終於要開始講統計檢定的實作部分了。
其實我覺得之前我有點太急躁,先進入了t分數的概念介紹,現在又回來講Z分數的檢定操作順序不太對。為了讓順序比較恰當,這篇比較晚發的文章被設定成假設檢定後的下一篇。希望未來的人看到的時候,順序會比較正確一些。
這篇前面還是帶到了前面幾篇講過的觀念,所以滿長的。已經了解前面概念的人,可以直接跳到「用實際數值做一次假設檢定」的段落開始看。
複習:假設檢定怎麼看?
還記得之前解釋過假設檢定的基本邏輯,我們現在來複習一下:
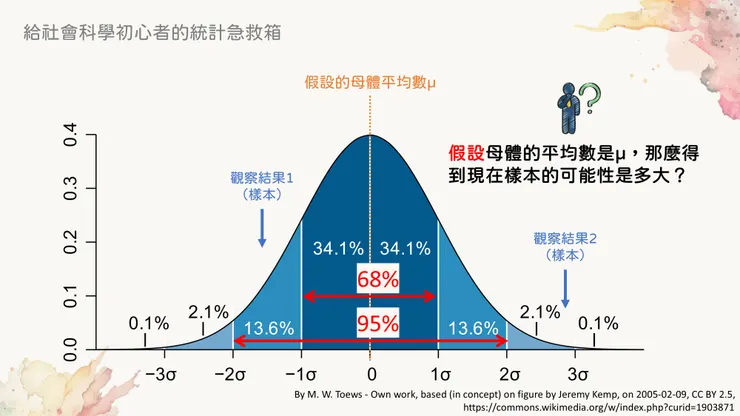
首先,我們知道常態分布曲線從中心往左右延伸各一個標準差,這個區間的數值發生機率為68%。如果延伸兩個標準差,這個區間的數值發生機率就是95%。如果忘記所謂的「這個區間的數值」實際上指的是什麼(其實就是X軸的值),可以回頭到統計急救箱─常態分布與假設檢定(上)裡面看喔。
所以現在我們應該知道怎麼解讀這兩張圖了:如果有一群資料的機率分布如同那個藍色面積的曲線(它正式的名字是──平均數為0且標準差為sigma的常態分布曲線),那麼我們得到觀察結果1的機率,應該介於68%到95%之間。
上面的原則說是說了,但怎麼好像還是聽不太懂...例如說那個觀察樣本的值(在X軸上的位置)到底是怎麼算出來的?或者那個68%的區間到底具體上是指哪裡到哪裡?可能會有這樣的困惑。
沒問題,我們就用實際的數值來看看吧!
用實際數值做一次假設檢定:找出臨界值 (CV)
首先,我們一定會從一群數值開始。假設現在我手上有五個人的某種資料...例如他們對自己工作滿意度的評分好了。這五個人的分數可以算出一個平均數,就是下面那橘色的人形。

好久不見這些小人了,平均數為-1,看起來他們不太喜歡自己的工作...
從這五個人身上得出一個平均分數,就如同之前介紹過抽球的例子一樣,像是從整體人群(一整袋球)之中抽出5個人(五顆球),並計算其平均分數。當我們重複做這件事情無數次之後,把每一次的結果畫成次數分配圖(或者機率圖),就會形成一個常態分配,我們稱之為抽樣分布。詳細的過程請見統計急救箱─抽樣分布與中央極限定理(二)。
在統計急救箱─抽樣分布與標準誤當中也有提到過,這種抽樣分布之所以很重要,原因就是:只要知道抽樣分布的平均數與標準差,我們就能計算觀察結果出現的機率。而根據假設檢定的概念,我們並不需要精確知道發生機率到底有多大,我們只要知道這個觀察結果發生的機率是不是很小,就能有比較充足的信心說:母體的平均是否和目前的觀測結果不同。詳細的邏輯推論過程,請見統計急救箱─常態分布與假設檢定(下)。
