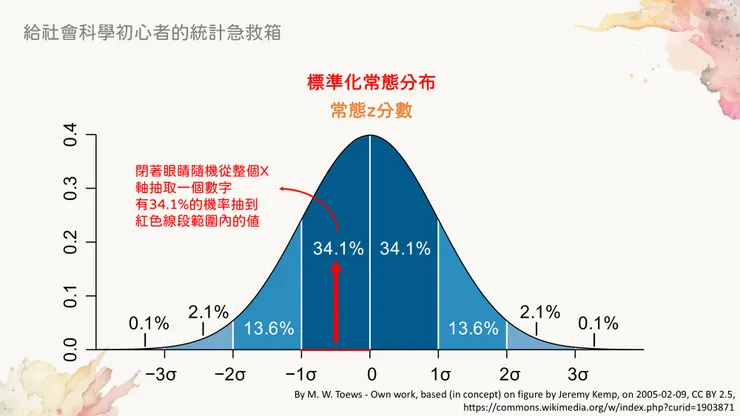
知道母體平均和標準差,就可以計算某個範圍內抽樣平均數的發生機率
所以說,只要知道母體平均數和標準差,在抽樣之前我們其實就能輕鬆猜測這次的抽樣平均數會有多少機率落在某個範圍之內了。而這就是假設檢定的基礎。
從樣本推論母體的困難
前面講這些抽樣分布和機率的時候,都有一個預設前提是我們知道大塑膠袋裡的球長成什麼樣。但這其實並不太符合實際情況...在現實生活中,更多時候我們根本不知道袋子裡的球有幾顆、每一種顏色的球有幾個。如果抽獎前你去問主辦單位,他們也很可能不會告訴你(通常他們只會跟你講最大獎有什麼來吸引你當分母...啊不是,我是說去抽獎)。
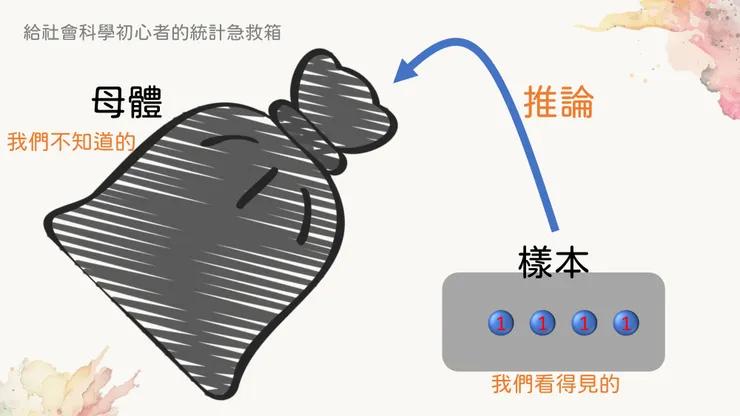
現實生活中,我們通常不知道母體是什麼樣子
如果我們很直觀的要問一個推論的問題,就會是:經過抽樣得到的樣本平均是M,那母體平均是多少?例如上圖,我從袋子裡抽出四顆球,得到平均數是1,那袋子裡面所有的球平均數(母體平均)是多少?

如果直觀的要推 論,會問出這樣的問題
這個問題是很難回答的,因為答案是不管母體長成怎樣,只要袋子裡面的1分球超過四顆,我們都有機會得到這種結果。就算說袋子裡面總共有100顆球,只有四顆球是1分,都不能說我們得到這個樣本的機率等於0對吧?也就是說,只靠這些資訊要推估母體的平均數,根本可以說有無限種可能性,完全沒辦法估計。
那我們該怎麼辦呢?難道真的沒有辦法知道袋子裡的球是什麼樣子了嗎?
不知道母體平均數,我們就先假設一個
奇怪,前面講抽樣分布的時候,好像推出個常態分布就覺得萬事OK,每一種可能性的機率都能算出來的樣子。但真實的數據我們卻沒辦法做到,是為什麼?
答案是:因為我們從來就不知道母體的平均數和標準差是多少。
要像文章最開始講的那樣去推估每次抽樣有多少機率會落在哪個範圍之間,我們就必須要知道母體平均數和母體標準差。然而在現實中我們根本就不知道這兩個東西。畢竟我們就是想推估母體平均數是多少嘛...要是知道了幹嘛還需要推估啊。
不過聰明的統計學家們就想到一個辦法:不知道平均數沒關係,我們「假設」出一個平均數就好了嘛!
