探索性因素分析 (Exploratory Factor Analysis, EFA) 是一種統計學方法,用於識別隱藏在一組變量中的因素(或潛在結構)。它通常用於對調查問卷或其他測量工具進行數據分析,以確定測量工具中的主要維度。EFA通過對變量之間的相關性進行分析來識別隱藏的因素,並使用因子載荷矩陣來確定變量與每個因素的相關性。
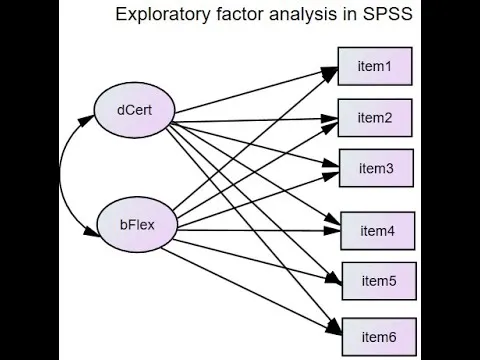
EFA的假設
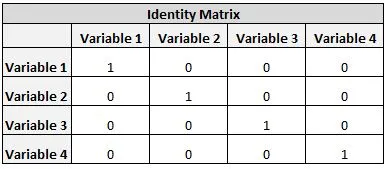
Bartlett球面性考驗(Bartlett test of sphericity): 統計考驗, 需達.05顯著水準(拒絕H0,H0假設你的數據矩陣是identity matrix,如下圖),表示我們的數據矩陣不是identity matrix,題目選項之間有相關。
•KMO (Kaiser-Meyer-Olkin measure of sampling adequacy ): 公式如下圖。數值介於1~0之間。越大表示試題間相關的程度高,但淨相關小,其代表有另一個因素可以解釋兩題之間關連程度的很大部分。最好不要低於.60。KMO值越高代表資料適合進行因素分析

樣本數量要求
探索性因素分析 (EFA) 是一種用於識別一組變量中的潛在因素或結構的方法。 有幾個因素會影響 EFA 所需的樣本量,例如,觀察變量(題目)的數量:分析中包含的變量越多,所需的樣本量就越大;因子數:提取的因子越多,需要的樣本量越大。一般而言,建議 EFA 的樣本量至少為 100,推薦200或以上,儘管這可能因分析的具體情況而異。 然而,需要注意的是,擁有更大的樣本量並不能保證結果的穩健性,數據的基本假設(例如資料呈現常態分佈、題目以及估計方法的適當性)也起著至關重要的作用。



