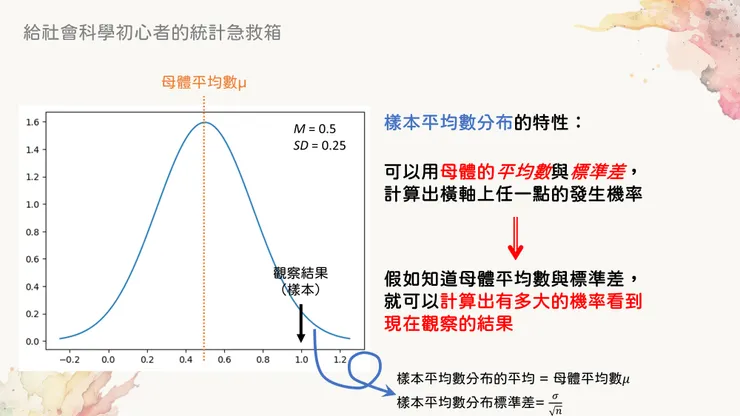
抽樣分布的平均數與標準差至關重要
而我們又已經知道當我們觀察得到的數值,也就是上面算出來工作滿意度的平均數,和「假設的」母體平均數之間有超過2個標準差的時候 (其實2個標準差只是近似值,後面會解釋),表示若假設為真,這個觀測出現的機率極小,因此假設的母體平均數不正確的機率較高,稱之為拒絕虛無假設。
那當我們知道母體平均數是多少,也知道抽樣分布的標準差是多少的時候,這個問題就簡單得很了。我們來看看下圖,這是一個母體平均為0.5,抽樣分布標準差為0.25的常態曲線:
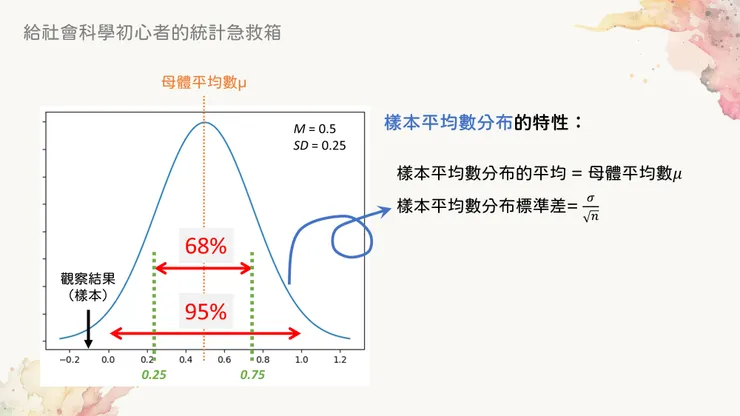
綠色線段所在的X軸位置,就是68%的臨界值
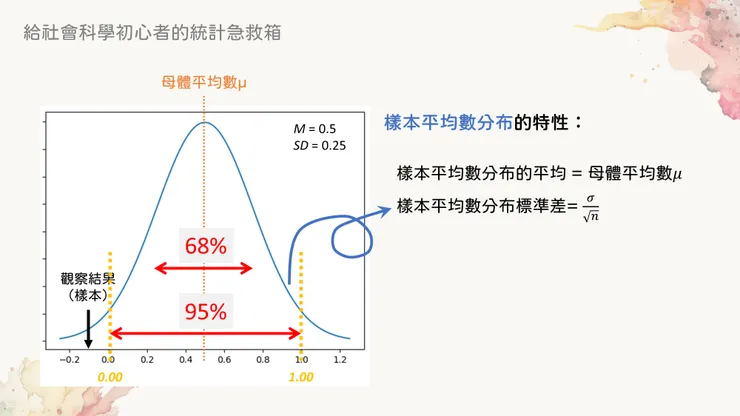
黃色線段則是95%的臨界值
可以非常簡單就算出,68%機率的區間應該是介於X軸上0.25~0.75的範圍之間,而95%機率則是介於0~1之間。這個區間的上下限,也就是上圖黃色虛線下方標記出的X軸數值,就是所謂的臨界值 (critical value, CV)。當超出這個臨界值的時候,我們就會知道如果虛無假設為真(也就是若母體平均為0.5),則觀察到目前結果的機率非常小(低於5%),因此推測母體平均不為0.5(拒絕虛無假設)。
如果覺得上面的這一串真的太拐彎抹角了,需要一個超級懶人包,那我只好整理出來(雖然不推薦用這種過於簡化的方式記憶):
超出95%臨界值 → 獲得顯著的結果 → 拒絕虛無假設
所以最開始那五個人,他們的工作滿意度平均數就顯著的小於0.5。假如他們都是同一個公司的員工,那我們就可以推論這間公司的員工,工作滿意度分數可能是低於0.5分的 [*1]。
每次臨界值都要重算嗎?使用常態Z分數就不煩惱
就像上面演示的一樣,一旦知道母體平均數和抽樣分布的標準差,那找出臨界值就是輕而易舉。只要把母體平均數加、減兩倍的標準差,就可以得到95%機率的臨界值啦~
不過呢,這樣面臨到了一個麻煩 [*2],那就是只要母體平均數和抽樣分布標準差不同(例如數學考試和英文考試有各自不同的母體平均和標準差),不就每次臨界值都要重算?超級無敵麻煩的啦!