這個時候,要推論母體平均數的問題就有了另一種問法:「假設」母體平均數為mu,那麼得到現在這個抽樣結果的機率是多高?
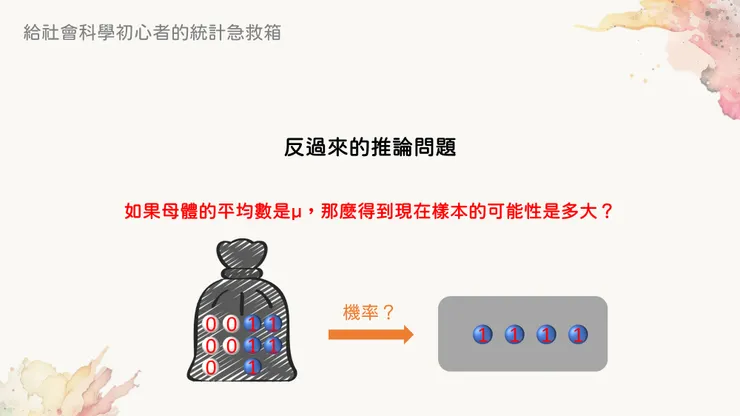
不知道母體平均?就先假設一個吧!
由於知道了一個假設的母體平均數,這時候我們就可以畫出從這個母體中進行抽樣所得到的抽樣分布曲線了(如果你好奇沒有標準差怎麼畫抽樣分布,在這裡我們也先假設我們知道,但標準差的問題我們要到 統計急救箱─抽樣分布與標準誤 才會解決)。而一旦我們知道這個抽樣分布曲線,就可以大概知道這次抽樣中所得到的結果,發生機率有多高啦~
例如在下圖,我們就是假設母體平均數為0.5,畫出了藍色的抽樣分布曲線。這條曲線的最高點(也就是中心點)就會放在母體平均數的位置,而曲線的寬度(抽樣分布的標準差)則由母體標準差和樣本數來決定。
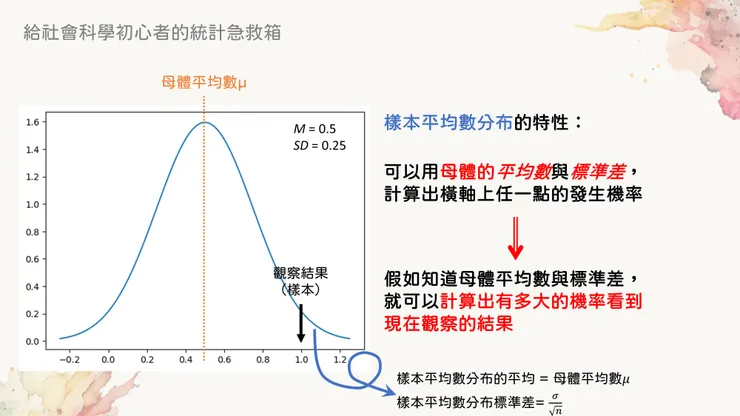
假設母體平均數為某個數,就能依此畫出抽樣分布曲線
那麼這個時候就如同文章一開始提到的那樣,我們可以從常態分布曲線來推估每個點的發生機率大概是多少了。而每一次的抽樣結果(抽樣後算出的平均數)都會是一個點,就是下圖中標記出的「觀察結果1」、「觀察結果2」這兩個位置。
那麼我們要怎麼解讀這張圖呢?
