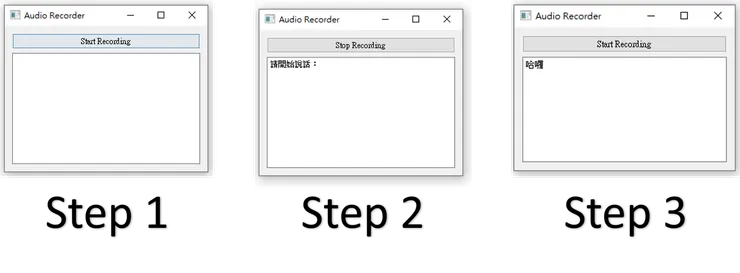
本文主要使用SpeechRecognition來做一個簡單的語音辨識,使用pyqt5介面呈現。
- 按下Start Recording,開始錄音,並顯示請開始說話。然後按鈕名改名Stop
- 在按下Stop Recording,稍等片刻後就會呈現出辨識結果
程式範例
import sys
import speech_recognition as sr
from PyQt5.QtWidgets import QApplication, QWidget, QPushButton, QTextEdit, QVBoxLayout
from PyQt5.QtCore import Qt
import threading
class AudioRecorder(QWidget):
def __init__(self):
super().__init__()
self.initUI()
self.recording = False
self.recognizer = sr.Recognizer()
self.audio = None
self.thread = None
def initUI(self):
self.setGeometry(300, 300, 300, 200)
self.setWindowTitle('Audio Recorder')
layout = QVBoxLayout()
self.start_button = QPushButton('Start Recording')
self.start_button.clicked.connect(self.toggle_recording)
layout.addWidget(self.start_button)
self.text_area = QTextEdit()
self.text_area.setReadOnly(True)
layout.addWidget(self.text_area)
self.setLayout(layout)
def toggle_recording(self):
if self.recording:
self.stop_recording()
else:
self.start_recording()
def start_recording(self):
self.recording = True
self.start_button.setText('Stop Recording')
self.text_area.setText("請開始說話:")
self.thread = threading.Thread(target=self.record_audio)
self.thread.start()
def stop_recording(self):
self.recording = False
self.start_button.setText('Start Recording')
if self.thread:
self.thread.join()
self.recognize_audio()
def record_audio(self):
microphone = sr.Microphone()
with microphone as source:
self.recognizer.adjust_for_ambient_noise(source)
self.audio = self.recognizer.listen(source)
def recognize_audio(self):
try:
text = self.recognizer.recognize_google(self.audio, language='zh-tw')
self.text_area.setText(text)
except sr.UnknownValueError:
self.text_area.setText("無法辨識音訊")
except sr.RequestError as e:
self.text_area.setText(f"無法連接到Google服務;{e}")
def closeEvent(self, event):
if self.recording:
self.stop_recording()
event.accept()
if __name__ == '__main__':
app = QApplication(sys.argv)
ex = AudioRecorder()
ex.show()
sys.exit(app.exec_())
程式碼重點說明
定義 AudioRecorder 類別
class AudioRecorder(QWidget):
def __init__(self):
super().__init__()
self.initUI()
self.recording = False
self.recognizer = sr.Recognizer()
self.audio = None
self.thread = None
__init__方法:初始化類別。這裡設置了一些初始狀態,如錄音狀態、語音辨識器和音頻數據。
錄音和停止錄音的邏輯
def toggle_recording(self):
if self.recording:
self.stop_recording()
else:
self.start_recording()
def start_recording(self):
self.recording = True
self.start_button.setText('Stop Recording')
self.text_area.setText("請開始說話:")
self.thread = threading.Thread(target=self.record_audio)
self.thread.start()
def stop_recording(self):
self.recording = False
self.start_button.setText('Start Recording')
if self.thread:
self.thread.join()
self.recognize_audio()
toggle_recording:根據當前錄音狀態切換開始或停止錄音。start_recording:開始錄音,將按鈕文本設為 "Stop Recording",並啟動新執行緒來錄製音頻。stop_recording:停止錄音,將按鈕文本設為 "Start Recording",並在執行緒結束後進行語音辨識。
錄製音頻和語音辨識
def record_audio(self):
microphone = sr.Microphone()
with microphone as source:
self.recognizer.adjust_for_ambient_noise(source)
self.audio = self.recognizer.listen(source)
def recognize_audio(self):
try:
text = self.recognizer.recognize_google(self.audio, language='zh-tw')
self.text_area.setText(text)
except sr.UnknownValueError:
self.text_area.setText("無法辨識音訊")
except sr.RequestError as e:
self.text_area.setText(f"無法連接到Google服務;{e}")
record_audio:使用speech_recognition庫來錄製音頻。這裡使用了Microphone來捕捉音頻,並調整麥克風的背景噪音。recognize_audio:使用 Google 語音辨識服務將錄製的音頻轉換為文字,並顯示在文本區域。如果辨識失敗,則顯示錯誤信息。
視窗關閉事件
def closeEvent(self, event):
if self.recording:
self.stop_recording()
event.accept()
closeEvent方法:在關閉窗口時,如果仍在錄音,則停止錄音,然後接受關閉事件。





















