我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
再度回到 Transformer 架構中的 Encoder 部分,如下圖所示:
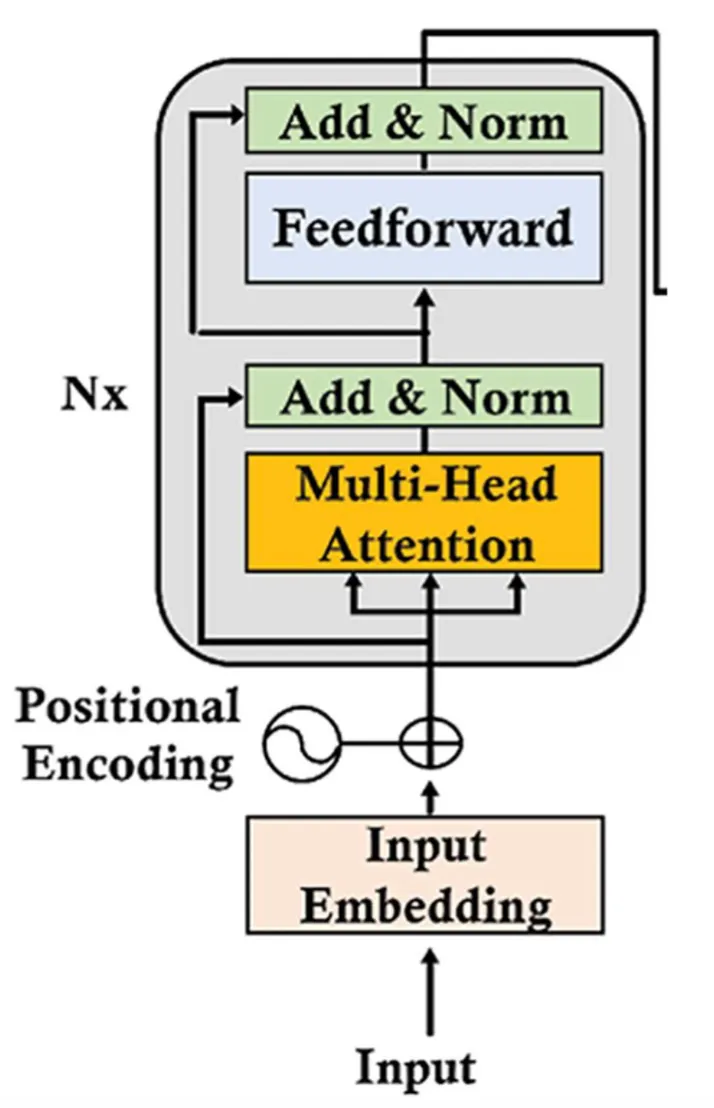
我現在手上有的素材如下:
- Embedding 訓練方式:AI說書 - 從0開始 - 43
- Embedding 結果呈現:AI說書 - 從0開始 - 44
- Positional Encoding 功能介紹:AI說書 - 從0開始 - 45
- Positional Encoding 畫圖感受:AI說書 - 從0開始 - 46
- Positional Encoding 實際計算:AI說書 - 從0開始 - 47
- Embedding 與 Positional Encoding 的相似度比較:AI說書 - 從0開始 - 48
現在我們準備把既有的素材合在一起,目前我手上有每個字的 Input Embedding 與 Positional Encoding,每個字都有這兩項素材,且它們都是維度為 512 的向量,依據原始 Google 發表的 Transformer 論文,合起來的步驟是這樣的:
- 每個字的 Input Embedding 向量乘上 (512開根號 )
- 上述結果拿來跟每個字的 Positional Encoding 相加
- 注意因為兩者維度都是 512 ,所以向量可以相加,此外每個字都要重複上述步驟
至於為什麼要乘上 (512開根號) 呢,這和 Embedding 在訓練的時候,內部神經網路的初始權重配置有關係,為了避免訓練不穩定,通常會給每個權重的變異數加以限制,也因為這樣的配置,在神經網路訓練好之後,要再把它調整回來,那根號的原因和變異數有平方的概念相抵銷,整體的數學邏輯可以參照:


















