我想要一天分享一點「LLM從底層堆疊的技術」,並且每篇文章長度控制在三分鐘以內,讓大家不會壓力太大,但是又能夠每天成長一點。
整理目前手上有的素材:
- AI說書 - 從0開始 - 338 | Embedding Based Search 資料集描述
- AI說書 - 從0開始 - 339 | Embedding Based Search 資料集整備
- AI說書 - 從0開始 - 340 | Embedding Based Search 資料集編碼
- AI說書 - 從0開始 - 341 | Embedding Based Search 執行 Embedding 並儲存
- AI說書 - 從0開始 - 342 | Embedding Based Search 資料清洗
- AI說書 - 從0開始 - 343 | Embedding Based Search 之 K-Means 群集
- AI說書 - 從0開始 - 344 | Embedding Based Search 之 t-SNE 降維
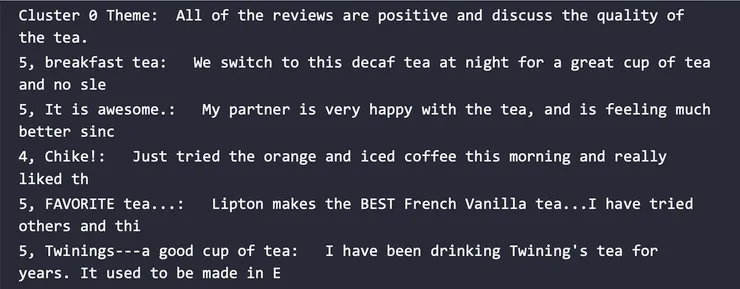
既然完成 K-Means 群聚與 t-SNE 降維,我想從每一個群集中,各挑出五筆資料,並匯入 Davinci-002 模型中,看是否有共通性,如此來檢視群聚效能:
rev_per_cluster = 5
for i in range(n_clusters):
print(f"Cluster {i} Theme:", end = " ")
reviews = "\n".join(df[df.Cluster == i].combined.str.replace("Title: ", "")
.str.replace("\n\nContent: ", ": ")
.sample(rev_per_cluster, random_state = 42)
.values)
response = openai.Completion.create(engine = "davinci-002",
prompt = f'What do the following customer reviews have in common?\n\nCustomer reviews:\n"""\n{reviews}\n"""\n\nTheme:',
temperature = 0,
max_tokens = 64,
top_p = 1,
frequency_penalty = 0,
presence_penalty = 0)
print(response["choices"][0]["text"].replace("\n", ""))
sample_cluster_rows = df[df.Cluster == i].sample(rev_per_cluster, random_state = 42)
for j in range(rev_per_cluster):
print(sample_cluster_rows.Score.values[j], end = ", ")
print(sample_cluster_rows.Summary.values[j], end = ": ")
print(sample_cluster_rows.Text.str[:70].values[j])
print("-" * 100)
結果為: