在資料科學中常可以聽到「權重」,可藉由專家經驗和機器學習取得「權重」,但他們差別是什麼?在透過演算法決定權重的想法相對盛行的現今,又如何整合兩種途徑的結果?
內容
- 定義
- 取得權重的兩種途徑
- 取得權重後做什麼?
- 現況與建議
- 結論
- 最後
定義
權重是指,不同測量指標對於目標變數的相對重要程度。比方說,在大學不同科系的錄取資格,要求:
總成績 = 1*國文 + 1.5*英文 + 1*數學
表示該科系對於學科能力的重視程度,相對而言,英文是國文和數學的1.5倍,也就是說該科系相對重視學生英文能力。
又或者是:
個人收入 = 1.2*教育年數 + 3.6*工作年資 + 4.8*所屬產業別
表示個人的收入,受到個人的教育年數、年資和所屬產業別影響,而其中又以所屬產業別相對重要於和工作年資和教育年數。
也就是說,對於目標變數而言,我們知道不同的測量指標的重要性不同;然而,相對重要性如何決定?有什麼科學化的方法可以採用嗎?
取得權重的兩種途徑
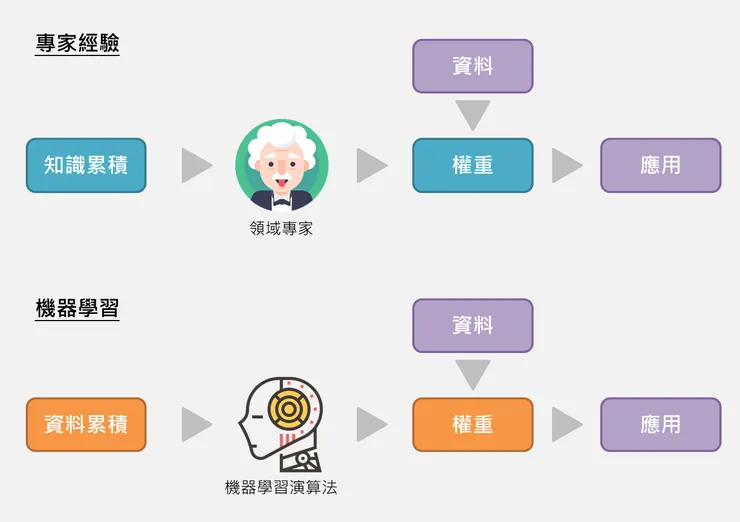
專家經驗
透過大量的經驗累積,取得專業領域知識的人,藉由這些專家的知識,針對目標的看法,給予不同指標的相對重要性。如同前面的例子,學校科系對於學生的錄取標準,即是透過各科系的教職員討論決定出英文的權重為1.5、數學和國文的權重為1等。又或者,假設要知道入境旅客走私的風險高低,海關官員可能依照專業經驗,給定「從A、B、C國家出境」的風險權重為4.5,「從D、E國家出境」的風險權重為2.1,「出入境次數」的風險權重為1.3,則表示從A、B、C國家出境的旅客,相對於從D、E國家出境的旅客風險高;而出入境次數越多,可能的風險也越高。
專家經驗倚賴專家長時間的經驗累積,以此做為給定權重的基礎,進行可能的篩選機制、風險判斷等。而當需要整合多個專家的意見時,透過「會議討論」是一種做法;然而,相對科學的方式是透過例如層級分析法(Analytic Hierarchical Process,AHP),設計成對比較(pairwise comparision)問卷給予專家填寫後,透過特徵向量分解(eigenvector decomposition)後,取得最大特徵值(eigenvalue)對應特徵向量(eigenvector),作為最終的專家權重,也是常見方法之一。
然而,專家經驗的限制在於需要長時間的專家知識累積,當專家離開組織後,必須有對應的知識接班,例如許多組織建立知識管理(knowledge management)系統即試著藉此留下專家經驗,但往往知識管理系統淪為檔案集散地,真正的專家經驗可能也只留存在下一代專家的腦海中。
機器學習方法
專家經驗倚賴專家的知識累積;相對的,機器學習方法則是倚賴資料的累積,並結合機器學習演算法(machine learning algorithm),從中取得權重,例如常見的決策樹(decision tree)、多元線性迴歸(multiple linear regression)、類神經網絡(artificial neural network)等,由資料中學習所需要的權重。
例如研究蒐集到約1,600人的個人收入、父母教育年數、個人教育程度和年數、工作地、性別等資料,進一步針對這1,600筆的資料,結合多元線性迴歸,即可知道當教育年數每增加1年時對於個人收入的增加2,800元,而女性收入相對於男性的較低(-11,800)等結果。
當然,機器學習方法也有限制,包含是否有足夠的歷史資料累積,以及是否有好的資料品質。當無足夠高品質的資料,機器難以從有限或品質不佳的資料中取得有用的規則,遑論進行好的推論或預測應用。此外,機器學習往往需要外尋機器學習專家協助建立權重和系統,短期成本相對於專家經驗高。
整體而言,專家經驗和機器學習方法取得權重的方式不同,專家經驗仰仗知識累積而成的領域專家給予權重,而機器學習方法則是依靠資料累積結合演算法取得權重,且各自有其限制。
取得權重後做什麼?
實務上透過上述不同方法,都可以各自取得權重。而在取得權重後,應用方式則視不同情境而定。
例如決定錄取的學生時,透過學生的考試成績,結合權重大小篩選相對符合能力要求的學生;海關於收到旅客入境資料時,結合旅客資料和權重大小,計算整體風險分數,進一步查驗高風險旅客的入境身分;銀行於收到借款申請時,結合申請人資料和權重大小,決定借款與否,甚至是借款金額大小。
簡單的說,就是透過實務資料結合預先取得的權重,輔助業務需求判斷行動方案。
現況與建議
取得權重的方式有兩大途徑,但計算方法相當多元,那麼現況為何呢?在人工智慧當道,對於透過演算法決定權重的想法相對盛行;不過在許多產業中,採行多年的專家經驗無法一夕之間轉換為機器學習方法,原因在於機器學習所需要的大量資料並無留存歷史紀錄,或是既有系統無法直接與機器學習方法整合,而需要額外系統調整或建置成本,都使得機器學習方法的應用雖有成長,但並非爆發性。因此,我建議的方式是,著手數位轉型(digital transformation)、建立資料倉儲(data warehouse)妥善保存相關紀錄以解決無歷史紀錄的部分;此外,藉由專家輔助標註資料(data labeling),以此作為機器學習的基礎,透過資料學習「專家經驗」,輔助實務應用。
結論
權重的應用廣泛,而權重的取得有兩大途徑,分別是專家經驗和機器學習方法。專家經驗倚賴知識累積,機器學習方法憑藉資料累積。著手數位轉型、建立資料倉儲、結合專家經驗和機器學習方法,是機器學習方法應用的拓展方向之一。
最後
你了解權重有哪些取得途徑嗎?或是除了本文所提到的,有其他的想法?都歡迎留言和我分享。


























