我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
Transformer 中的 Attention 機制是 'Word-to-Word' 操作,或者是 'Token-to-Token' 操作,白話來講就是:「對於句子中的每個字,要去分析它和別的字之間的關係,這分析也包含自己這個字對自己本身的分析」
用圖示化來說明就是:
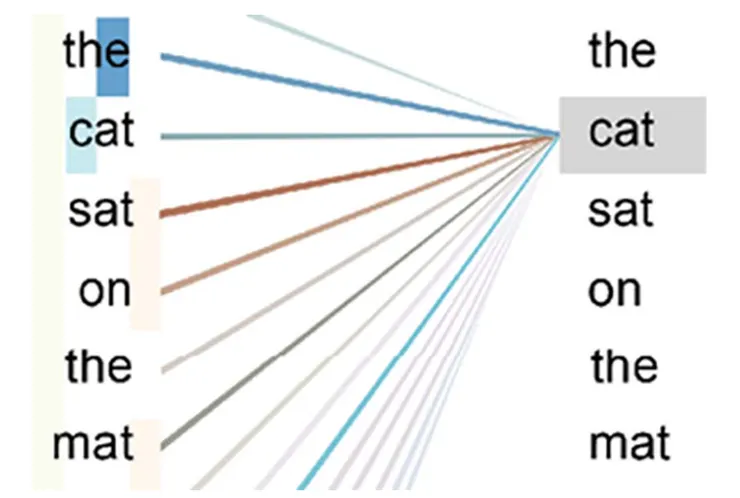
出自書籍:Transformers for Natural Language Processing and Computer Vision - Third Edition, Denis Rothman, 2024
Attention 機制會執行:「Dot products between word vectors and determine the strongest relationships between a given word and all the other words, including itself」
事實上 Transformer 模型不是一次執行一個 Attention 機制,而是一次八個,這有以下好處:
- 可以更深層的分析文字序列
- 施行平行計算
- 每一個 Attention 機制都能各自捕捉輸入序列的不同層面意涵


