不過...要解決「不同分數之間標準差和平均數不一致」這個困擾,好像在很~~~久之前曾經講過類似的事情。那就是把所有分數通通都轉換成「標準分數」就可以啦 (統計急救箱──標準分數),只不過公式長得跟之前有點不同:

抽樣分布的Z分數公式
不過這個公式實際上怎麼用來解決剛剛的問題呢?我們先來理解概念,然後代換成剛剛例子中的實際數值就會比較好理解了。
符號解析
先來看看右邊的符號們。要記得,上面用來做虛無假設檢定的分布是抽樣分布,所以公式中的x bar (就是x上面有一個槓槓的符號) 就是這次觀測所得到的平均數(也就是五個人的工作滿意度平均數:-1)。
mu則是母體平均數,這個應該不陌生了吧
分母的SDx bar則是指「抽樣分布的標準差」,如果想知道這符號到底是怎麼寫成這怪樣子的,我放在文末補充的地方。
而公式左邊,則表示這是「x平均數的Z分數」。這是當然的,因為我們就是要把平均數轉換成Z分數嘛。
實際計算
知道每個符號都代表什麼意思後,我們來實際代入數字可能就會讓一切更清楚了。在剛剛的例子裡面,這次的五人工作滿意度平均分數為-1,從上面圖中可以看到母體平均數為0.5,抽樣分布標準差為0.25。
那麼!這次這五人的工作滿意度平均數,其Z分數為多少呢?答案就是 (-1 - 0.5) / 0.25,最後結果是 -6 喔~
轉換成Z分數的目的
還記得我們為什麼要把平均數轉成Z分數嗎?因為我們不想要每次母體平均數和抽樣分布標準差一改變,就要重新計算一次臨界值嘛。
而Z分數可以解決這個困擾。事實上,這個Z分數有個比較特別的名字,它叫做「常態化Z分數」,特別加上一個常態化就是要強調這是由一個常態分布(也就是抽樣分布)轉換成的Z分數 [*3]。
那麼常態化Z分數的95%臨界值究竟是多少?答案是正負1.96 [*4]。也就是下圖中那個95%的紅色箭頭,其真正涵蓋的X軸範圍是-1.96 ~ +1.96這個區間。看起來指到2的位置只是因為1.96和2太接近了,圖上面看不出來。
95%的範圍不是-2到+2喔!
同樣的,一個非常簡化的懶人包會這樣說:
如果確定這個Z分數是常態的,只要觀測到的Z分數值超過1.96或小於-1.96,就可以拒絕虛無假設。
上面這個過程,也就是所謂的Z檢定囉!
檢定結果
那麼,上面那五個人的工作滿意度平均分數 (-1),在Z檢定裡面有沒有顯著的小於0.5呢?
因為我們剛剛算出來,他們工作滿意度的平均分數轉換為Z分數是-6。那-6有沒有小於-1.96?不只有,而且還差很多。這時候我們就會在統計報告裡面寫下面這段話:
Z檢定結果顯示工作滿意度分數顯著小於0.5,Z = -6.0, p < .05。
怎麼突然冒出那個p < .05啊?其實這個翻成中文的意思就是「機率 (p) 小於5% (0.05)」的意思。這5%怎麼來的呢?如果不知道的話可以參考統計急救箱─常態分布與假設檢定(下)的說明喔。
手上的專案應該快要上軌道了,希望能夠增加更新的頻率。
註解
[*1]: 其實不能這樣推論,因為五個人樣本實在太少了。這裡只是演示一下整個實作過程。
[*2]: 如果好奇為什麼「不知道母體平均和抽樣分布標準差是多少」不算是個麻煩,那只是因為這是下一篇的主題,而我不想在這裡破梗。
[*3]: 既然有常態化Z分數,就表示有非常態化的Z分數嗎?沒錯。事實上Z分數不會改變分布的長相,所以所謂的常態Z分數,就表示原本的分布就是常態的。那麼當然如果原本的分布不是常態的,轉成Z分數也不會是常態的囉~
[*4]: 正負1.96是常態Z分數的雙尾檢定95%臨界值 (如果比較不精準一點,就會進位變成2,這也是為什麼前面會用2來示範計算臨界值的原因),雙尾檢定是社會科學裡面比較常用到的檢定。而至於單尾檢定,這個急救箱暫時沒有打算解釋那是什麼,但網路上應該有非常多資料可以參考。
補充
為什麼那個公式分母的SD旁邊的小足標要用x bar而不是x呢?這是因為「抽樣分布是由無數個x bar所組成的分布」。也就是說,組成抽樣分布的最小單位是x bar而不是x,所以要計算這個分布的標準差的時候,在足標加上x bar就是告訴讀者說:嘿!這個標準差是從x bar組成的分布得到的,而不是從x組成的分布所得到的喔!
如果上面這段看不懂也沒關係,因為這是比較抽象的解釋。繼續接觸統計的話,有天就會像是頓悟一般的懂了,至少我以前是這樣的。
致謝
本文所用圖片當中的素材來自於https://www.flaticon.com,由juicy_fish創作。