還記得用常態分布來推論機率,在實務上是推論「一個範圍」嗎?在下圖當中,就有兩個紅色的雙箭頭標示出了68%和95%的範圍。其意義是:「以現在的常態分布曲線為前提,在x軸當中進行任意一次抽樣,有68%的機率得到正負1個標準差之間的結果。」
有時候,統計課本會用另一種方式描述:「以母體平均為mu,母體標準差為sigma的常態分布而言,在平均數加減兩個sigma的這段區間中包含了95%的資料。」其實是一樣的意思。
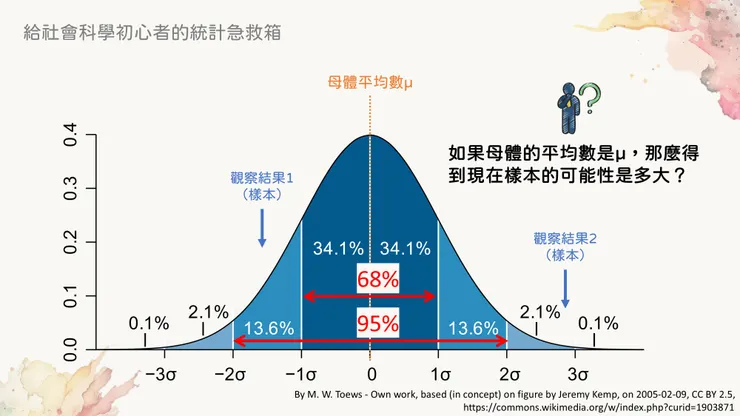
從常態分布曲線推估樣本發生的機率
現在來看觀察結果1的箭頭,我們要怎麼推估它的發生機率?方法是看它落在哪個區間之外、哪個區間之內。當觀察值(抽樣結果)落在某個區間之「外」的時候,它的發生機率是「小於」剩下的機率;當觀察值落在某個區間之「內」的時候,它的發生機率是「高於」剩下的機率。
所以觀察結果1落在68%的區間之外,也就代表它發生的機率小於剩下的32%。然而,它又落在95%的區間之內,代表它發生的機會比剩下的5%機率更高。
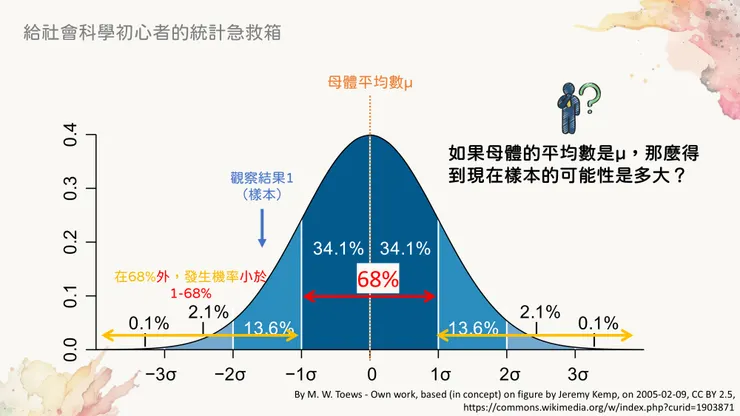
在68%範圍外,發生機率小於剩下的32%
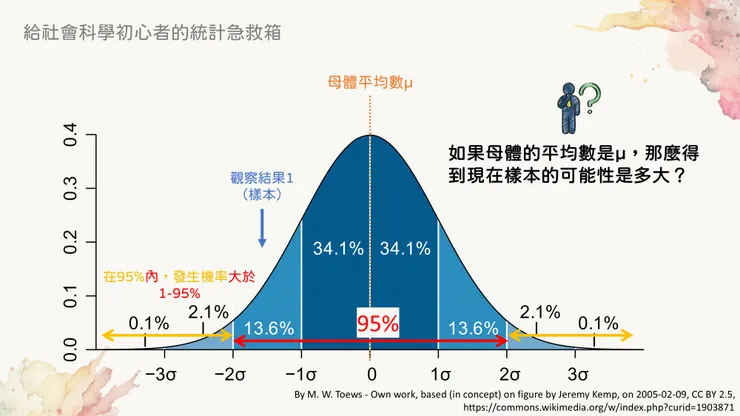
在95%範圍內,表示發生機率大於剩下的5%
因此,我們可以推估:「以母體平均數為mu,母體標準差為sigma畫出來的抽樣分布常態曲線,觀察結果1發生的機率介於5%到32%之間。」
這樣的過程可以告訴我們一個很重要的資訊,就是:「以假設的母體平均數和標準差畫出來的抽樣分布而言,我們有多高的機會得到我們這次的抽樣結果?」
在下一篇就會解釋要怎麼運用這個重要資訊來推論母體的平均數,也就是進行所謂的假設檢定囉!
方格子的專題被整合在沙龍裡面了,還不太會設定沙龍這個東西呢...不過專題本身還存在就好了。
致謝
本文所用圖片當中的素材來自於https://www.flaticon.com,由juicy_fish創作。


























