Google已經是現代人疑難雜症的好幫手,任何事情都能在網路上找到答案,對於入門NLP這件事也是,如果在GOOGLE搜尋”NLP入門”相關的關鍵字,檢索回來的結果大概可以分成兩種,一種是羅列各種NLP技能樹文章介紹,另一種則是介紹NLP書籍,不管是哪一種看到的都是彷彿學不完的知識,瞬間澆熄初學者想入門的熱情,主要原因是我們可以支配的空閑時間不夠用。
因為時間不夠,所以更要了解適合自己的入門方法
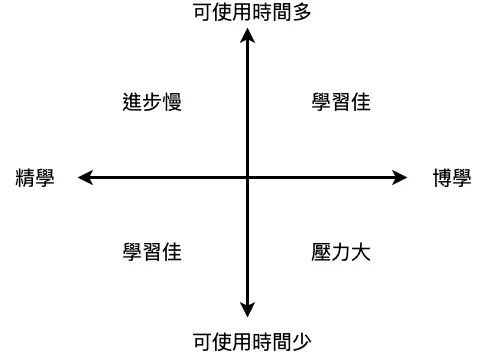
如果我們把學習量和可支配空閑時間兩個維度交叉來看如下圖,可以發現當要學習的知識量較大時需要更多時間來消化,通常是學生角色才比較符合這些條件,而一般朝九晚五上班族可支配空閑時間是相對大幅減少的,尤其是有家庭需要照顧的下班後幾乎沒有空閑時間,所以要將NLP技能樹全部點過一次是不切實際的。
既然全部都學學不完,那就隨便選一項有興趣的技能來學吧?
選擇一項看起來有興趣的來切入學習或許也不失為一種好方法,我們常說AI是透過模仿人類的學習行為來學習新事物,在訓練AI模型的方法中,確實有一種就是回饋式學習,具體作法是一開始會讓模型胡亂預測,再由預測結果正確與否回饋給模型,藉由回饋修正模型預測規則來提升準確率,當練習的資料量夠多,模型就能夠收斂到一定的準度。
回到選擇學習技能這件事上,或許我們也能借鏡AI學習法,選擇一項子領域深入研究,在練習過程中自然會遇到需要解決的問題或他人回饋而習得額外的知識,最終提升到能夠在該領域獨立解決問題的能力。
還有其他的選擇方向嗎?
除了選擇一樣有興趣的子領域來學,還有方向可以更簡單的入門嗎,我想可以從學NLP的目的來得到解答,一般來說學習一個技能不外乎是想要用來解決工作上或生活上其他問題,因此如果在練習過程中就能夠學到最有價值、廣泛實用的知識,就不用繞遠路也能夠持續保有熱情學習。
因此我們可以把選擇技能問題轉化為優先學習泛用性高的技能就可以做到現學現賣,除了強化NLP跨領域知識,也能立即提升工作上的生產力。
如果要說明NLP領域廣泛實用的技能,那我想第一個應該是爬蟲,再來是資料探索,最後是語言模型。
資料爬蟲
如果AI模型是身體,那資料應該是身體裡的血液,沒有了血液身體也無法運作,所以一般在入門AI領域時,最先學習的就是資料檢索也就是爬蟲。尤其在資訊爆炸的世代裡,能夠用有邏輯、自動化方式擷取出我們想要的資料是很重要的事情,不僅限文本的爬蟲,包括圖片、影音都是。
資料探索
資料探索是一種透過資料整理方式來認識資料本身的過程,具體的手段有統計、資料視覺化檢視資料分佈,並實際檢查資料內容,釐清問題本身可否透過資料來得到解答,有利於後續的資料分析和建模,但因為過程冗長經常被跳過,不過卻是建模前的重要前哨站。
模型常被當作黑盒子存在且無法解釋預測結果,也比較難以除錯,而資料探索能夠得到更貼近生活語言的解釋,在一些場域中可解釋知識甚至價值更高,像是醫療領域,因為無法解釋的預測不只醫生不敢採納,病人也不會相信。
練習資料探索技巧除了能以各種角度了解資料各種變數關聯之外,學習透過資料來解惑其他人的問題也更有說服力。
語言建模
語言模型子領域有非常多種,在入門中可以從比較簡單常用的應用下手,像是文本分類、輿情分析、文本自動摘要、關鍵字擷取任務。
在具體操作上可以從使用開源軟體並選擇非深度學習模型入門,這個階段是體驗模型實際運用流程,了解資料輸入格式和模型輸出格式,所以可以先以範例文本訓練,並觀察實際輸出的內容是否接近預期的結果,再將訓練資料替換成實際的訓練資料重新訓練,再觀察一次輸出結果是否接近問題的答案。
通常沒有精調的模型準確度會偏低,後續就需要了解演算法內容,並調整合理的參數讓模型更好的學習直到收斂。
NLP領域雖然有看似學不完的技術,但只要根據適合自己的準則來拆解,就能找到能夠持續往前推進的道路,希望這篇能讓你有不一樣的思維方式來踏入NLP。























